






本文来源公众号“阿旭算法与机器学习”,仅用于学术分享,侵权删,干货满满。
原文链接:重磅突破!CountVid:视频中任意物体的自动计数!【附论文与源码】
1. 模型简介
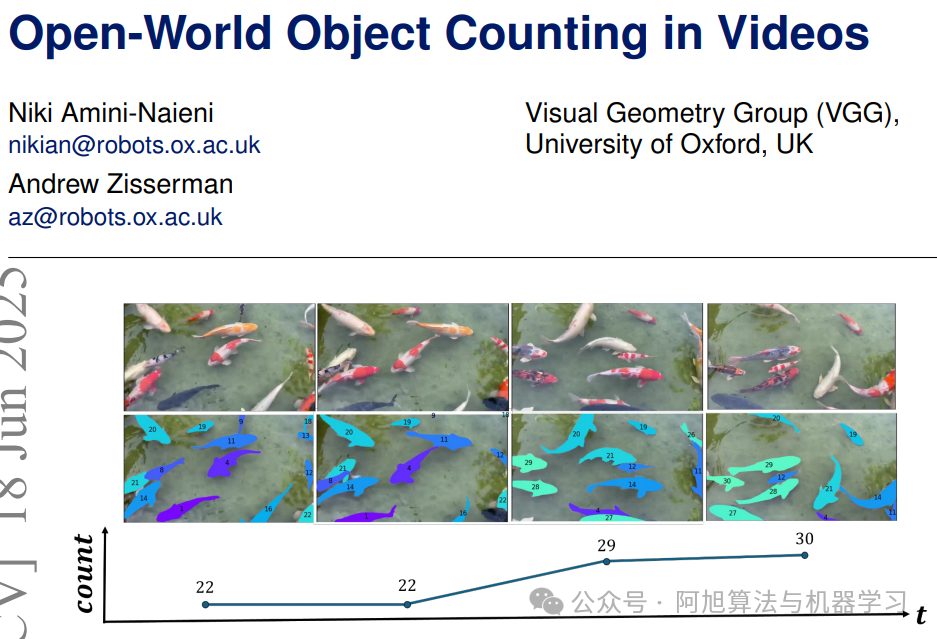
在这里插入图片描述
牛津大学视觉几何组(VGG)团队提出COUNTVID模型,首次实现视频场景下的开放词汇物体计数。该模型通过文本描述(如"鱼")或图像示例,即可自动统计视频中目标物体的独立出现次数,解决遮挡、相似物体干扰等复杂场景的计数难题。核心组件包括:
-
COUNTGD-BOX:改进的图像计数模型,
支持文本/视觉示例双输入 -
SAM 2.1:可提示的视频分割与追踪模型
-
三级处理框架:从单帧检测到长时追踪的渐进式分析
2. 核心创新
创新点1:三级处理架构
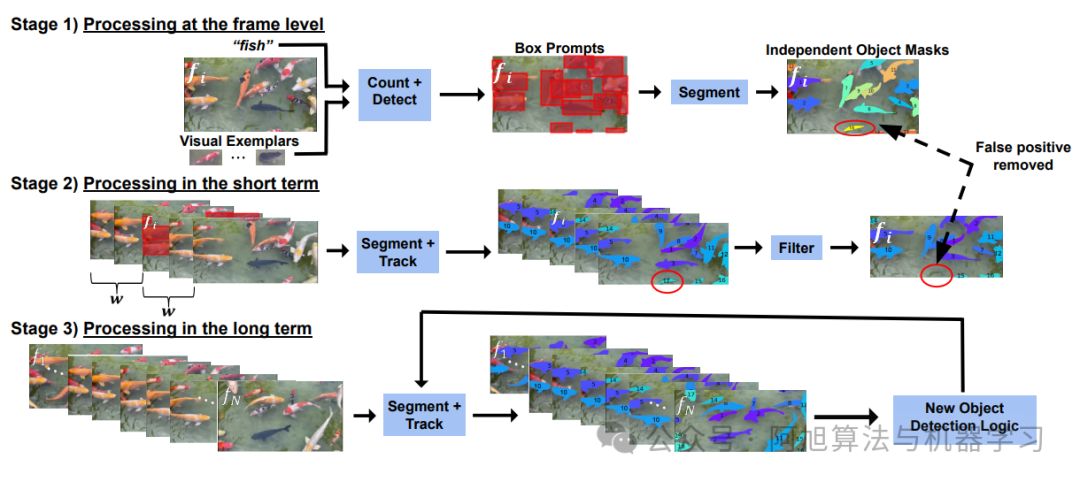
在这里插入图片描述
-
阶段1:逐帧检测(密集场景处理优化)
-
阶段2:短时滤波(消除瞬时误检)
-
阶段3:长时追踪(解决物体重现识别)
创新性提出时间窗口验证机制(w=3帧),误检率降低50%
创新点2:COUNTGD-BOX改进

3. 性能对比
| 测试集 | 基线(MASA) MAE | COUNTVID MAE | 提升幅度 |
|---|---|---|---|
| TAO-Count | 14.1 | 2.6 | 81.6% |
| MOT20-Count | 630.0 | 50.0 | 92.1% |
| Science-Count | 9.0 | 0.3 | 96.7% |
关键突破:
-
在1200+物体的极端拥挤场景仍保持稳定
-
处理变形物体(如金属晶体生长)准确率超96%
4. 应用场景
-
生态保护:无人机航拍动物种群统计(企鹅监测效率提升30倍)

在这里插入图片描述
-
材料科学:X射线视频中的晶体形成过程分析
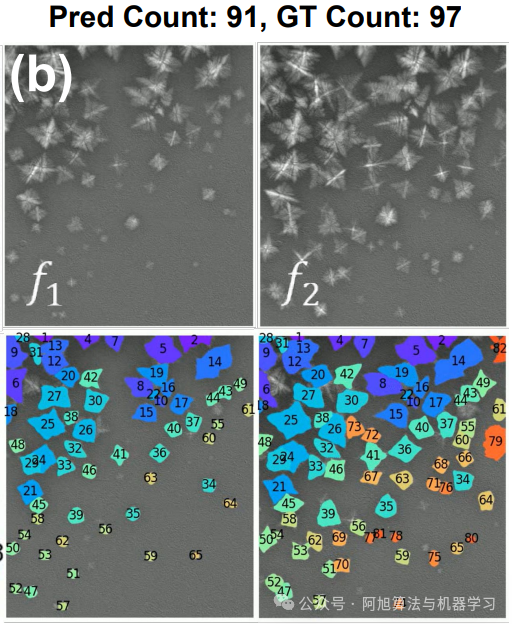
-
智慧城市:街道人车流量统计(流行病学研究支持)

-
工业检测:生产线产品计数与质量监控
5. 总结
COUNTVID开创了视频开放世界物体计数的新范式:
-
发布VIDEOCOUNT数据集(370段视频,141类物体)
-
支持多模态输入(文本+视觉示例)
-
代码已开源:https://github.com/niki-amini-naieni/CountVid/
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









