






本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:Meta Dino-V3:适用于每个图像任务的终极视觉AI

我关注 DINO 系列模型已经有一段时间了。主要是因为它们得到了许多视觉模型甚至没有尝试过的事情:在没有监督的情况下为您提供密集的特征。
DINOv1 很酷。DINOv2 掀起了波澜。DINOv3 呢?
这是 Meta 试图构建一个视觉基础模型,该模型可以学习它需要了解的有关图像的所有信息......没有单一标签。它确实有效。

没有标签。没有微调。仍然是 SOTA。
让我们从它最擅长的事情开始。DINOv3 不仅仅学习全局内容,例如“这是一只猫”与“这是一台烤面包机”。
它学习密集的特征。含义:图像中的每个补丁、每个区域都带有语义上有意义的东西。
这对于分割、对象跟踪、深度估计、3D 匹配等内容来说是巨大的。所有这些都无需微调。您只需冻结模型并使用输出即可。
这是我见过的第一个在密集任务上真正击败 CLIP 或 SAM 等模型的 SSL 模型,尽管这些模型是通过监督或文本标签进行训练的。

大规模构建:7B 参数,从头开始
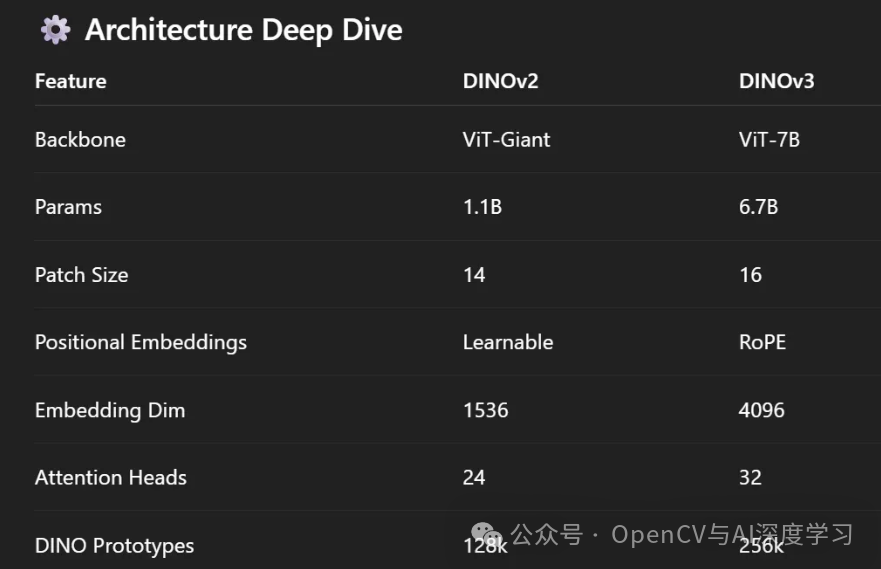
核心模型是 70 亿参数的 Vision Transformer (ViT-7B)。这不是你在笔记本电脑上随意运行的东西,但 Meta 做到了。他们没有使用 JFT-300M 或 LAION、标签或 Web 元数据。只是原始图像,其中 170 亿张,是从 Instagram 上抓取的

而且也不是随机扔在一起的。他们使用以下方法整理数据:
分层 k 均值聚类,确保视觉多样性
基于检索的抽样,以获得概念上相关的样本
加入一点 ImageNet 以实现平衡
因此,这不是“将所有东西都倾倒到训练箱中”的方法。它经过调整、平衡且大。

致密特征无塌陷,革兰氏锚定
这是具有密集特征的东西。训练模型的时间过长,尤其是大型模型,您的补丁特征就会开始变得奇怪。噪声过多。过于光滑。有时他们只是崩溃了。
为了阻止这种情况,Meta 引入了一种叫做 Gram Anchoring 的东西。
什么是Gram Anchoring?
这是一种新型的损失函数,它迫使补丁特征之间的相似性结构在长时间训练期间保持稳定。基本上,该模型将其当前的补丁相似性与早期、更一致的检查点的补丁相似性进行比较。它不在乎特征是否稍微漂移,只要补丁之间的关系保持干净即可。
这个技巧修复了影响 DINOv2 和其他 SSL 模型的功能降级。它可以解锁长时间训练,即使是在 7B 参数庞然大物上也是如此。

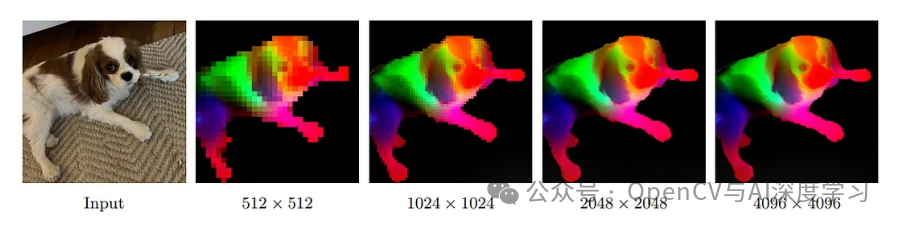
适用于高分辨率输入

大多数模型都以 224x224 或 256x256 分辨率进行训练。但随后人们向他们投掷 1024 像素的图像,并期望清晰的分割。除非你调整模型,否则不会发生。
DINOv3 获得训练后高分辨率调优阶段。它们以 512、768 甚至更高的速度喂入作物,并使用 Gram 锚定调整模型。这使得模型在分辨率上向上泛化。
所以现在你可以向它投掷 4K 分辨率的卫星图像、航空地图或密集的街景,而且它不会分崩离析。您仍然可以在图像中获得可用的功能。
Frozen Backbone,许多任务,无需微调。
一旦训练完毕,DINOv3 就......工程。你不会微调。你不加头。你运行它,冻结输出,然后应用简单的线性层或KNN或光簇。就是这样。
以下是 DINOv3 表现得非常好的任务类型:
-
-
语义分割: ADE20k、Cityscapes、Pascal VOC,全部只需线性探头即可处理
-
单眼深度估计: 在 NYUv2 和 KITTI 等数据集上
-
3D对应匹配: 多视图一致性保持清晰,这有助于处理几何形状较多的内容
-
物体跟踪和视频理解: 贴片功能在帧间保持稳定
-
在所有这些中,它的性能都优于 DINOv2、CLIP 风格的模型(如 SigLIP),甚至是最近的 AM-RADIO,它将 SAM + CLIP + DINOv2 合二为一。
蒸馏正确完成
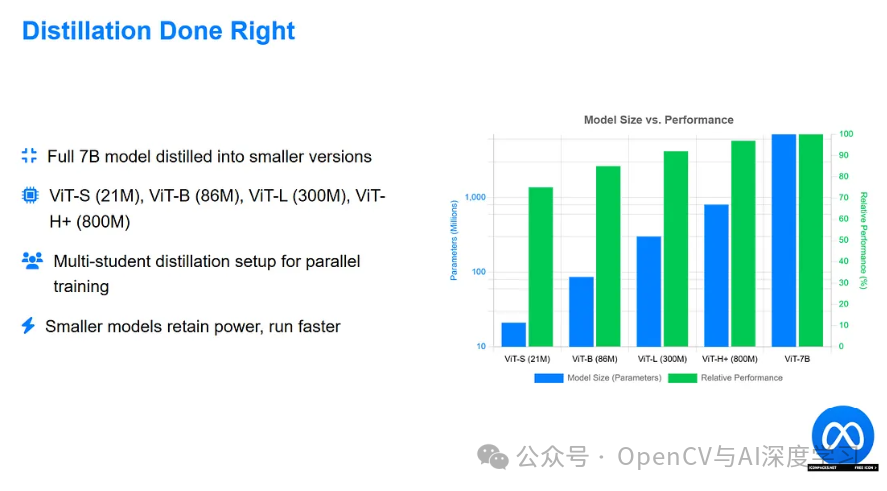
如果你有果汁,完整的 7B 型号很棒。但 Meta 也将其提炼成实际可用的更小模型:
-
-
ViT-S(21M 参数)
-
ViT-B (86M)
-
ViT-L (300M)
-
ViT-H+ (800M)
-
他们甚至构建了一个多学生蒸馏设置,使他们能够并行训练所有这些学生,跨 GPU 重用教师的输出。智能使用计算。这些较小的型号保留了 7B 的大部分动力,尤其是在密集任务中。而且他们跑得很快。
如果需要,请添加文本
模型本身是纯粹的视觉。但是,如果您想要零样本分类或检索,您可以安装文本编码器。他们使用对比物镜(如 CLIP)将合并的视觉 + 补丁特征与文本对齐,同时保持视觉主干冻结。
这为您提供了全局 + 局部对齐,因此您不仅可以匹配“猫”,还可以在补丁级别匹配“条纹尾巴”或“胡须”。
为什么这个模型实际上很重要
这就是为什么 DINOv3 不仅仅是基准图表上的另一个凸起:
-
-
它打破了监督的需要。没有标签,没有替代文本,没有人机交互。只是原始像素。
-
它以同等的强度处理密集和全局任务。大多数模型都会选边站。这不是。
-
它可以扩展。训练不会在 7B 时崩溃。功能质量不会随着时间的推移而降低。
-
它概括了。适用于自然图像、鸟瞰图、医学扫描、生物学数据集,无需针对特定任务的微调。
-
它并不完美。您仍然需要一些 GPU 肌肉。但对于任何认真构建模型而不仅仅是使用其他人的 API 的人来说,DINOv3 是一个里程碑。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









