






炸裂!基于Transformer做目标检测新SOTA,比眨眼还快3倍,并首次在COCO数据集上实现60+的mAP!这便是RF-DETR模型,它在工业检测、自动驾驶等场景都取得了显著效果!
实际上,Transformer+目标检测一直都是合CV顶会的宠儿,近来录用量更是飙升!
这是因为:一方面,它能够克服传统CNN等目标检测算法,在全局建模方面的不足,显著提升模型在复杂场景下的精度!且其端到端的训练方式,也能简化检测流程!另一方面,其也比较好出创新点。比如训练速度、小目标性能优化都是亟待改进的问题。此外,结合多模态数据、轻量化设计等,也非常值得关注。
为让大家能够紧跟领域前沿,早点发出自己的顶会,我给大家准备了15种创新思路和源码!如果对你有帮助,点赞支持下哈~
论文原文+开源代码需要的同学看文末
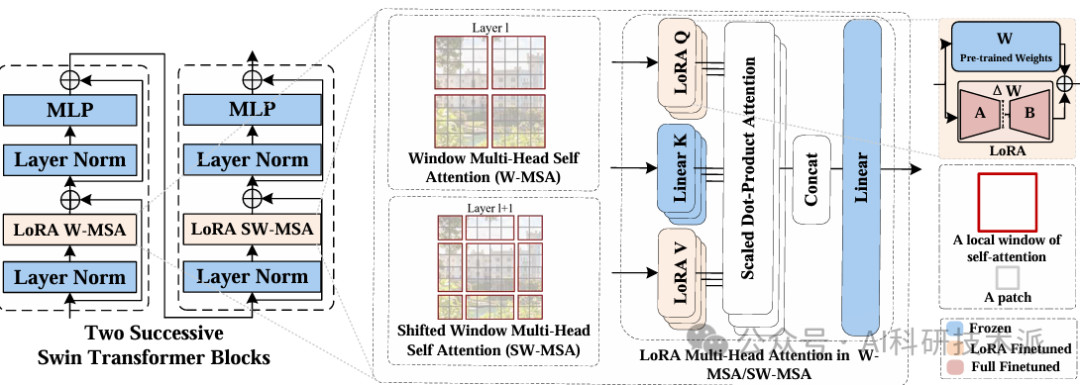
Low-Rank Adaption on Transformer-based Oriented Object Detector for Satellite Onboard Processing of Remote Sensing Images
内容:这篇论文提出了一种基于参数高效微调技术(LoRA)的面向卫星载荷处理遥感图像的目标检测方法。针对卫星通信带宽有限导致模型参数更新困难的问题,该方法通过训练低秩矩阵参数并与原始模型权重矩阵结合,仅需更新少量参数即可适应新数据分布。实验表明,仅更新12.4%的模型参数即可达到接近全参数微调(97%至100%)的性能,同时加速模型训练并增强泛化能力。
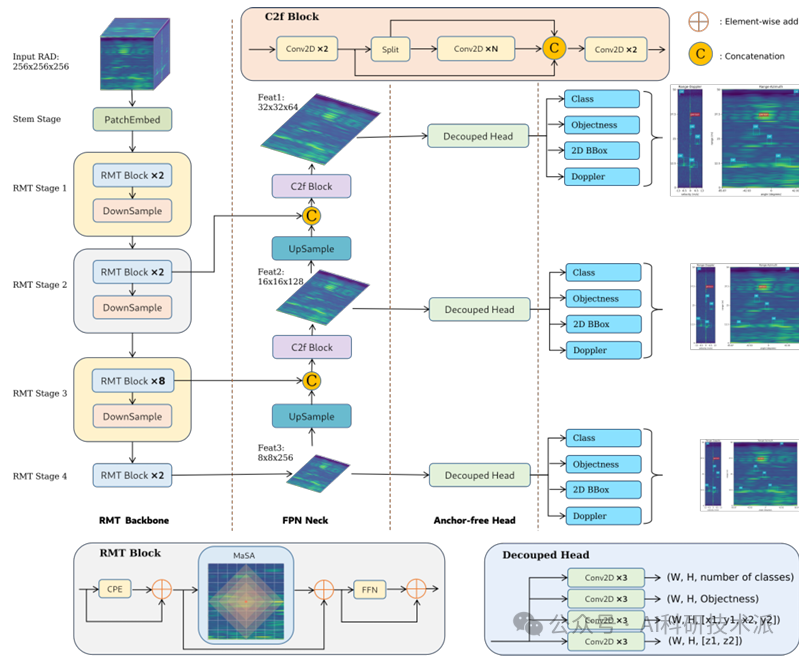
TransRAD: Retentive Vision Transformer for Enhanced Radar Object Detection
内容:这篇论文介绍了一种名为 TransRAD 的新型 3D 雷达目标检测模型,旨在解决自动驾驶和智能机器人领域中雷达数据低分辨率、高噪声和缺乏视觉信息等挑战。该模型基于RMT,利用其MaSA机制,结合雷达数据的空间先验信息,实现对雷达目标的精确 3D 检测。此外,TransRAD 提出了 Location-Aware NMS 方法,有效解决了雷达目标检测中常见的重复边界框问题。实验结果表明,TransRAD 在 2D 和 3D 雷达检测任务中均优于现有方法,具有更高的精度、更快的推理速度和更低的计算复杂度。
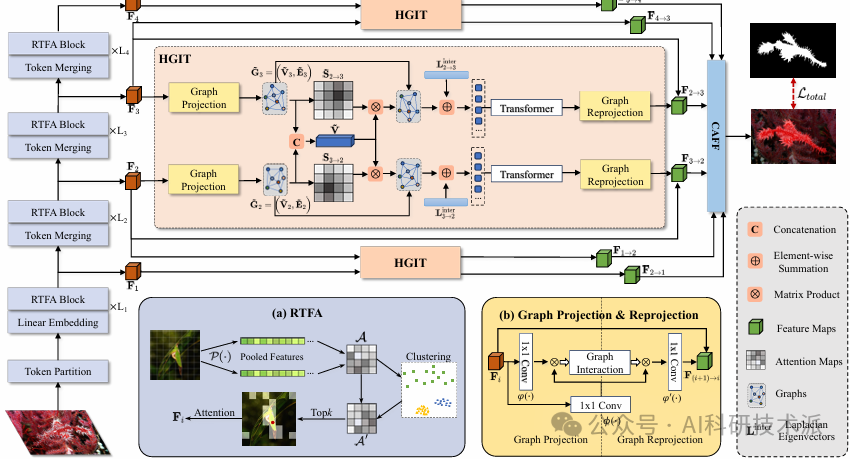
Hierarchical Graph Interaction Transformer with Dynamic Token Clustering for Camouflaged Object Detection
内容:这篇论文提出了一种名为 HGINet 的新型伪装目标检测(COD)模型,旨在通过层次化的图交互网络发现与背景高度融合的伪装目标。该模型包含三个关键模块:区域感知的动态令牌聚类注意力(RTFA)模块,用于挖掘局部区域中潜在可区分的令牌;层次化图交互 Transformer(HGIT),用于在潜在交互空间中构建层次化特征之间的双向对齐通信,增强视觉语义信息;以及带有置信度聚合特征融合(CAFF)模块的解码网络,用于细化模糊区域的局部细节。通过在多个主流数据集上的实验,HGINet 展示了其优越的性能,优于现有的先进方法。
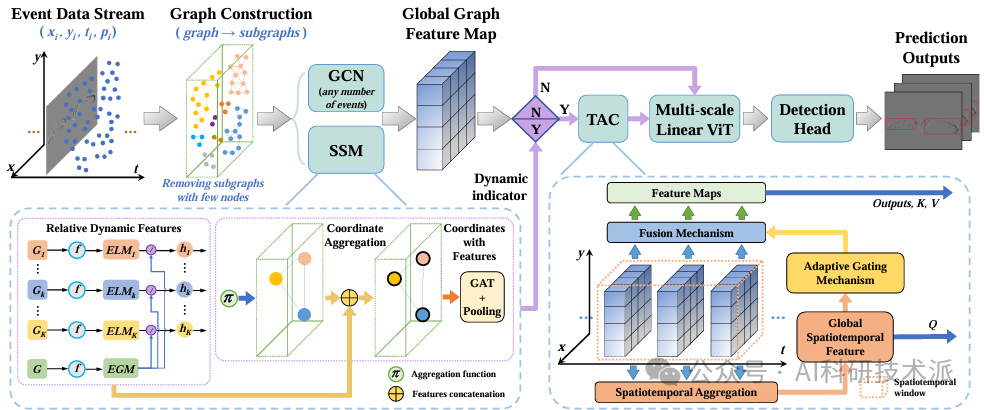
EGSST: Event-based Graph Spatiotemporal Sensitive Transformer for Object Detection
内容:这篇论文提出了一种名为 EGSST的新型事件相机目标检测框架,旨在充分利用事件数据的空间和时间特性。该框架通过图结构建模事件数据,保留原始时间信息并捕捉空间细节,并引入时空敏感模块(SSM)和自适应时间激活控制器(TAC)来模拟人眼对动态变化的注意力分配,从而在动态环境中高效地处理事件数据。此外,该框架还集成了轻量级多尺度线性视觉 Transformer(LViT),显著提升了处理效率。EGSST 提供了一种轻量级、快速、准确且完全基于事件的解决方案,适用于复杂动态环境中的目标检测任务,并在实验中展示了优越的性能和可扩展性。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【T检测】获取完整论文
👇

















 1894
1894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









