






本文来源公众号“AI生成未来”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/CNAI5UlPkpmCXG_D1vgEtA

论文链接:https://arxiv.org/pdf/2510.24657
项目 & 代码链接:https://little-misfit.github.io/GRAG-Image-Editing/
亮点直击
通过大量实验,发现MM-DiT中查询和键嵌入存在偏置分布,并对其在图像编辑任务中的作用进行了数学分析;
提出组相对注意力引导(GRAG),这一新方法通过利用 token 间的相对关系来调控图像编辑过程,借助其与组偏置的偏差实现精确可控的编辑;
在多个基线模型上开展广泛实验,并在多样化的编辑任务中评估性能,证明了本方法的有效性。
总结速览
解决的问题
-
编辑控制粒度不足:现有基于DiT的图像编辑方法缺乏对“编辑程度”的有效控制,难以实现连续、细粒度的调整。
-
定制化能力受限:由于无法精确控制编辑强度,模型难以生成符合用户个性化需求的编辑结果。
-
依赖外部调参:用户通常需要依赖提示工程或进行多次推理才能获得满意效果,流程繁琐。
提出的方案
-
提出了名为组相对注意力引导(GRAG) 的新方法。
-
该方案的核心思想是:通过重新加权不同 token 与其所在层共享的“偏置向量”之间的差值,来调控模型在“遵循编辑指令”和“保留原图内容”之间的关注度。
-
这是一种无需训练、即插即用的引导机制。
应用的技术
-
机理分析:深入分析了DiT模型中的MM-Attention机制,发现了查询(Q)和键(K)嵌入中存在仅与层相关的共享偏置向量。
-
理论构建:将“偏置”解释为模型固有编辑行为,将“token 与偏置的差值”解释为具体内容的编辑信号。
-
算法实现:GRAG方法通过计算平均组偏置,并引入权重系数(λ)来调节各个 token 的Δ向量,从而增强或抑制其编辑强度。
达到的效果
-
实现精确可控的编辑:能够实现连续、细粒度的编辑强度控制,生成平滑渐进的编辑效果。
-
即插即用,易于集成:方法轻量,仅需少量代码(如四行) 即可集成到现有编辑框架中,并持续提升编辑质量。
-
性能优越:与常用的无分类器引导等方法相比,能提供更平滑、更精确的编辑程度控制,在编辑响应度和图像保真度之间取得了更优的平衡。
-
经过广泛验证:在多个基线模型和多样化编辑任务上进行了实验,验证了方法的有效性。
嵌入向量中的偏置向量
MM-DiT的注意力层是编辑指令和条件图像信息融合的关键位置,其中查询和键嵌入直接影响从每个 token 采样的内容比例。本实验揭示了嵌入特征沿序列维度分布存在显著偏置,该偏置集中在每个 token 内的固定位置。假设这种偏置是DiT图像编辑过程中实现上下文理解的关键因素。

E的可视化结果如下图4所示。在嵌入向量空间中,每个维度索引对应一个分量,图4中的深红色区域表示幅度较大的位置,这些位置对不同 token 嵌入之间的内积贡献更大。通过研究RoPE(旋转位置嵌入[33])与维度索引之间的关系,观察到文本嵌入集中在与语义相关的低频分量中,而图像嵌入则集中在捕捉空间关系的高频分量中。这一发现表明两种模态在共享嵌入空间中并未完全对齐。此外,研究了 token 嵌入在向量空间中的分布。下图5展示了不同注意力头的平均向量幅度和标准差,进一步揭示了嵌入空间中 token 间存在显著偏置向量的现象。
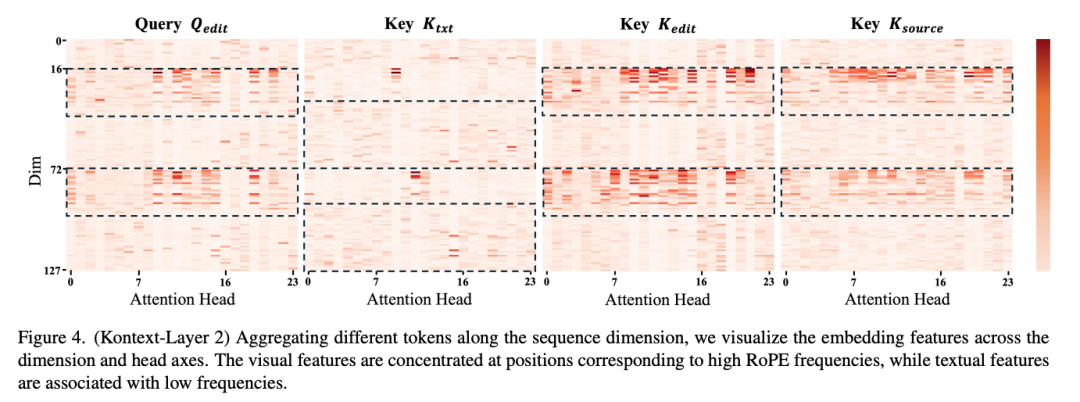
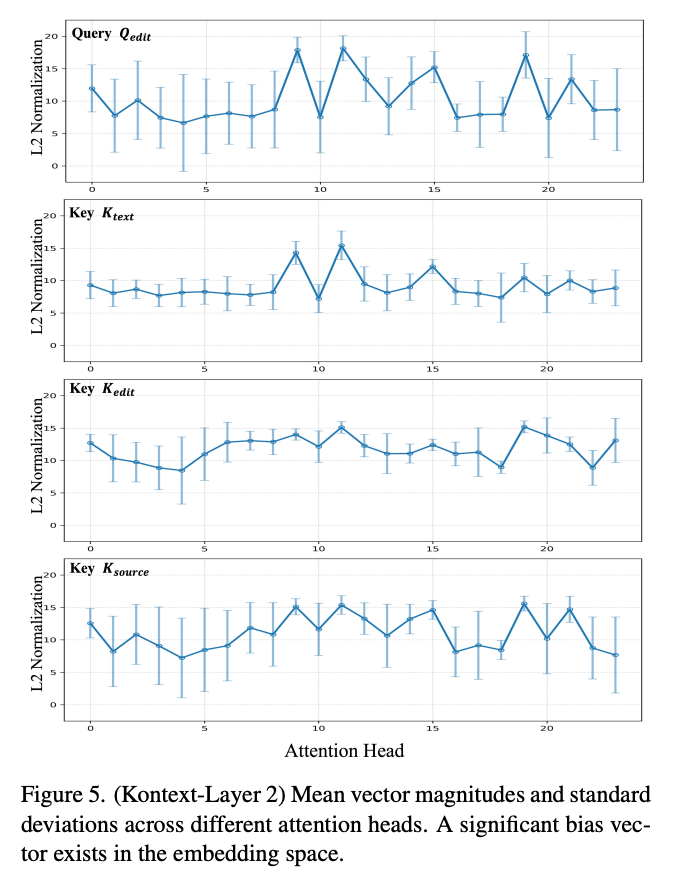
偏置向量分析。上述发现表明,注意力层中的查询和键嵌入呈现出可分解的结构,其中每个嵌入均可表示为一个主导偏置分量与一个独立变化量之和:

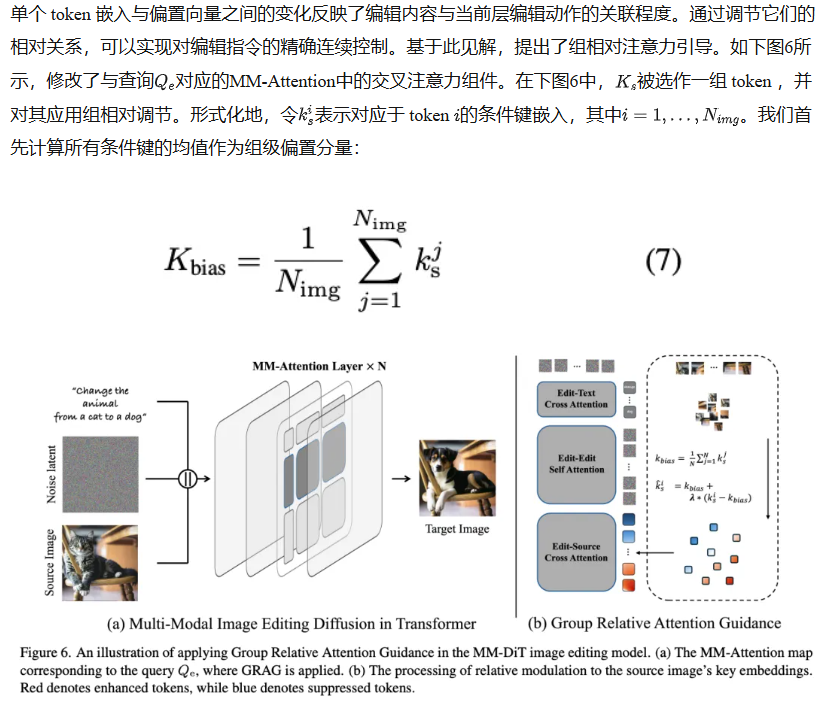
组相对注意力引导

实验
实验设置
实现细节。在六个图像编辑基线上验证我们提出的方法。Kontext、Step1X-Edit和Qwen-Edit是基于训练的图像编辑方法。为可复现性,随机种子固定为42。所有实验的批次大小设为1,推理步数为24。分类器引导参数按照各模型的推荐值设置:Kontext为2.5,Step1X-Edit为6.0,Qwen-Edit为4.0。
此外,GRAG在理论上适用于常规的基于MM-DiT的架构。因此,我们选择了三种基于Flux.1-Dev T2I模型的免训练图像编辑方法(Flowedit、Stableflow、Stableflow+)来评估我们方法的泛化能力。我们将在下文进行进一步讨论。
评估。在PIE上评估我们的方法。该基准涵盖了多种编辑任务,包括对象添加/移除、风格迁移和姿态修改。对于定量评估,我们采用两个互补的视角。遵循先前工作,采用LPIPS和SSIM作为定量指标来评估未编辑区域的内容保持能力。为评估编辑结果与人类偏好的对齐程度,我们采用图像编辑奖励模型EditScore。EditScore是在Qwen-2.5VL上微调的奖励模型,它衡量三个方面:与原始图像的一致性、提示跟随和整体编辑得分。
定性分析
将GRAG应用于三种主流的基于MM-DiT的图像编辑模型,定性结果如图7所示。在Step1X-Edit和Qwen-Edit上,我们的方法在保持预期编辑效果的同时,改善了编辑后图像与原始参考图像之间的一致性,产生了更真实自然的结果。由于Step1X-Edit和Qwen-Edit利用视觉-语言模型来编码编辑指令,额外的指令信息通常增强了响应性但降低了一致性。我们选择源图像标记作为组,并应用GRAG来增强编辑相关标记对编辑指令的响应,同时抑制不相关标记的响应。例如,在图7的第一列中,GRAG成功改变了鸟的纹理,同时保留了树干的细节;在第五列中,它改变了苹果的颜色,同时保留了细粒度的表面细节。这些例子证明了GRAG在保持对源图像保真度的同时,实现精确连续编辑控制的能力。对于原始Kontext模型,我们选择文本标记作为组,并应用GRAG来增强模型对编辑指令的响应。如下图7右侧所示,基线未能响应编辑指令,内容没有变化,而应用GRAG则实现了成功的编辑。

定量分析
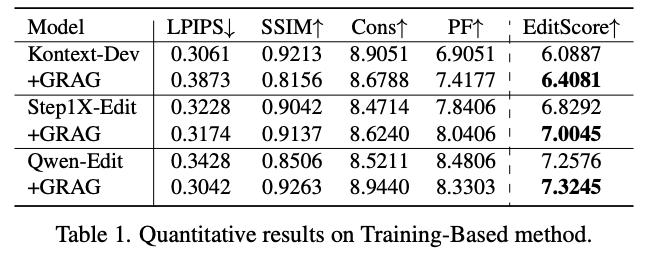
如下表1所示,在PIE数据集上进行了定量评估。在集成GRAG后,Step1X-Edit和Qwen-Edit的编辑输出与原始图像之间的一致性得到增强,这体现在LPIPS、SSIM和Cons指标的提升上。尽管PF略有下降,但反映整体编辑质量的EditScore有所增加。相比之下,Kontext在应用GRAG后,PF有显著改善,并获得了更高的EditScore。这些趋势与视觉结果非常吻合。
消融研究
与CFG的差异。将我们的方法与主流引导方法——分类器自由引导进行比较。与CFG在采样过程中调整去噪方向不同,我们的方法直接调节注意力层内的编辑信息。如下表2和下图10所示,改变CFG强度产生的差异很小。相比之下,GRAG能够实现精确连续的编辑控制,随着编辑强度的增加产生平滑一致的调整,视觉对比如下图9所示。这种可控性对于定制化图像编辑应用至关重要。
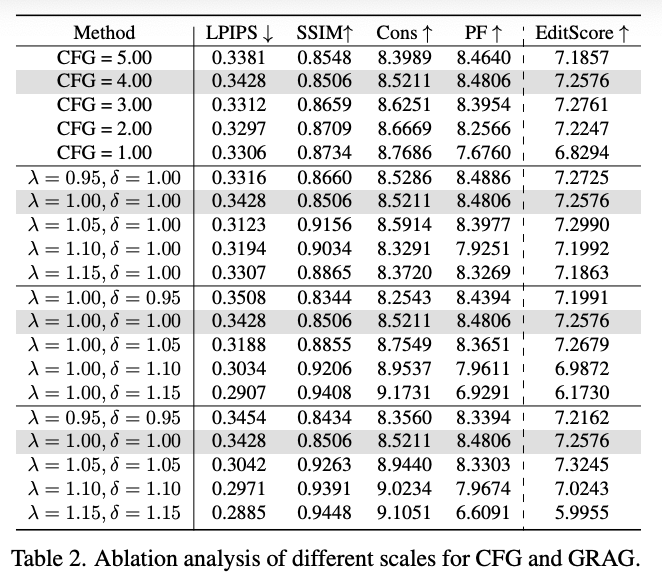


组相对参数的有效性分析。分析了公式9中参数和对编辑结果的影响。进行了三组实验:仅调整、仅调整,以及同时调整和。定性结果如上图9所示,而在PIE基准上的定量结果呈现在上表2和上图10中。单独调整对编辑结果没有显著影响,对应上图10中的波动曲线,这表明调整无法有效控制编辑强度。相比之下,联合调整和能够实现一定程度的可控编辑,但无法达到连续精度。此外,这种同时调整通常会降低视觉保真度,导致不希望的伪影,例如左下角样本第二列中扭曲的花朵,以及上图9中右下角样本第一列中可见的伪影。单独调整能产生最佳结果,对应上图10中最平滑的指标变化和上图9中最连续的编辑过渡。
讨论与局限性
进一步检验了GRAG在仅涉及文本和目标图像 token 的通用MM-Attention架构的编辑方法中的适用性。在这些方法中,GRAG被应用于注入源图像特征的注意力层。如下图8所示,我们的方法实现了对编辑结果的调整,表明GRAG在通用MM-Attention结构中仍然有效。然而,其在免训练设置下的稳定性低于基于训练的模型,表3中的定量结果证明了这一点。我们将此归因于GRAG主要调节MM-Attention中的交叉注意力组件(见上图6),而在未训练的T2I模型中,源图像特征是通过编辑-编辑自注意力分支引入的(上图6-b)。在这种情况下,应用GRAG会干扰现有的目标图像表示。

结论
本工作重新审视了扩散变换模型内部的注意力机制,并揭示了控制编辑行为的共享偏置向量的存在。基于这一发现,我们提出了组相对注意力引导,这是一种轻量级但有效的策略,通过调节 token 相对于组偏置的偏离来实现对编辑强度的细粒度和连续控制。GRAG可以无缝集成到现有的基于DiT的编辑器中,持续提升可控性和保真度。我们的研究结果为多模态注意力的内部动力学提供了新的见解,并为未来DiT架构中增强可控图像编辑提供了实用方向。
参考文献
[1] Group Relative Attention Guidance for Image Editing
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









