






本文来源公众号“阿旭算法与机器学习”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/mt-DODLsEWmQYdPI0Jx0Gg
引言

在这里插入图片描述
SAM 3是一款视觉大模型,可基于概念提示(短名词短语、图像示例或两者结合)在图像和视频中检测、分割并跟踪目标,核心任务为可提示概念分割(PCS);其通过共享视觉骨干网络的检测器与基于内存的跟踪器架构,引入存在头(Presence Head) 解耦识别与定位以提升检测精度,同时构建了包含400万独特概念标签的高质量数据集及SA-Co基准测试集;实验表明,SAM 3在图像和视频PCS任务上性能较现有系统提升2倍,在交互式视觉分割任务上也优于前代SAM,并开源了模型与基准测试集,在H200 GPU上单图像(含100+检测目标)推理耗时30ms,视频中支持约5个目标近实时跟踪。
一、SAM 3模型核心定位与任务定义
-
模型定位:SAM 3是一款统一模型,可在图像和视频中基于概念提示完成目标的检测、分割与跟踪,同时兼容前代SAM的交互式视觉分割(PVS)任务,实现对“任意概念”的视觉理解。
-
核心任务:可提示概念分割(PCS)
-
输入:短名词短语(如“yellow school bus”)、图像示例(单帧正负边界框)或两者结合。
-
输出:所有匹配概念的分割掩码及唯一目标标识,视频中需保持目标跨帧身份一致性。
-
任务特点:限制文本为简单名词短语,解决概念歧义(如“small window”的主观性),支持用户通过优化提示调整输出。
-
二、SAM 3模型架构设计
1. 整体架构
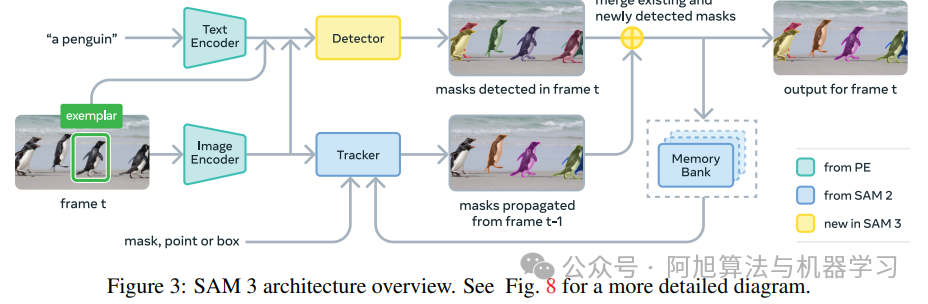
在这里插入图片描述
-
共享组件:采用Perception Encoder(PE) 作为视觉骨干网络,同时服务于图像检测器与视频跟踪器,确保视觉-语言特征对齐。
-
核心模块:分为图像级检测器与基于内存的视频跟踪器,解耦检测与跟踪任务以避免目标身份冲突(检测器无需关注身份,跟踪器需区分身份)。
2. 关键组件细节
| 组件 | 核心功能 | 创新点/关键设计 |
|---|---|---|
| 检测器 | 处理图像级PCS任务,输出实例掩码、边界框 | 1. 基于DETR架构,支持文本、几何、图像示例输入; |
| 存在头 | 预测概念在图像/帧中的存在性(p(NP存在)) | 1. 全局存在令牌仅负责“是否存在”,目标查询仅负责“定位”; |
| 跟踪器 | 视频中传播掩码、匹配新检测目标,保持目标身份 | 1. 继承SAM 2传播机制,基于历史帧特征构建内存库; |
| 交互式优化 | 支持图像示例与视觉提示(点、框)迭代优化掩码 | 1. 图像示例:通过正负边界框补充提示; |
3. 训练阶段
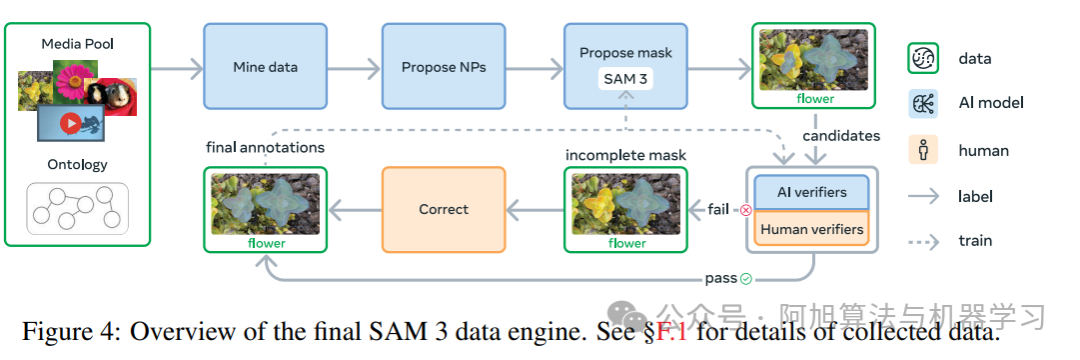
在这里插入图片描述
SAM 3分4阶段渐进式训练,各阶段目标与数据如下表:
| 训练阶段 | 核心目标 | 关键数据/设置 |
|---|---|---|
| 阶段1:PE预训练 | 预训练图像与文本编码器,实现宽概念覆盖与鲁棒性 | 54亿图像-文本对,视觉编码器4.5亿参数,文本编码器3亿参数 |
| 阶段2:检测器预训练 | 训练图像检测器,兼顾PCS与PVS任务基础能力 | 大规模图像分割数据(含视频帧),PVS任务限制4步交互,使用Align损失 |
| 阶段3:检测器微调 | 提升检测精度,引入存在头,扩展交互能力 | 仅保留高质量数据(如SA-Co/HQ),PVS任务扩展至7步交互,学习率降低0.025倍 |
| 阶段4:跟踪器训练 | 训练视频跟踪器,保持空间定位能力不退化 | 冻结PE骨干,使用16帧/32帧视频训练,余弦学习率调度(1k步预热) |
三、数据引擎与数据集构建
1. 数据引擎:4阶段迭代流程
数据引擎通过“模型-人类-AI”反馈循环生成高质量标注数据,核心目标是覆盖更多概念与视觉领域,各阶段特点如下:
| 阶段 | 核心工作 | 关键成果 |
|---|---|---|
| 阶段1:人类验证 | 随机采样图像,BLIP-2生成名词短语,SAM 2生成掩码,全人工验证(质量+完整性) | 120万图像,430万图像-名词短语对,构建初始SA-Co/HQ数据集 |
| 阶段2:人类+AI验证 | 微调Llama 3.2作为AI验证器(替代部分人工),生成难例负样本 | 240万图像,1.222亿图像-名词短语对,吞吐量提升2倍,SAM 3性能提升至CGF₁ 38.4 |
| 阶段3:规模化与领域扩展 | AI挖掘难例,扩展至15个视觉领域,提取长尾/细粒度概念 | 160万图像,1950万图像-名词短语对;生成SA-Co/SYN(3940万图像,17亿掩码) |
| 阶段4:视频标注 | 筛选挑战性视频(如拥挤场景),采样帧用图像引擎标注,人工修正跟踪掩码 | 5.25万视频,13.43万视频-名词短语对(SA-Co/VIDEO),SAM 3视频pHOTA达48.1 |
2. 核心数据集与SA-Co基准测试集
(1)训练数据集
| 数据集 | 规模 | 特点 |
|---|---|---|
| SA-Co/HQ | 520万图像,400万独特名词短语,5200万掩码 | 高质量标注,人工/AI验证,覆盖15个领域 |
| SA-Co/SYN | 3940万图像,3800万独特名词短语,14亿掩码 | 纯AI生成,基于MetaCLIP图像与Llama4 caption,含难例负样本 |
| SA-Co/EXT | 930万图像,1.366亿图像-名词短语对 | 18个外部数据集增强,生成掩码(如用SAM 2处理边界框),补充负样本 |
| SA-Co/VIDEO | 5.25万视频,2.48万独特名词短语,46.7万掩码 | 人工验证,聚焦跟踪挑战场景(如遮挡、快速运动) |
(2)SA-Co基准测试集
-
核心规模:21.4万独特概念,12.6万图像/视频,300万+媒体-概念对,含大量难例负样本。
-
主要子集:
-
SA-Co/Gold:7个领域,每图像-概念对3个人工标注(用于衡量人类性能)。
-
SA-Co/Silver:10个领域,每图像-概念对1个人工标注。
-
SA-Co/VEval:视频基准,3个领域(SA-V、YT-Temporal-1B、SmartGlasses),每视频-概念对1个标注。
-
-
评估指标:
-
CGF₁(分类门控F1):核心指标,=100×pmF₁×IL MCC,综合定位与分类性能。
-
pmF₁(正样本宏F1):评估定位精度,平均0.5-0.95 IoU阈值结果。
-
IL MCC(图像级马修相关系数):评估分类能力(目标是否存在),范围[-1,1]。
-
四、关键实验结果与性能表现
1. 图像PCS任务
| 评估场景 | 关键结果 | 对比基准优势 |
|---|---|---|
| 零样本LVIS掩码AP | 47.0 (现有最佳为38.5) | 超DINO-X(27.7)、Gemini 2.5(18.7) |
| SA-Co/Gold的CGF₁ | 65.0 | 是OWLv2⋆(34.3)的2倍,达人类性能下限88% |
| 开放词汇语义分割(ADE-847) | 超APE(强专业基线) | - |
2. 视频PCS任务
| 基准测试集 | 关键指标 | SAM 3结果 | 最佳基线结果(如GLEE、LLMDet+SAM 3 Tracker) |
|---|---|---|---|
| SA-Co/VEval(SA-V) | CGF₁ / pHOTA | 27.8 / 53.9 | GLEE:0.2 / 8.8;LLMDet+Tracker:3.6 / 31.2 |
| LVVIS测试集 | mAP | 38.2 | GLEE:20.8;SAM 3 Detector+T-by-D:37.3 |
| BURST测试集 | HOTA | 45.9 | GLEE:28.4;SAM 3 Detector+T-by-D:40.7 |
| 人类性能(SA-Co/VEval) | pHOTA | - | 68.0(SAM 3达人类水平80%+) |
3. 其他核心任务
-
交互式图像分割(SA-37基准):1-click mIoU 65.4,5-clicks mIoU 85.0,超SAM 1(1-click 58.5、5-clicks 82.1)与SAM 2。
-
目标计数(CountBench/PixMo-Count):CountBench MAE 0.11、Acc **95.6%**,超Gemini 2.5 Pro(MAE 0.24、Acc 92.4%)。
-
SAM 3 Agent(结合MLLM):零样本在ReasonSeg(gIoU 76.0)、OmniLabel(AP 43.7)达SOTA,支持复杂查询(如“people sitting down but not holding a gift box”)。
4. 推理效率
-
图像推理:H200 GPU处理单图像(含100+检测目标)耗时30ms。
-
视频推理: latency随目标数量线性增长,支持**~5个并发目标**近实时跟踪(30 FPS),多GPU并行可扩展至更多目标(如8 H200支持64个目标)。
五、开源与扩展价值
-
开源内容:SAM 3模型、SA-Co基准测试集、模型检查点及推理代码。
-
扩展能力:
-
领域适配:少量微调即可适配细粒度领域(如医疗、食品),合成数据(SA-Co/SYN)可无人工标注提升新领域性能。
-
多模态协作:与任意MLLM结合(如Qwen2.5-VL、Gemini 2.5 Pro),统一系统提示即可处理复杂语言查询。
-
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 886
886




 到【灌水乐园】发言
到【灌水乐园】发言







