




概述
目标检测已经取得了长足的发展,尤其是随着基于 Transformer 的模型的兴起。RF-DETR,由 Roboflow 开发,就是这样一种模型,它兼顾了速度和精度。使用 Roboflow 的工具可以让整个过程变得更加轻松。他们的平台涵盖了从上传和标注数据到以正确格式导出数据的全过程。这意味着你可以节省设置的时间,将更多的时间用于训练和改进模型。
一、 模型变体、性能和基准测试
RF-DETR 是由 Roboflow 开发并以 Apache 2.0 许可证发布的实时、基于 Transformer 的目标检测模型架构。
RF-DETR 在微软 COCO 基准测试中可以超过 60 AP(平均精度),并且在基础尺寸下具有竞争力的性能。它还在 RF100-VL 目标检测基准测试中达到了最先进的性能,该基准测试衡量模型对现实问题的领域适应性。RF-DETR 的速度与当前的实时目标检测模型相当。
RF-DETR 提供两种模型尺寸:RF-DETR-Base(29M 参数)和 RF-DETR-large(128M 参数)。基础版本最适合快速推理,而大型版本最适合最准确的预测,但其计算时间比基础版本更长。
RF-DETR 足够小,可以在边缘设备上运行,使其非常适合需要强大精度和实时性能的部署。
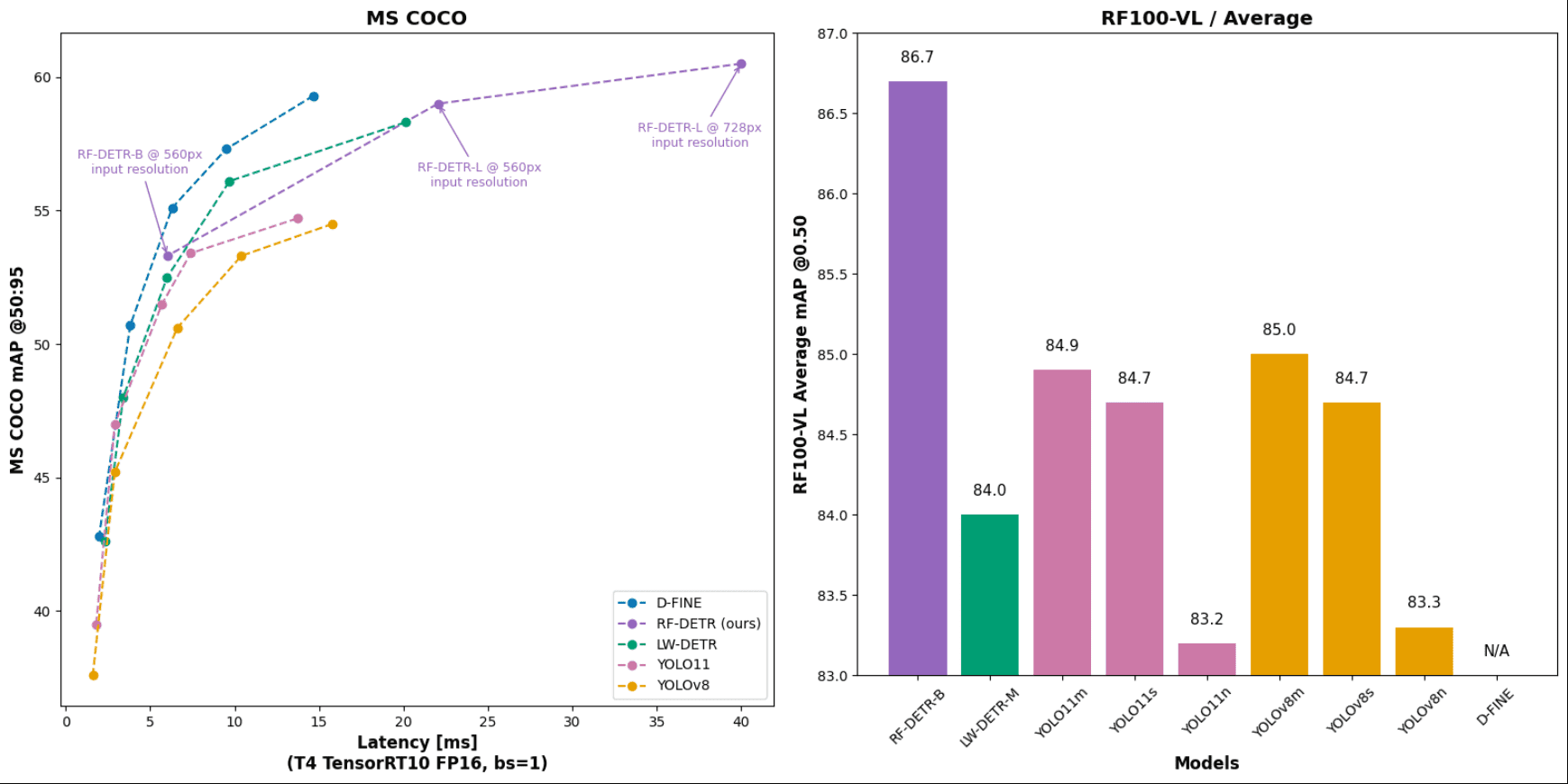
RF-DETR 在 coco 和 RF100 VL 基准测试中的性能
| 模型 | 参数量 (M) | mAP(coco) @0.50:0.95 | mAP(rf100-vl) 平均 @0.50 | mAP(rf100-vl) 平均 @0.50:0.95 | 总延迟(ms) T4, bs = 1 |
| D-FINE-M | 19.3 | 55.1 | N/A | N/A | 6.3 |
| LW-DETR-M | 28.3 | 52.5 | 84.0 | 57.5 | 6.0 |
| YOLO11m | 20.0 | 51.5 | 84.9 | 59.7 | 5.7 |
| YOLOv8m | 28.9 | 50.6 | 85.0 | 59.8 | 6.3 |
| RF-DETR-B | 29.0 | 53.3 | 86.7 | 60.3 | 6.0 |
二、 架构概览
CNN 仍然是许多最佳实时目标检测方法的核心组件,包括像 D-FINE 这样利用 CNN 和 Transformer 的模型。
最近,随着 2023 年 RT-DETR 的推出,DETR 系列模型通过 Transformer 架构在端到端目标检测任务中展示了可比甚至超越的结果,消除了 Faster-RCNN 等框架中标准的手动设计组件,如锚点生成和非最大抑制(NMS)。
尽管 DETR 模型具有优势,但它存在两个显著的局限性:
- 收敛速度慢
- 对小目标的检测性能差
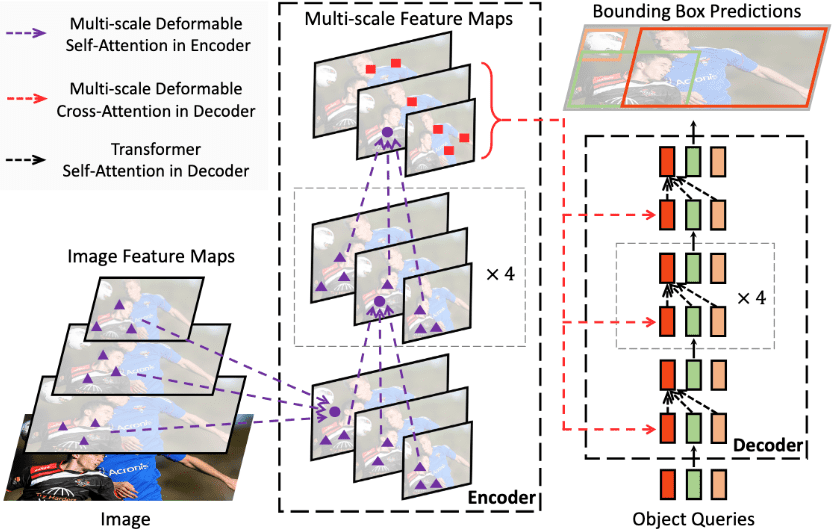
Deformable DETR,RF-DETR 基于此架构构建。
RF-DETR 使用基于 Deformable DETR 模型的架构来弥补上述局限性。然而,与使用多尺度自注意力机制的 Deformable DETR 不同,RF-DETR 从单尺度主干中提取图像特征图。
RF-DETR 结合了 LW-DETR 和预训练的 DINOv2 主干。利用 DINOv2 预训练主干提供了出色的适应新领域的能力,基于预训练模型中存储的知识。
让我们来审视一下 LW-DETR 架构的细节,RF-DETR 采用了与之相同的架构以及 DINOv2。DINOv2 的架构细节超出了本文的范围。对于那些有兴趣了解 DINOv2 的理念和架构的人,可以访问我们的文章,其中涵盖了论文解释和道路分割实现。
LW-DETR
LW-DETR 的架构由一个简单的 ViT 编码器堆叠、一个投影器和一个浅层 DETR 解码器组成。它探索了纯 ViT 主干和 DETR 框架在实时检测中的可行性。
编码器:
论文的作者使用了普通的 ViT 作为检测编码器。一个普通的 ViT 包括一个分块层和 Transformer 编码器层。初始 ViT 中的 Transformer 编码器层包含一个对所有标记进行全局自注意力的层和一个 FFN 层。全局自注意力的计算成本很高,其时间复杂度与标记数量的平方成正比。
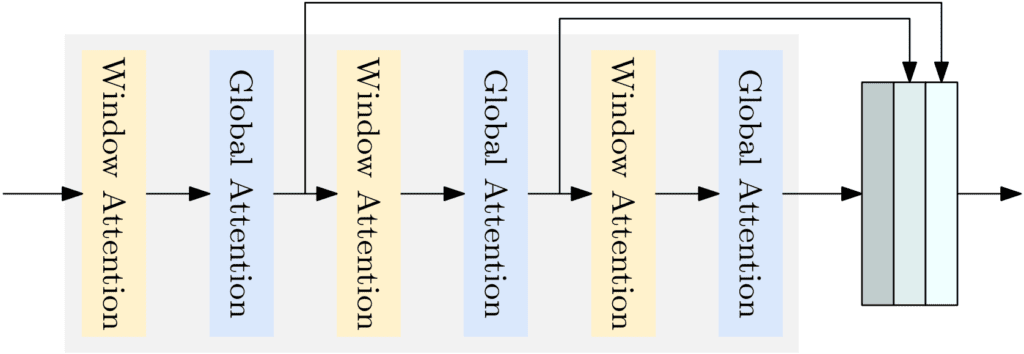
ViT 编码器
因此,作者引入了窗口自注意力来降低计算复杂度;他们还提出了聚合编码器中的多级特征图,形成更强的编码特征图。
解码器:
解码器是 Transformer 解码器层的堆叠。每一层都包含自注意力、交叉注意力和 FFN。我们采用可变形交叉注意力以提高计算效率。DETR 及其变体通常采用六个解码器层。然而,作者解释说,只使用三个 Transformer 解码器层可以使时间从 1.4 ms 减少到 0.7 ms,与他们方法中剩余部分的 1.3 ms 时间成本相比,这是一个显著的减少。
他们采用了混合查询选择方案来形成对象查询,除了内容查询和空间查询之外。内容查询是可学习的嵌入,类似于 DETR。空间查询基于一个两阶段方案:从 Projector 的最后一层中选择顶部 K 个特征,预测边界框,并将相应的框转换为嵌入作为空间查询。
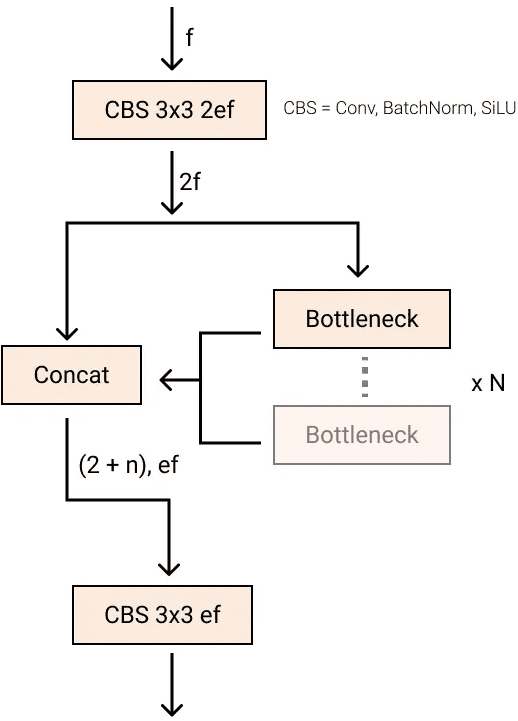
C2f 块(来自 YOLOv8)
投影器:
投影器连接编码器和解码器。它以编码器的聚合编码特征图为输入。投影器是一个在 YOLOv8 中实现的 C2f 块。
对于 LW-DETR 的大版本和特大版本,投影器被修改为输出两尺度特征图,并相应地使用多尺度解码器。投影器包含两个并行的 C2f 块。一个处理通过反卷积上采样获得的 ⅛ 特征图,另一个处理通过步长卷积下采样获得的 1/32 图。
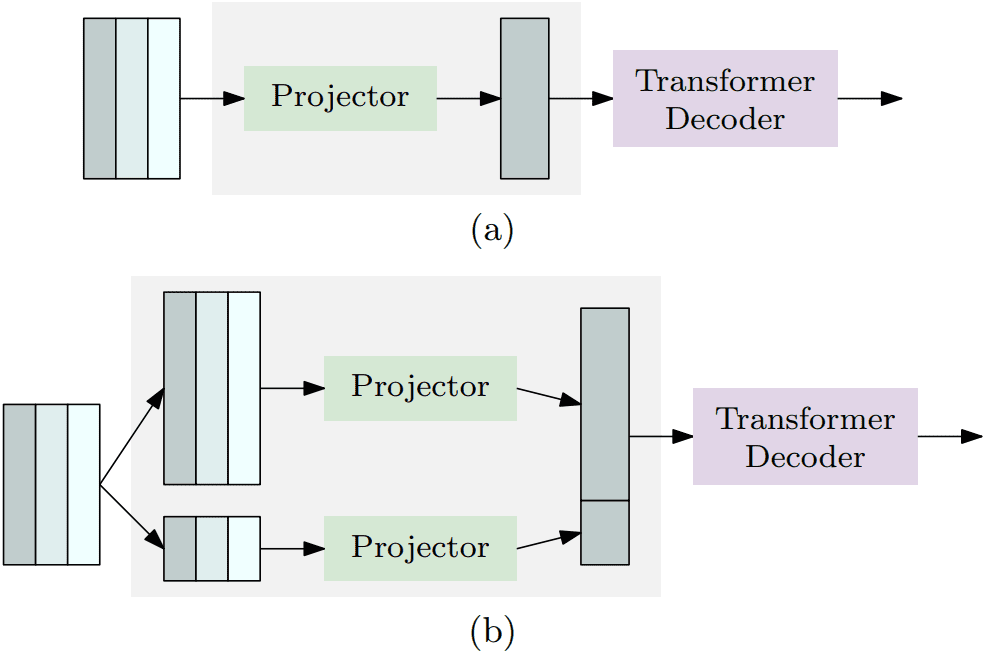
单尺度(a)和多尺度(b)投影器
三、推理结果
让我们通过编写一个简单的推理脚本来查看模型的开箱即用性能,该脚本由 Roboflow 提供。

目标检测前的推理图像
我们将使用下面的脚本来检测上面提供的图像中的目标。
需要注意的一点是,我们将使用由 Roboflow 创建和维护的 Supervision 库。这个库易于使用,不需要花费太多精力去理解它为对象检测任务提供的各种功能。无论你需要从硬盘加载数据集、在图像或视频上绘制检测结果,还是统计某个区域中的检测数量,都可以依靠 Supervision!
让我们开始编写代码。 :)
在进行推理之前,需要安装一些依赖项。如果你在 VS code 或终端中工作,强烈建议你创建虚拟环境并在其中进行操作,以确保更好的一致性并减少依赖项问题。
!pip install -q rfdetr==1.1.0
如果你在 Colab 中工作,像下面这样将 Roboflow 的 API 密钥集成到你的工作环境中。
import os
from google.colab import userdata
os.environ["ROBOFLOW_API_KEY"] = userdata.get("ROBOFLOW_API_KEY")
现在,我们已经准备好开始推理了。
# 导入必要的库
from rfdetr import RFDETRBase
import supervision as sv
from rfdetr.util.coco_classes import COCO_CLASSES
import numpy as np
from PIL import Image
# 实例化模型对象,初始化时会自动加载对应的 COCO 预训练检查点
model = RFDETRBase()
# 使用 Pillow 库读取图像,也可以使用 OpenCV 或 Matplotlib
image = Image.open("path_to_your_input_image")
# 执行推理,阈值决定了每个边界框的最小置信度
detections = model.predict(image, threshold=0.5)
# 使用 Supervision 库可视化结果
color = sv.ColorPalette.from_hex([
"#ffff00", "#ff9b00", "#ff8080", "#ff66b2", "#ff66ff", "#b266ff",
"#9999ff", "#3399ff", "#66ffff", "#33ff99", "#66ff66", "#99ff00"
])
text_scale = sv.calculate_optimal_text_scale(resolution_wh=image.size)
thickness = sv.calculate_optimal_line_thickness(resolution_wh=image.size)
bbox_annotator = sv.BoxAnnotator(color=color, thickness=thickness)
label_annotator = sv.LabelAnnotator(
color=color,
text_color=sv.Color.BLACK,
text_scale=text_scale,
smart_position=True
)
labels = [
f"{COCO_CLASSES[class_id]} {confidence:.2f}"
for class_id, confidence in zip(detections.class_id, detections.confidence)
]
# 显示结果
annotated_image = image.copy()
annotated_image = bbox_annotator.annotate(annotated_image, detections)
annotated_image = label_annotator.annotate(annotated_image, detections, labels)
annotated_image
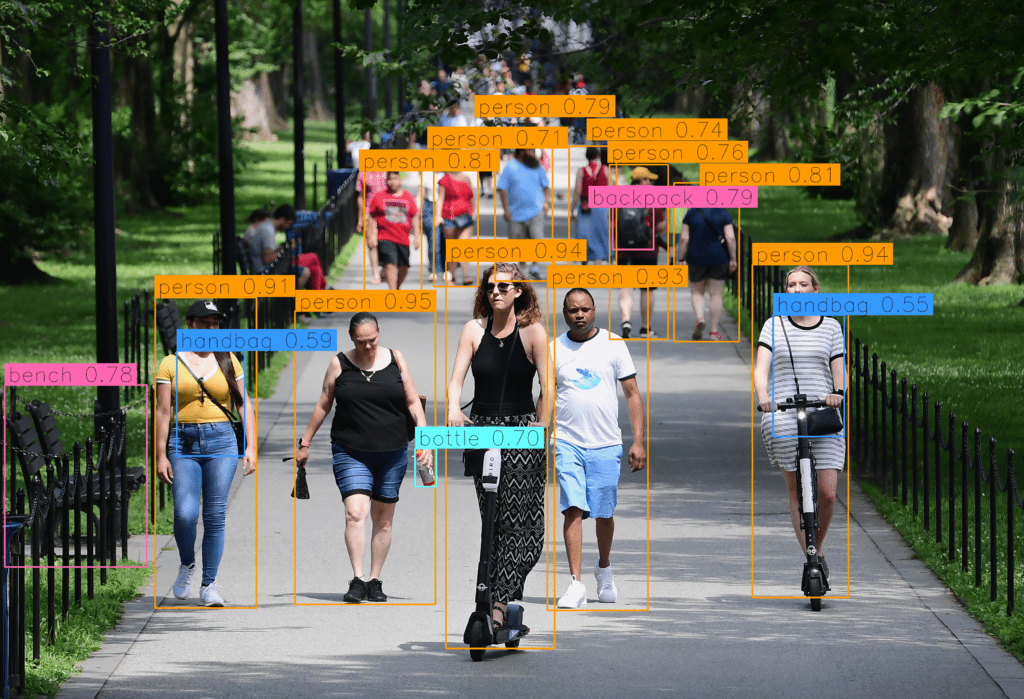
四、在水下数据集上进行微调
虽然 RF-DETR 在通用基准测试(如 COCO)上表现出色,并且在领域适应性方面显示出潜力,但挑战在于将其应用于特定的、小众的领域。
在水下图像数据集上对 RF-DETR 进行微调是一种强大的方法,可以将模型适应新的环境和目标类别。利用 Roboflow 的工具和资源,你可以从数据集准备到训练配置以及可视化结果的整个流程中受益。
在我们开始对水下数据集进行微调之前,需要注意的是,Roboflow 设计其微调流程时,仅允许使用 COCO 格式的数据集进行训练。COCO 格式如下:
underwater_COCO_dataset/
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ └── _annotations.coco.json
├── val/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ └── _annotations.coco.json
└── test/
├── images/
│ ├── image1.jpg
│ ├── image2.jpg
│ └── ...
└── _annotations.coco.json
挑战:水下动物检测
我们选择的数据集包含各种水下动物的图像,如 fish(鱼)、jellyfish(水母)、penguin(企鹅)、puffin(海鹦)、shark(鲨鱼)、starfish(海星)和 stingray(黄貂鱼)。
与典型的陆地图像数据集相比,该领域存在不同的挑战,具体如下:
- 可见性变化
- 拟态
- 尺度变化:检测远处的小鱼和近处的大鱼
该数据集可在 Kaggle 平台上公开获取,可以将其保存到本地机器上,也可以导入到新的 Kaggle 笔记本中。
关于该数据集的一些重要细节如下:
- 已经分为训练集、验证集和测试集
- 包含 638 张图像。标注(真实值)以 YOLO 格式提供(
class_id、x_centre、y_centre、width、height) - 对每张图像应用的预处理步骤:
- 自动定向像素数据(剥离 EXIF 方向信息)
- 调整大小至 1024 x 1024(在此范围内适配)
现在我们知道数据集必须是 COCO 格式,让我们开始编写脚本,将我们的水下数据集从 YOLO 格式转换为 COCO 格式。我们还将在此博客中提供转换脚本,你可以下载并使用它。
让我们开始吧……
import json
import os
from PIL import Image
在导入所有必需的库之后,第一步是定义一个类别列表,其中包含类别名称和对应的 ID 作为 dict_keys。
# 包含 supercategory 是可选的,可以省略
categories = [
{"id": 0, "name": 'fish', "supercategory": "animal"},
{"id": 1, "name": 'jellyfish', "supercategory": "animal"},
{"id": 2, "name": "penguin", "supercategory": "animal"},
{"id": 3, "name": "puffing", "supercategory": "animal"},
{"id": 4, "name": "shark", "supercategory": "animal"},
{"id": 5, "name": "stingray", "supercategory": "animal"},
{"id": 6, "name": "starfish", "supercategory": "animal"}
]
# 创建 COCO 格式架构
coco_dataset = {
"info": {},
"licenses": [],
"categories": categories,
"images": [],
"annotations": []
}
在实例化 COCO 格式架构之后,我们将创建一个图像字典,存储诸如 image_id、filename 等信息,并最终将其追加到我们的 COCO 架构字典的 images 键中。
annotation_id = 0
image_id_counter = 0
for image_fol in os.listdir(train_dir_images):
image_path = os.path.join(train_dir_images, image_fol)
image = Image.open(image_path)
width, height = image.size
image_id = image_id_counter
image_dict = {
"id": image_id,
"width": width,
"height": height,
"file_name": image_fol
}
coco_dataset["images"].append(image_dict)
从上面的代码块中,我们可以很容易地推断出,对于所有标注(真实值标签),也会创建类似的字典。因此,在相同的 for 循环中继续,我们现在将处理真实值。
# 使用 with open 语句读取 YOLO 格式文本文件中的行
with open(os.path.join(train_dir_labels,
f"{image_fol.split('.jpg')[0]}.txt")) as f:
annotations = f.readlines()
for ann in annotations:
category_id = int(ann[0])
x, y, w, h = map(float, ann.strip().split()[1:])
x_min, y_min = int((x - w / 2) * width), int((y - h / 2) * height)
x_max, y_max = int((x + w / 2) * width), int((y + h / 2) * height)
bbox_width = x_max - x_min
bbox_height = y_max - y_min
ann_dict = {
"id": len(coco_dataset["annotations"]),
"image_id": image_id,
"category_id": category_id,
"bbox": [x_min, y_min, x_max - x_min, y_max - y_min],
"area": bbox_height * bbox_width,
"iscrowd": 0
}
coco_dataset["annotations"].append(ann_dict)
annotation_id += 1
# 以下代码行在 for 循环之外
image_id_counter += 1
最后,我们将把我们的 “coco_dataset” 对象转储到 _annotations.coco.json 文件中,这是 COCO 格式标准的文件命名方式,用于存储真实值标注。另外,output_dir 是一个目录,我们将在本地机器上的该目录中存储 _annotations.coco.json 文件。
with open(os.path.join(output_dir, '_annotations.coco.json'), 'w') as f:
json.dump(coco_dataset, f)
在将我们的数据集转换为 COCO 格式之后,我们现在可以继续进行模型训练。正如 Roboflow 在其流程中创建的那样,实现起来非常简单,即使是初学者也能方便地理解。我们的实现(正如他们在官方 Colab 笔记本 中提到的训练和推理实现)使用了 Supervision 库。
from rfdetr import RFDETRBase
import supervision as sv
model = RFDETRBase(pretrain_weights="./checkpoints/checkpoint_best_regular.pth")
# 定义我们的类别,与前面代码块中提到的类似
categories = [
{"id": 0, "name": 'fish', "supercategory": "animal"},
{"id": 1, "name": 'jellyfish', "supercategory": "animal"},
{"id": 2, "name": "penguin", "supercategory": "animal"},
{"id": 3, "name": "puffing", "supercategory": "animal"},
{"id": 4, "name": "shark", "supercategory": "animal"},
{"id": 5, "name": "stingray", "supercategory": "animal"},
{"id": 6, "name": "starfish", "supercategory": "animal"}
]
# 定义回调函数用于处理视频帧
def callback(frame, index):
annotated_frame = frame.copy()
detections = model.predict(annotated_frame, threshold=0.6)
labels = [
f"{categories[class_id]['name']} {confidence:.2f}"
for class_id, confidence in zip(detections.class_id, detections.confidence)
]
annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
return annotated_frame
# 处理视频并保存结果
sv.process_video(
source_path="./video_3.mp4",
target_path="./output_annotations_4.mp4",
callback=callback,
)
process_video 函数将回调函数应用于每一帧,并将结果保存到目标视频文件中。
| 名称 | 类型 | 描述 | 默认值 |
| source_path | str | 源视频文件路径 | 必填 |
| target_path | str | 目标视频文件路径 | 必填 |
| callback | Callable[[ndarray, int], ndarray] | 一个函数,它接收视频帧的 numpy ndarray 表示和帧的索引(int),并返回处理后的 numpy ndarray 表示。 | 必填 |
为了评估微调后的 RF-DETR 模型在水下数据集上的性能,我们绘制了 50 个训练周期的关键评估指标。这些指标图表提供了有关模型学习行为、精度和泛化性能的宝贵见解。图表比较了 基础模型 和 指数移动平均(EMA)模型,后者有助于稳定训练,通常可以实现更好的泛化。
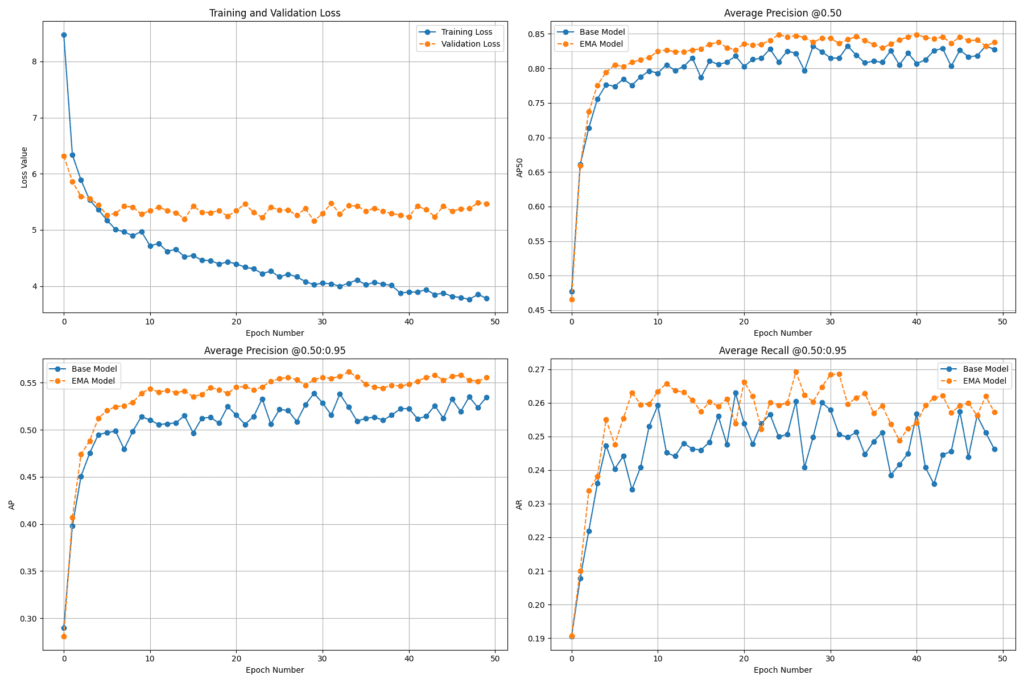
带 EMA 模型的指标图表
在总结本博客之前,下面的图像展示了在微调训练期间的 CPU/GPU 消耗情况。我们在 Kaggle 平台上利用 P100 GPU 进行了所有实验。
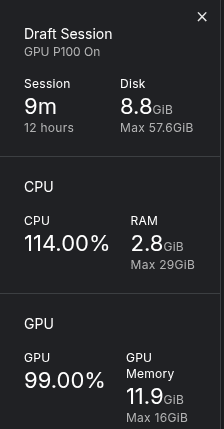
Kaggle 平台上的 GPU/CPU 消耗
五、 关键要点
- RF-DETR 是由 Roboflow 开发的实时目标检测模型,它基于 Deformable DETR 和 LW-DETR 的优势,并整合了 DINOv2 主干,以实现卓越的领域适应性。
- 该模型消除了传统检测组件(如锚点框和 NMS)的需求,利用基于 Transformer 的架构实现端到端目标检测。
- 两种模型变体 —— 基础版(29M)和大型版(128M)—— 在速度和精度之间提供了灵活性,使 RF-DETR 既适合边缘部署,也适合高性能场景。
- Roboflow 的 Supervision 库 简化了整个训练和可视化工作流程。
- 该模型可以 针对特定领域进行有效微调,如通过水下数据集进行微调,利用其预训练知识。
六、 结论
RF-DETR 证明了其在通用任务和特定领域任务中进行实时目标检测的多功能性和高性能。其强大的架构,由 Deformable DETR 和 LW-DETR 等基于 Transformer 的架构以及 DINOv2 等预训练主干提供支持,使其成为开发人员处理自定义检测问题的良好选择。
通过将 RF-DETR 与强大的工具(如 Supervision)结合使用,AI 爱好者可以快速构建高质量、生产就绪的模型,这些模型能够很好地适应新领域。无论你是部署在边缘设备上还是进行研究实验,RF-DETR 都提供了灵活性和性能,以推动你的计算机视觉项目向前发展。



















 720
720




 到【灌水乐园】发言
到【灌水乐园】发言









