




本文来源公众号“阿旭算法与机器学习”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/Ry5qQN7h_BBZo9Ekopoc1g
引言

在这里插入图片描述
在智能眼镜、物联网设备和无人机等对延迟和隐私高度敏感的应用中,实时、设备端(on-device)的图像分割技术至关重要。然而,像Meta的Segment Anything Model (SAM) 及其继任者SAM2 这样强大的模型,由于其庞大的体积和基于Transformer的架构,在资源受限的边缘设备上部署变得遥不可及。它们往往超出内存限制,依赖不受支持的操作符,或需要与硬件不兼容的架构组件。
来自ETH Zürich和IBM Research的研究人员带来了突破性的解决方案:PicoSAM2!
简介
PicoSAM2是一款轻量级(1.3M参数,336M MACs)的可提示视觉分割模型,专为边缘和传感器内(in-sensor)执行而优化,甚至可以直接部署在 索尼IMX500智能视觉传感器 上。
它不仅是 首个证明在资源受限的边缘平台实现实际传感器内部署的分割模型,更是唯一能同时满足IMX500内存和计算约束的模型。这意味着,我们可以在不依赖云端或主机处理的情况下,实现 隐私保护的视觉感知。
PicoSAM2架构和技术
PicoSAM2之所以能如此高效,得益于其精巧的设计和优化:
-
轻量级U-Net架构:
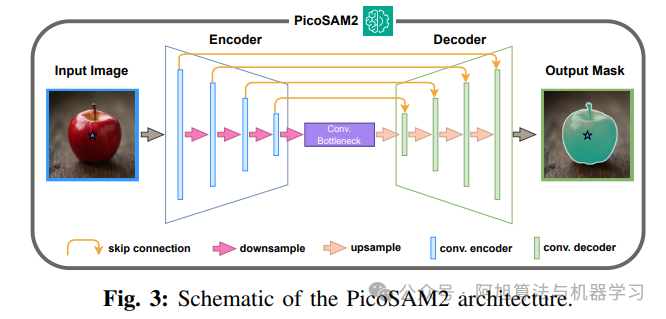
◦ 模型基于 深度可分离的U-Net,结合跳跃连接(skip connections)和上/下采样,确保空间信息保留和量化友好性。 ◦ 它采用 密集的CNN骨干网络 与金字塔特征,以模仿Transformer的强大容量,同时避免了对微控制器单元(MCU)部署不友好的Transformer模块。3. 创新的提示编码方式:
◦ 针对IMX500只支持RGB输入,无法进行显式多模态提示的限制,PicoSAM2采取了一种巧妙的 隐式编码 方法:在训练时,它裁剪图像,使提示点始终位于中心。
◦ 通过这种方式,模型能够学习到空间先验(spatial prior),从而在没有额外输入通道的情况下,实现可提示的分割。
-
知识蒸馏(Knowledge Distillation):
◦ PicoSAM2通过知识蒸馏技术,从强大的SAM2模型中学习。
◦ 训练目标结合了教师模型(SAM2)的 软监督(soft supervision) 和真实标签的 硬监督(hard supervision)。这种混合监督在有限数据下显著提高了模型的泛化能力。
◦ 事实证明,知识蒸馏将LVIS数据集上的mIoU性能提升了 +3.5%,mAP提升了 +5.1%。
-
INT8静态量化:
◦ 模型训练完成后,进行 静态INT8量化,进一步减小模型体积并加速推理。
PicoSAM2优势
PicoSAM2在计算成本、分割精度和部署能力三大核心维度上都取得了有竞争力的性能:
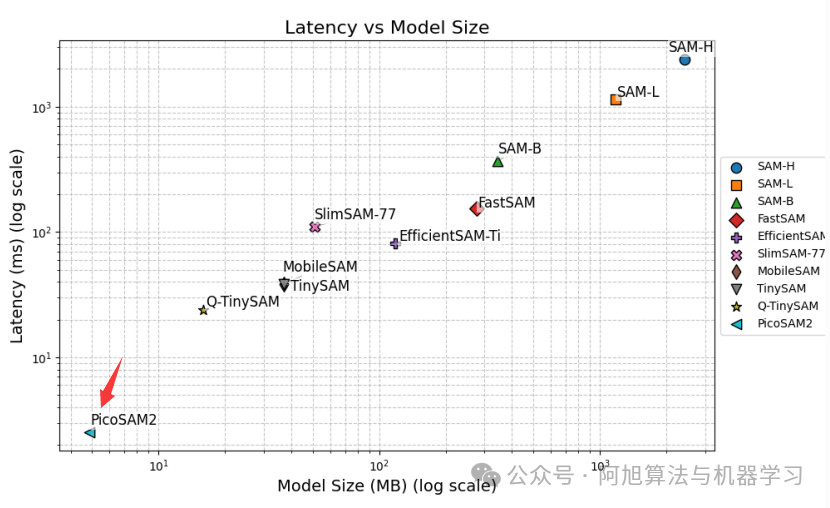
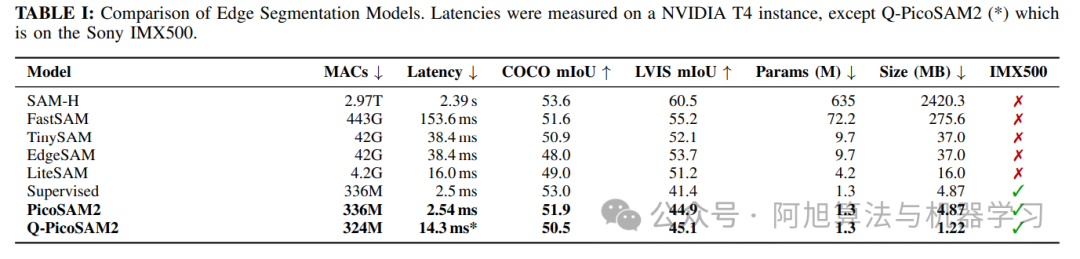
• 极致小巧:1.3M参数,量化后模型大小仅为 1.22MB,轻松满足索尼IMX500严格的 8MB内存限制。
• 超低功耗计算:仅需 336M MACs,远低于SAM-H的0.02%。
• 实时推理:
◦ 在NVIDIA T4 GPU上,推理延迟仅为 2.54ms。
◦ 在索尼IMX500上,量化后的PicoSAM2(Q-PicoSAM2)实现了 14.3ms 的设备端推理延迟,每周期约86 MACs的推理效率。
• 卓越精度:
◦ 在COCO数据集上达到 51.9% mIoU。
◦ 在LVIS数据集上达到 44.9% mIoU。
实验对比

在这里插入图片描述
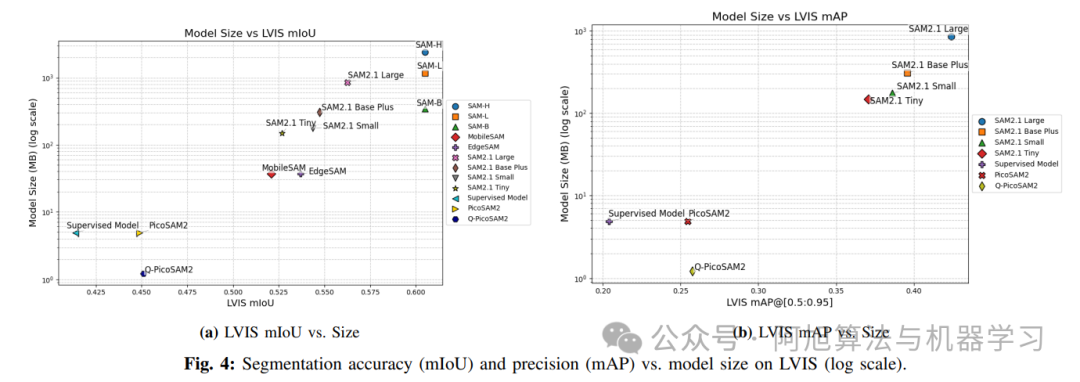
文章中实验主要将PicoSAM2与包括SAM-H在内的大型模型以及FastSAM、TinySAM、EdgeSAM、LiteSAM等多种轻量级分割模型进行了全面比较。对比维度聚焦于计算成本(MACs)、推理延迟(在NVIDIA T4 GPU和索尼IMX500上的表现)、分割精度(在COCO和LVIS数据集上的mIoU和mAP)以及模型大小。
实验结果突出显示,PicoSAM2是唯一能满足索尼IMX500严格的8MB内存限制和有限ONNX操作符支持的分割模型,同时实现了最低的计算成本(336M MACs),超低的推理延迟(NVIDIA T4上2.54ms,IMX500上14.3ms),极致小巧的模型体积(量化后1.22MB),并在这些严苛限制下保持了竞争性的分割精度(COCO 51.9% mIoU,LVIS 44.9% mIoU)。
此外,实验还通过消融研究证实,知识蒸馏技术显著提升了模型的泛化能力和精度,例如在LVIS数据集上mIoU提升了+3.5%,mAP提升了+5.1%
总结
PicoSAM2的出现,标志着 智能、可提示的视觉模型可以直接部署在资源受限的传感器上 的可行性。它为智能眼镜、安全监控、自动驾驶辅助、工业检测等众多边缘AI应用,开辟了全新的可能性。
这项技术不仅提升了性能,更重要的是,它将 AI的决策能力从云端推向了数据捕获的源头,为用户带来了前所未有的 低延迟、高隐私保护 的智能视觉体验。PicoSAM2无疑是边缘AI视觉领域的一个重要里程碑!
❝论文地址:https://arxiv.org/pdf/2506.18807
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









