





DINOv3是Meta在自监督计算机视觉领域推出的一个先进模型。它最大的特点是能够不依赖人工标注的数据,通过自监督学习的方式从海量图像中学习通用的视觉表示。这意味着它可以有效地减少数据标注的成本和时间,并且模型包含丰富的图像特征以及高密度特征,该模型在包括图像分类、目标检测、语义分割等多种视觉任务上都展现了强大的性能,甚至在一些任务上超越了专门为该任务设计的模型,其产生的高分辨率视觉特征使得轻量级的适配器易于训练,在图像分类、语义分割和视频中的物体追踪方面表现卓越。
Github:https://github.com/facebookresearch/dinov3/tree/main
Paper:https://arxiv.org/abs/2508.10104
一、模型整体介绍
DINOv3 的自监督学习实现确实巧妙,它通过让模型自己从图像中寻找学习信号,省去了大量人工标注的辛苦工作。
1.1 核心学习框架:自我蒸馏(Self-Distillation)
DINOv3 的核心框架基于 自我蒸馏。这个过程主要涉及两个网络:学生网络 (Student Network) 和 教师网络 (Teacher Network)。它们的结构相同,但参数更新方式不同。
-
学生网络:通过梯度下降进行正常的参数更新。
-
教师网络:其参数是学生网络参数的指数移动平均(EMA)。这意味着教师网络的更新更平滑,能提供更稳定、更可靠的目标信号。
其基本流程是通过自我蒸馏让模型学会提取一致的特征表示,可以通过下面的图示来直观地理解:
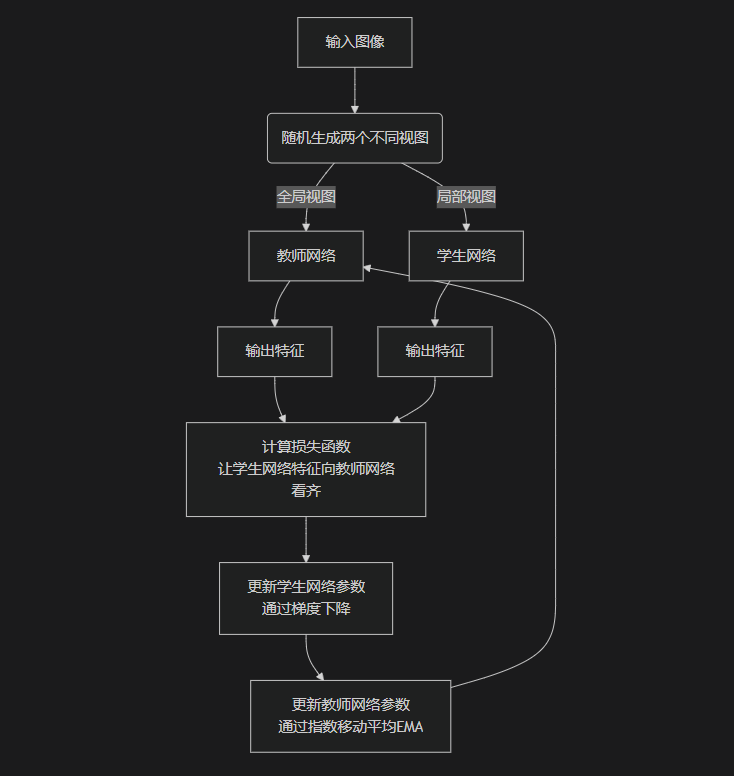
这个过程的核心目的,是让模型学会“看到局部就能联想到全局”,从而理解物体的组成部分和整体结构,最终学习到非常强大的语义特征。
1.2 关键技术助力稳定高效训练
为了应对大规模训练中的挑战(如特征退化、多分辨率适应等),DINOv3 引入了几项关键技术:
-
Gram Anchoring:这是 DINOv3 的一项关键创新。在长时间训练大规模模型时,patch-level 的特征可能会出现退化(即不相关的图像块之间特征变得相似),这会影响分割等密集预测任务的性能。Gram Anchoring 通过约束学生模型的特征 Gram 矩阵(表征特征间相关性)与早期训练阶段表现良好的教师模型的 Gram 矩阵保持一致,来缓解这个问题。它保持了 patch 间的相对相似性,而不限制特征本身的自由表达,从而在不过度牺牲全局特征质量的前提下,显著提升了密集特征的质量和训练稳定性。
-
旋转位置编码(RoPE):DINOv3 采用了 RoPE (Rotary Position Embedding) 来编码图像块的位置信息。RoPE 能更好地处理不同分辨率和长宽比的图像输入,提高了模型对尺度变化的鲁棒性。
-
多目标损失函数:DINOv3 的训练目标融合了多种损失函数,形成一个更全面的学习信号:1)DINO 损失:基于自我蒸馏,促使不同视角的特征保持一致;2)iBOT 损失:在图像块级别引入掩码建模,要求模型预测被掩码的图像块的特征,这有助于学习更细粒度的局部特征;3)GRAM损失:防止在长时间、大规模的训练后期会出现高密度特征坍缩;
1.3 大规模数据与模型架构
-
数据集 (LVD-1689M):DINOv3 在一个包含约 17 亿张图像的大规模数据集上进行训练。这些图像主要来自 Instagram 的公开图片,并经过了严格的数据清洗和去重流程(包括聚类筛选和检索筛选),以确保数据质量。
-
模型架构:DINOv3 主要基于 Vision Transformer (ViT)架构。其模型规模从 ViT-S(2100万参数)到庞大的 ViT-7B(70亿参数)。ViT-7B 采用了 SwiGLU 激活函数。所有模型都使用了 register tokens(通常为4个),这些可学习的向量有助于减少特征图中的高范数伪影,对密集预测任务尤其有益。
1.4 训练流程
DINOv3大致可分为三个阶段:
-
预训练阶段:使用相对较低的分辨率(如 256x256)在大规模数据集上进行自监督学习,应用上述的自我蒸馏框架和多目标损失。
-
Gram Anchoring 阶段:在预训练基础上引入 Gram Anchoring 技术,以稳定密集特征的学习并防止其退化。
-
高分辨率适应阶段:使用混合分辨率策略(同时使用不同分辨率的图像)和 Gram Anchoring,让模型适应更高分辨率的输入(如 512x512 甚至更高),同时保持性能稳定。这使得 DINOv3 能够输出高质量的高分辨率特征。
1.5 下游任务应用
DINOv3 学到的视觉特征非常通用和强大。在下游任务(如图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









