






本文来源公众号“阿旭算法与机器学习”,仅用于学术分享,侵权删,干货满满。
原文链接:超越T-Rex!UMatcher一个面向边缘设备的轻量级现代模板匹配模型
摘要
核心作用:只需单个提示框即可对多张图片上的相似目标进行模版匹配标注。


移动的设备在计算能力方面存在固有的局限性,这对部署强大的视觉系统提出了挑战。传统的模板匹配方法是轻量级的,易于实现,但缺乏鲁棒性,可扩展性和适应性-特别是在多尺度场景中-并且通常需要昂贵的手动微调。相比之下,现代基于视觉的检测器,如 DINOv 和 T-REX,具有很强的泛化能力,但由于其半专有架构和高计算需求,不适合低成本的嵌入式部署。
为了解决这一权衡问题,我们引入了 UMatcher,这是一种新颖的框架,旨在在边缘设备上进行高效且可解释的模板匹配。UMatcher 结合了:
一种产生可解释和可区分模板嵌入的双分支对比学习架构
轻量级 MobileOne 骨干网,通过 U-Net 风格的特征融合进行增强,以优化设备上的推理
单次检测和跟踪,平衡模板级鲁棒性和实时效率
这种协同设计方法在经典模板方法和现代深度学习模型之间取得了实际平衡-在资源受限的平台上提供可解释性和部署可行性。
DINOv,T-Rex,视觉提示
在边缘设备上部署模型时,我们经常会遇到需要少量检测或跟踪的场景。在这个领域,一个流行的解决方案是 YOLO-World,它最近获得了很多关注。然而,YOLO-World 从根本上被设计为基于语言提示的开放词汇检测器。在现实世界的应用中,这可能成为一个限制-许多目标根本无法单独使用语言准确描述。
为了应对这一挑战,IDEA 团队提出了 DINOv 和 T-REX 系列,它们引入了视觉提示,以提供更精确和可控的目标规格。俗话说,“一张图片胜过千言万语”--这些方法通过采纳这一原则取得了重大进展。
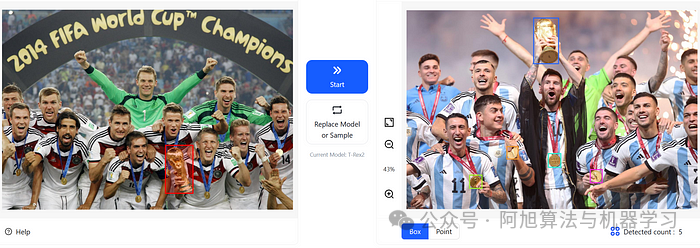
img
T-REX网络演示 :尽管 T-REX 令人印象深刻,但我们最终必须回到日常工作的现实中,考虑如何将其强大的检测能力应用于我们自己的项目。在我的案例中,重点是在移动的设备上部署嵌入式视觉模型,以执行特定的检测任务。
实际需求、应用限制和模板匹配
新版本的 DINOv1.5 为移动的部署引入了一些优化。例如,在 NVIDIA Orin NX 上,它可以在 640×640 的分辨率下实现约 10 FPS 的推理速度。然而,该模型目前似乎是半闭源的 ,只提供 API 级别的访问。
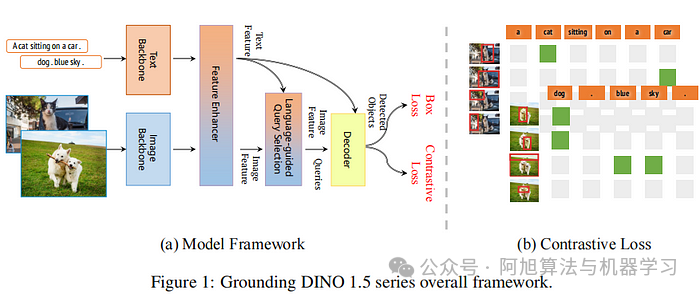
img
DINOv1.5 模型架构
DINO模型的应用挑战
DINO的训练需要大规模数据集和强大计算资源,对资源有限的项目不友好。T-REX的测试结果显示其在假阴性和假阳性方面仍需改进,团队建议将其作为自动注释工具而非直接部署的检测器。实际应用中,用户需通过知识蒸馏训练轻量级定制模型。
实时性能与硬件限制
DINOv1.5的边缘版本在NVIDIA Orin NX上仅能达到约10 FPS,无法满足实时需求。成本敏感项目更倾向于使用嵌入式平台(如SX 1684、RK 3588或Raspberry Pi),但这些平台的计算能力限制了大型模型的部署。
实际任务需求分析
许多应用场景(如固定角度检测、特定对象识别)仅需简单可靠的检测能力,而非通用模型的全部功能。这类任务更强调速度、可靠性和集成度,通常采用模板匹配等轻量级方案。
模板匹配的局限性与改进
传统像素级模板匹配(如NCC或OpenCV的matchTemplate)鲁棒性不足,常需结合SIFT、ORB或滑动窗口等技术增强性能,但调试成本较高。当前技术更倾向于开发鲁棒性更强、更符合人类视觉感知的模板匹配方案,尽管其泛化能力可能不及DINO等大型模型。
UMatcher
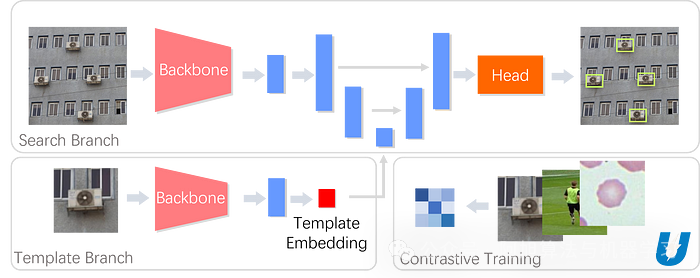
UMatcher 是一个现代化的模板匹配模型,专为解决上述挑战而设计。该模型从 SiamFC 等单目标跟踪体系结构中汲取灵感,采用模板分支和搜索分支组成的双分支设计。
在推理过程中,模板图像被送入模板分支并被处理成模板嵌入向量。同时,搜索图像通过搜索分支进行特征提取。然后,这些特征在随后的 U-Net 结构中融合。
最后,检测头(注意:这不是基于 Transformer 的 DETR 架构,需要使用非最大值抑制进行后处理)产生匹配结果。
一个关键的亮点是,在培训期间,模板分支纳入了对比学习。这使得提取的模板嵌入向量具有高度的可解释性和灵活性,从而开辟了几个实际应用:
通过求平均来聚合多个模板嵌入,以获得更稳定的检测结果;
通过计算余弦相似度或与 KNN 分类器集成,独立使用模板分支进行分类任务;
跟踪过程中实时监测目标外观变化,辅助跟踪策略的动态调整。
这种解释和灵活利用模板嵌入的能力是 UMatcher 区别于传统模板匹配方法的核心功能之一。
移动友好设计
此外,模型设计特别考虑了移动的设备和 NPU 上的部署要求:
主干选择:该模型使用苹果的 MobileOne 作为主干。重新参数化后,MobileOne 只保留标准卷积(Conv)和 ReLU 激活,避免了 Dependency Conv 或 SE 模块等专门的运算符。这对于具有专用 NPU 加速平台的设备(如 RK 3588)尤其有益,因为 Conv 和 ReLU 是基本运算符,通常在大多数 NPU 上得到原生支持和高度优化。相比之下,专门的运算符通常效率较低,甚至可能需要开发人员实现自定义 CPU 回退代码。
功能融合设计:功能融合采用 U-Net 结构,也针对部署进行了优化。与许多依赖于动态卷积或相关运算的单对象跟踪模型不同,UMatcher 的 U-Net 仅使用基本运算符,如级联(Concat)、卷积(Conv)、转置卷积(ConvTranspose)、ReLU 和最终 sigmoid 激活。
这种简单的架构仅依赖于广泛支持的基础运营商,大大降低了配备特定 NPU 的移动的平台上的部署复杂性和成本,同时充分利用了平台供应商提供的最成熟、最高效的优化解决方案。
综合训练数据
关于训练数据,UMatcher 主要依靠合成数据进行训练。该模型可以使用 COCO 或 SA-1B(或其子集)等数据集进行端到端训练。

img
合成训练数据示例(模板、搜索图像1、搜索图像2)
分析合成数据样本(如图所示),两个关键的设计特征脱颖而出:
支持存在检测:该数据集包括数量增加的不包含目标对象的搜索图像(在图中用蓝框标记),表示不存在匹配目标的情况。
支持多对象场景:单个搜索图像可能包含多个目标(红色框表示地面实况注释(GT),绿色和青色框表示模型预测(PD),绿色马赛克区域显示预测的热图分布)。这种设计与典型的单对象跟踪数据集(通常只包含一个目标)形成对比,旨在使 UMatcher 能够有效地执行检测和计数任务。
最终的测试结果如下-- UMatcher 成功实现了单目标检测和单目标跟踪。 单次目标检测效果:

对象跟踪效果:

(Note:对于高分辨率图像的检测,使用了图像金字塔和滑动窗口的组合;对于跟踪,结合了简单的卡尔曼滤波器。)
总结
UMatcher 代表了传统模板匹配和现代目标检测器之间的实用中间地带,为移动的部署提供了强大的适应性。
项目地址: https://github.com/aemior/UMatcher
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1407
1407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









