






本文来源公众号“江大白”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/AKxi4hXyJS0bIVYvun4Hfg
导读
RF-DETR和YOLOv12等新模型在保持高性能的同时实现了前所未有的精度,在2025年顶流目标检测模型中RF-DETR也脱颖而出。本文将详细分析了这些最先进的目标检测模型,并介绍如何在不同硬件平台上高效部署它们。
引言

最佳目标检测模型
目标检测技术为无数现实世界中的无数应用提供支持,从自动驾驶汽车在城市街道导航到智能工厂监控生产线。随着Transformer架构和注意力机制的快速发展,2025年的最先进目标检测领域发生了巨大变革。RF-DETR和YOLOv12等新型模型不断突破极限,在保持实时性能的同时实现了前所未有的精度。
本文将探讨当前最优的目标检测模型,从Roboflow的突破性模型RF-DETR到最新的YOLO迭代版本,并展示如何在各种硬件平台上高效部署这些模型。
模型评选标准
以下是评选这些目标检测模型时所采用的标准。
1. 实时性能
模型应具备适合实时应用的推理速度,通常在NVIDIA T4等标准GPU硬件或边缘设备上能达到30+ FPS的图像处理速度。这确保模型能够处理视频流和时间敏感的检测任务,且不会产生明显延迟。
2. 标准基准测试精度
模型应在行业标准基准测试中表现优异,尤其是在Microsoft COCO数据集上。我们优先考虑在IoU 0.50:0.95条件下达到至少45% mAP(平均精度均值)的模型,这表明模型在各种目标尺度和类别上都能实现可靠检测。
3. 模型效率与可扩展性
模型架构应提供多种尺寸(微型、小型、中型、大型),以适应不同的计算预算。高效的模型需在参数数量、FLOPs和精度之间取得平衡,使其能够部署在从边缘硬件到云基础设施的各类设备上。
4. 领域适应性
强大的预训练模型应能很好地迁移到自定义数据集和特定领域。我们倾向于那些在RF100-VL等领域自适应基准测试中表现稳定的架构,这表明它们能够超越训练数据进行泛化。
5. 活跃的开发与部署支持
优先考虑具有强大社区支持、定期更新和生产级部署工具的模型。与Roboflow Inference、Ultralytics或原生PyTorch等框架的集成,确保从业者能够顺利从实验过渡到生产环境。
最佳目标检测模型
以下是2025年最佳目标检测模型列表。
1. RF-DETR
图片
RF-DETR是Roboflow开发的实时Transformer-based目标检测模型架构,于2025年3月以Apache 2.0许可证发布。作为首个在RF100-VL领域自适应基准测试中mAP超过60的实时模型,RF-DETR在各种真实世界数据集上也实现了最先进的性能,具有里程碑意义。
RF-DETR的出色之处在于其采用了DINOv2视觉骨干网络,该网络提供了卓越的迁移学习能力。该模型从设计之初就注重在不同领域和数据集规模上的适应性,使其既适用于通用检测,也适用于专业应用。
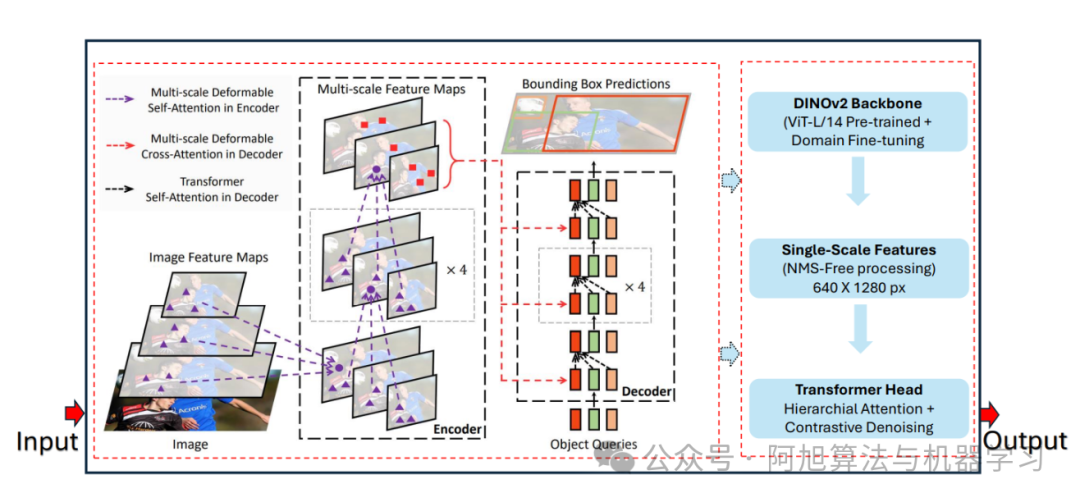
图片
上图展示了RF-DETR组件的详细架构:DINOv2骨干网络、带可变形注意力的Transformer编码器,以及带基于查询的检测头的解码器。该图说明了RF-DETR如何通过端到端的Transformer架构消除非极大值抑制(NMS)和锚框。流程为:输入图像→骨干网络特征提取→编码器处理→解码器预测→最终检测结果。
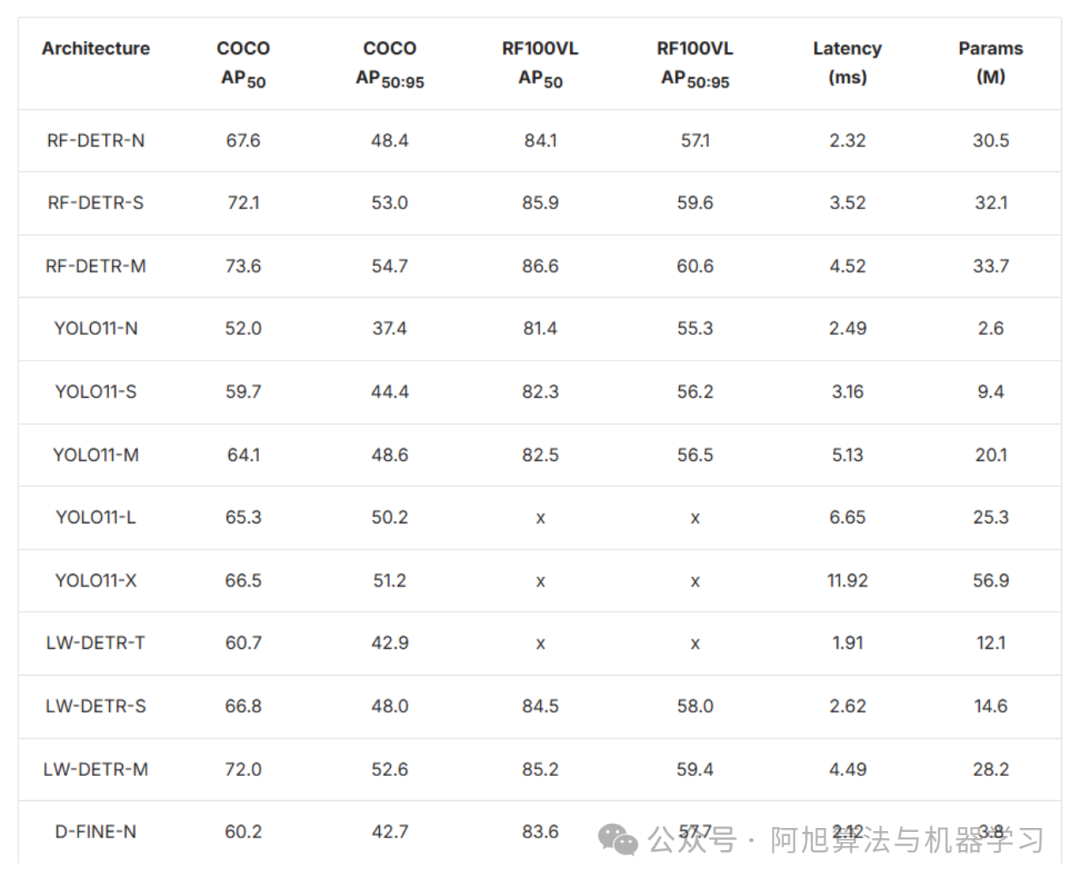
RF-DETR提供多种变体以适应不同的部署场景。微型、小型和中型模型具有出色的精度-速度比,而预览分割变体则将功能扩展到实例分割任务。RF-DETR-M在T4 GPU上实现54.7% mAP,延迟仅为4.52ms,在保持实时速度的同时性能优于同类YOLO模型。
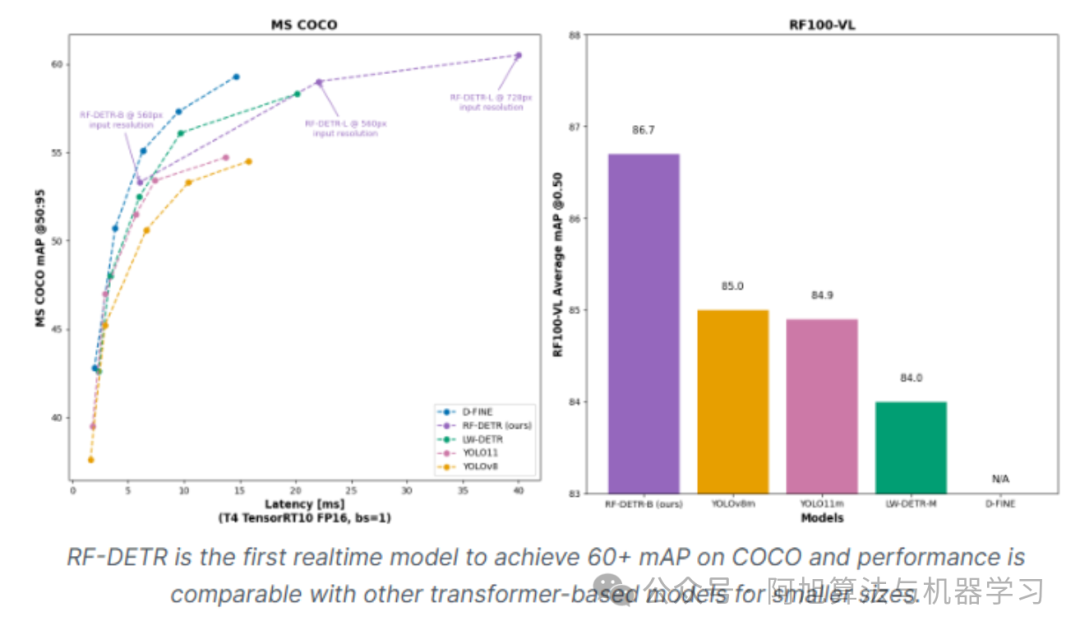
RF-DETR基准测试性能:
图片
上图是性能对比图表,展示了RF-DETR与YOLOv11、YOLOv8等实时检测器在COCO mAP与延迟方面的表现。RF-DETR变体(N/S/M)形成帕累托前沿,展示了在精度和速度之间的卓越权衡。特别是RF-DETR-M,在仅略微增加延迟的情况下实现了更高的mAP,凸显了其在平衡精度和实时性能方面的效率。此外,RF100-VL的mAP达到60.6%,表明其在不同视觉环境中具有出色的领域适应性和稳健性,在精度和泛化能力上超过了许多传统的CNN和Transformer-based检测器。
该模型的Transformer架构消除了锚框和非极大值抑制(NMS)等传统检测组件,实现了真正的端到端目标检测。这种架构选择不仅简化了检测流程,还提高了一致性并减少了后处理开销。
RF-DETR体积小巧,可通过Roboflow Inference在边缘设备上运行,非常适合需要高精度和实时性能且无云依赖的部署场景。
2. YOLOv12
YOLOv12于2025年2月发布,通过引入以注意力为中心的架构,成为YOLO系列的重要转折点。YOLOv12不再仅依赖卷积操作,而是集成了高效的注意力机制来捕获全局上下文,同时保持了YOLO系列闻名的实时速度。
该模型引入了多项突破性组件,包括区域注意力模块(A²)——通过将特征图划分为特定区域来优化注意力以提高计算效率,以及残差高效层聚合网络(R-ELAN)——通过块级残差连接增强训练稳定性。FlashAttention的集成进一步减少了内存瓶颈,全面提高了推理效率。
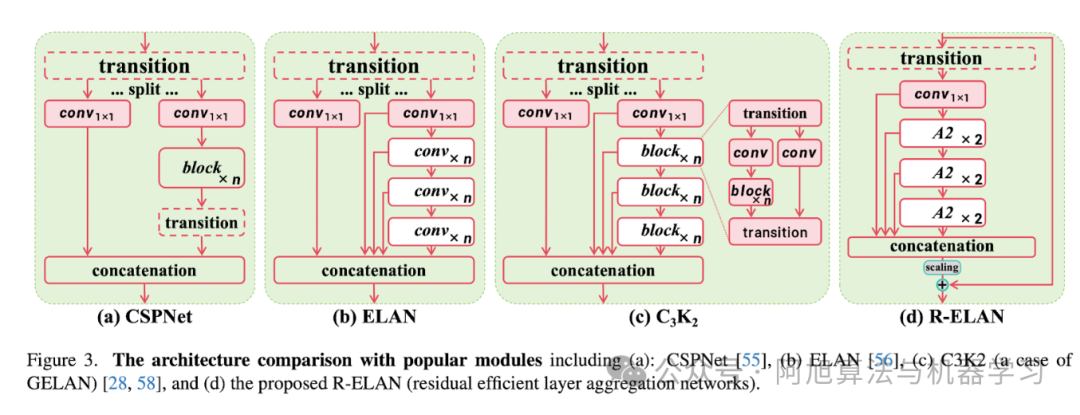
图片
上图可参考此处:
YOLOv12基准测试性能:
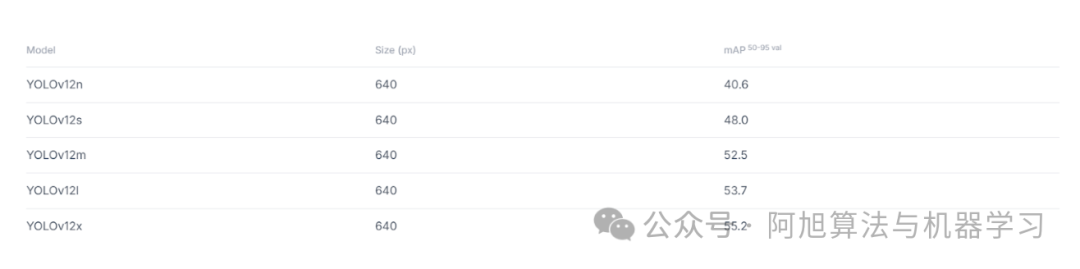
图片
-
YOLOv12-N:40.6% mAP,延迟1.64ms(比YOLOv10-N高2.1%,比YOLO11-N高1.2%)
-
YOLOv12-M:52.5% mAP,延迟4.86ms(比YOLO11-M高1.0%)
-
YOLOv12-X:55.2% mAP,延迟11.79ms,是YOLO系列中精度最高的模型
在深入了解YOLOv12的创新之前,值得一提其前代模型的贡献。
图片
-
YOLO11(2024年10月发布)优化了架构设计,与YOLOv8m相比参数减少22%,同时通过增强特征提取和优化训练流程实现了更高的mAP。
-
YOLOv10(2024年5月)采用一致的双重分配策略,开创了无NMS训练方法,显著降低了推理延迟。
-
YOLOv9(2024年2月)引入可编程梯度信息(PGI)和GELAN架构,解决了深度网络中的信息丢失问题,同时提高了精度和效率。
-
YOLOv8(2023年1月)采用无锚框方法和增强的CSPNet骨干网络,成为支持全面任务的最广泛采用的框架之一。
其代价是YOLOv12模型的运行速度略慢于其直接前代模型:YOLOv12-N比YOLOv10-N慢9%,YOLOv12-M比YOLO11-M慢3%。然而,对于检测质量至关重要的应用,精度的提升使其物有所值。
YOLOv12由Ultralytics Python包支持,只需几行代码即可进行训练、推理和部署,对初学者和专业人士都很易用。
3. YOLO-NAS
图片
YOLO-NAS由Deci AI开发,于2023年5月发布,通过应用神经架构搜索(NAS)技术在目标检测领域取得突破。YOLO-NAS并非手动设计架构,而是通过Deci的AutoNAC(自动化神经架构构建)引擎发现的,该引擎在3800 GPU小时内探索了10^14个潜在架构的巨大搜索空间。
YOLO-NAS的关键创新在于其 quantization友好的架构。大多数模型在量化为INT8以实现更快推理时会出现显著的精度下降,而YOLO-NAS从设计之初就考虑了量化。其量化感知块在INT8转换过程中最大限度地减少了精度损失,使模型在保持性能的同时实现了更高的效率。
YOLO-NAS通过复杂的训练方案解决了前代YOLO模型的关键局限性,包括在Objects365数据集(365个类别,200万张图像)上预训练、利用COCO伪标签图像,以及结合分布焦点损失(DFL)进行知识蒸馏。这种全面的训练方法帮助模型处理类别不平衡问题,并提高了对代表性不足类别的检测精度。
YOLO-NAS性能指标:
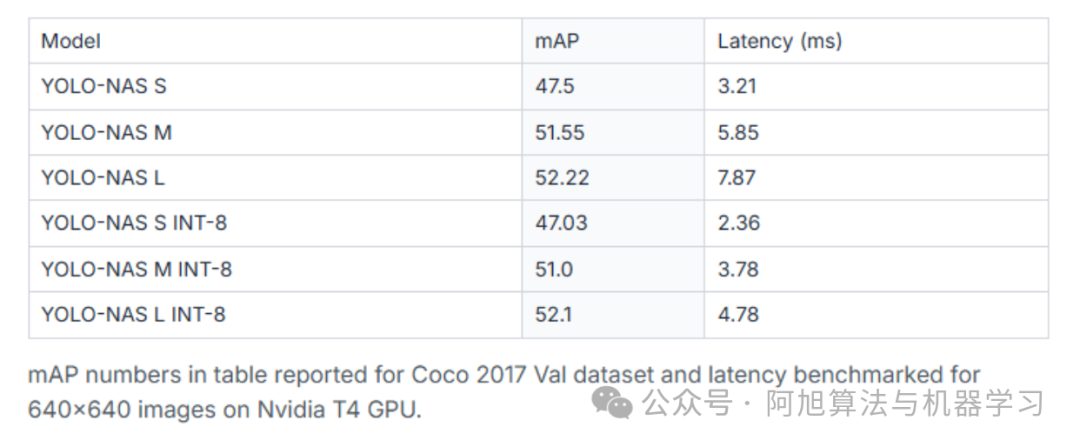
图片
与前代模型相比,性能提升显著:YOLO-NAS比YOLOv7提升20.5%,比YOLOv5提升11%,比YOLOv8提升1.75%。这些增强使YOLO-NAS对于需要速度和精度的生产部署特别有吸引力。
该模型在COCO、Objects365和Roboflow 100数据集上预训练,非常适合下游目标检测任务和向自定义领域的迁移学习。YOLO-NAS可通过Deci的SuperGradients库获取,该库包括分布式数据并行、指数移动平均、自动混合精度和量化感知训练等先进训练技术。
4. RTMDet
RTMDet由OpenMMLab开发,是一种高效的实时目标检测器,在NVIDIA 3090 GPU上在COCO数据集上实现了令人难以置信的52.8% AP,同时达到300+ FPS。这使RTMDet成为目前速度最快、精度最高的目标检测器之一,为高通量检测场景树立了新标准。
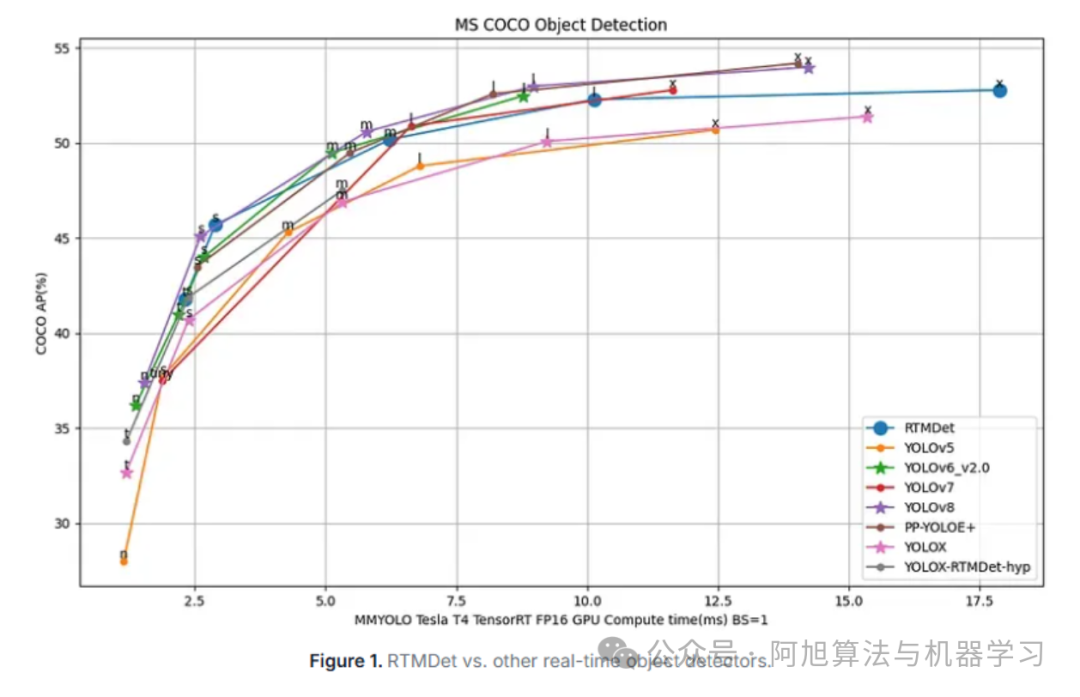
图片
该模型的速度源于多项架构创新:
-
为并行处理优化的轻量级骨干网络
-
动态标签分配提高训练效率
-
共享卷积层减少计算开销
-
利用GPU并行性的优化推理流程
RTMDet提供了跨精度-速度范围的变体:
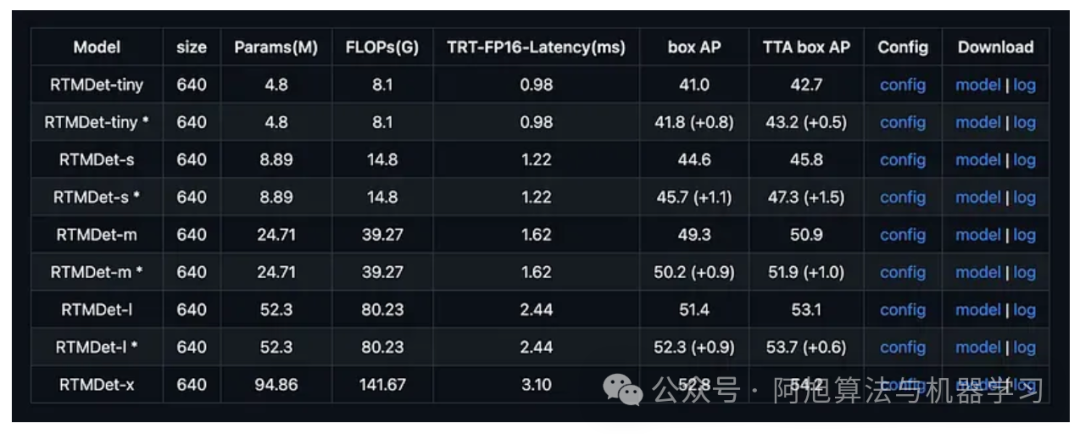
图片
-
RTMDet-Tiny:40.5% AP,1020+ FPS;为极端速度要求设计的最快变体
-
RTMDet-Small:44.6% AP,819 FPS;大多数应用的平衡选择
-
RTMDet-Medium:48.8% AP;更高精度同时保持出色速度
-
RTMDet-Large:51.2% AP;300+ FPS下的最高精度
-
RTMDet-Extra-Large:52.8% AP;满足高要求场景的峰值性能
即使是较大的变体也保持超过200 FPS的帧率,使RTMDet适用于高通量视频处理,而其他模型在此场景下可能会出现瓶颈。
RTMDet在需要最大吞吐量的应用中表现出色:
-
高速视频处理,每秒分析数百帧
-
体育或监控中快速移动目标的实时跟踪
-
制造业质量控制,以生产线速度检查产品
-
需要亚毫秒级检测延迟的自主机器人
-
GPU利用率直接影响成本的批量推理场景
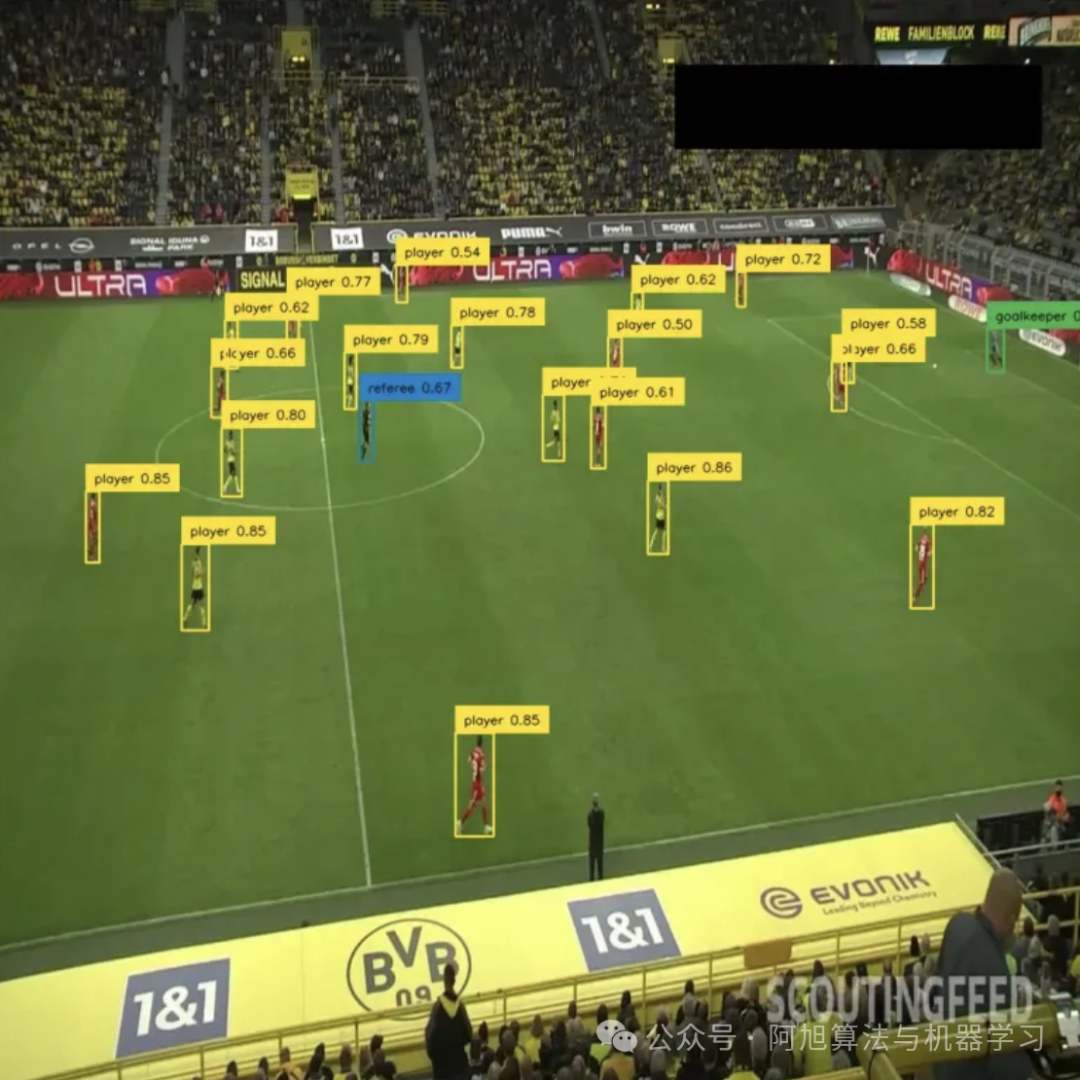
图片
RTMDet与MMDetection打包在一起,简化了部署,其MIT许可证允许无限制的商业使用。
最佳零样本目标检测模型
5. YOLO-World
YOLO-World通过为YOLO架构引入零样本、开放词汇能力,在目标检测领域实现了根本性转变。由腾讯AI实验室于2024年1月发布,YOLO-World解决了一个关键限制:为新目标类别重新训练模型的需求。
与传统检测器仅限于从COCO等训练数据集中预定义的类别(如80个类别)不同,YOLO-World只需通过文本描述提示即可检测目标。这是通过视觉-语言预训练实现的,该训练对齐了视觉和文本表示,使模型能够理解和检测训练期间从未见过的目标。
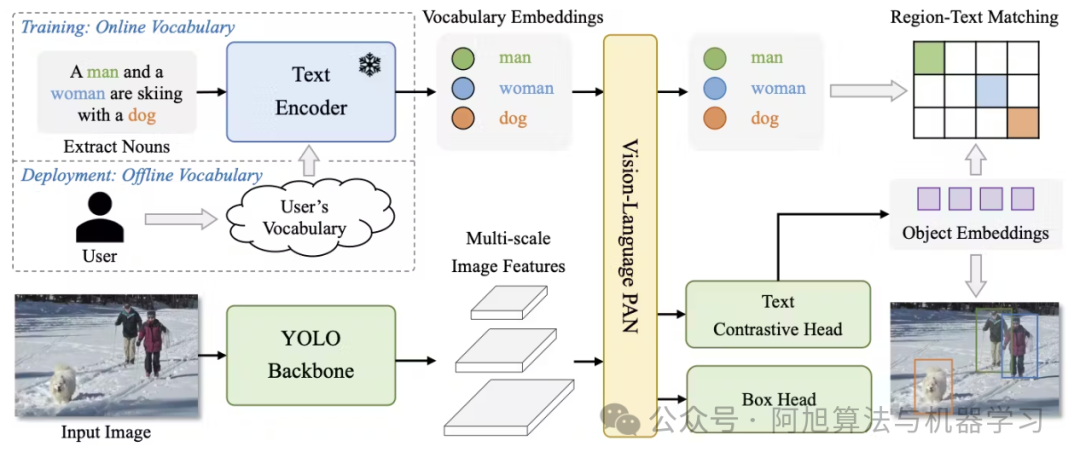
图片
上图是展示YOLO-World视觉-语言集成的架构图。它显示了YOLOv8骨干网络、RepVL-PAN(可重参数化视觉-语言路径聚合网络)和区域-文本对比学习组件。图中展示了文本嵌入和图像特征如何通过跨模态注意力机制融合。
YOLO-World的特别之处在于,它保持了基于CNN的YOLO架构的速度优势,同时实现了以前仅在较慢的Transformer-based模型(如Grounding DINO)中看到的零样本能力。在具有挑战性的LVIS数据集上,YOLO-World在V100上实现35.4 AP,帧率为52.0 FPS——比竞争的零样本检测器快约20倍,同时体积小5倍。
YOLO-World性能:
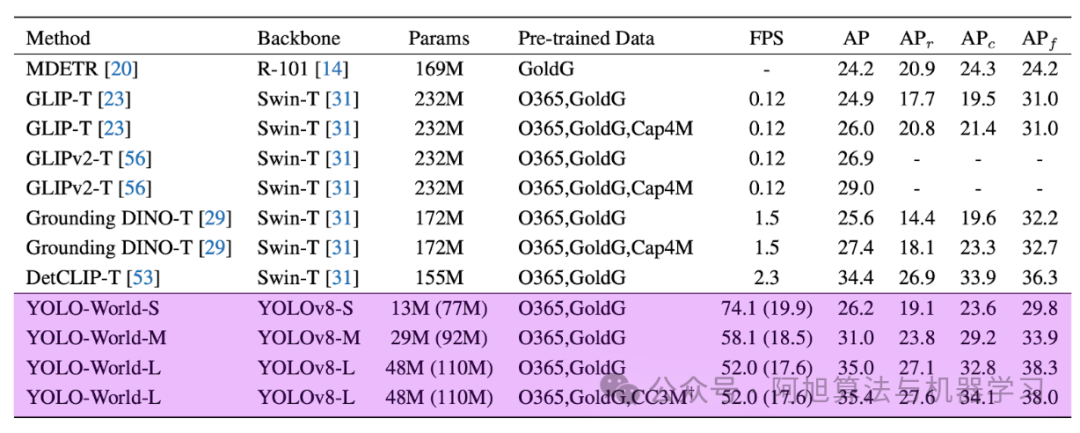
图片
-
零样本LVIS:35.4% AP,52.0 FPS
-
微调后:在下游检测和分割任务中表现出色
-
实时能力:适用于视频处理和边缘部署
该模型基于YOLOv8骨干网络,整合了可重参数化视觉-语言路径聚合网络(RepVL-PAN)和区域-文本对比损失,用于有效的视觉-语言建模。这种架构使YOLO-World能够高效处理图像特征和文本提示。
6. GroundingDINO
GroundingDINO是IDEA Research开发的最先进零样本目标检测模型,结合了Transformer-based检测的能力和接地语言理解。于2023年3月发布,并在2024年推出1.5版本增强版,GroundingDINO擅长通过自然语言描述检测目标,无需任何特定任务的训练。
该模型实现了令人瞩目的零样本性能:在没有任何COCO训练数据的情况下,在COCO上达到52.5% AP,微调后达到63.0% AP。在具有挑战性的ODinW零样本基准测试中,它以26.1% AP创下纪录,展示了其跨不同领域的泛化能力。
GroundingDINO的独特之处在于其双重能力。除了传统的目标检测外,它还支持指代表达式理解(REC),能基于复杂的文本描述识别和定位特定目标。例如,无需分别检测所有椅子和人,然后编写逻辑来查找有人坐的椅子,只需提示“有人坐的椅子”,模型就会直接检测出这些实例。
图片
GroundingDINO 1.5引入了两个针对不同场景优化的变体:
-
GroundingDINO 1.5 Pro:COCO零样本54.3% AP,LVIS-minival 55.7% AP,树立了新的精度基准
-
GroundingDINO 1.5 Edge:LVIS-minival 36.2% AP,TensorRT下75.2 FPS,为边缘设备优化
该架构消除了非极大值抑制(NMS)等手工设计的组件,简化了检测流程,同时提高了效率。GroundingDINO基于Transformer的设计结合了视觉Transformer(ViT),使其能够有效融合视觉和语言信息,使其在各种现实世界任务中具有高度的通用性。
GroundingDINO可通过Roboflow Inference部署,支持CPU和GPU部署,包括树莓派和NVIDIA Jetson设备。
哪种目标检测模型最实用?
RF-DETR是一款突破性的Transformer-based目标检测模型,结合了实时速度和最先进的精度。其采用预训练的DINOv2骨干网络,使其能够在从自动驾驶汽车到工业检测的各种视觉领域中很好地泛化。与传统模型不同,RF-DETR无需锚框和非极大值抑制,简化了检测过程并减少了延迟。
基准测试结果显示,RF-DETR-Medium在NVIDIA T4上在COCO数据集上实现54.7% mAP,延迟仅为4.52 ms,性能优于同类YOLO变体。此外,在RF100-VL领域自适应基准测试中,它达到60.6% mAP,证明了其在不同环境中的稳健性。
相比之下,YOLOv12引入了高效的注意力机制,在小型模型上延迟略低,但精度有所下降。YOLO-World和GroundingDINO等零样本模型无需重新训练即可实现灵活检测,但目前在原始性能上落后于RF-DETR。经NAS优化的YOLO-NAS在速度和量化方面取得了平衡,但在整体精度-速度权衡上并未超过RF-DETR。
结论
2025年的目标检测领域呈现多样化,模型针对各种需求进行了优化。RF-DETR等Transformer-based模型提供最先进的精度和实时速度。基于强大的DINOv2骨干网络,RF-DETR消除了传统的锚框和非极大值抑制,在COCO上实现54.7% mAP,延迟低于5ms,在RF100-VL基准测试中达到60.6% mAP,展示了出色的领域适应性。
YOLOv12等以注意力为中心的模型引入了高效的区域注意力和R-ELAN网络,在单阶段检测器中实现了略有不同的速度-精度权衡。YOLO-World和GroundingDINO等零样本模型消除了对大型标记数据集的需求,实现了灵活检测。由NAS驱动的YOLO-NAS在量化和精度之间取得平衡,适用于边缘部署。
与其他模型相比,RF-DETR在处理遮挡、复杂场景和领域转移方面始终表现出色,使其成为精度关键应用的理想选择。借助Roboflow Inference和Ultralytics等框架,从研究到生产的过渡变得更加便捷。
江大白
,赞143
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









