 Inter2Former让CPU实现高精度分割提效
Inter2Former让CPU实现高精度分割提效







本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:干翻SAM,CPU也能玩转高精度分割 | Inter2Former四大创新模块让密集Token处理速度飙升2.25倍

精简阅读版本
本文主要解决了什么问题
-
1. 交互式分割中密集 Prompt Token 的计算效率问题:尽管密集 Prompt Token 能够提升分割精度和细节保留能力,但其在CPU设备上的推理速度较慢,限制了其在大规模众包标注等资源受限场景中的应用。
-
2. 高精度与高效率之间的权衡问题:现有的主流方法如 Segment Anything Model(SAM)采用 Sparse Prompt Token 实现了快速推理,但牺牲了分割质量;而 InterFormer 等方法虽然精度高,但效率低。
-
3. 交互式分割过程中计算资源的不均衡分配问题:现有方法在处理过程中对所有 Token 均匀分配计算资源,未针对目标边界区域进行优化,导致整体效率和精度的次优。
本文的核心创新是什么
-
1. 动态 Prompt 嵌入(DPE):通过动态裁剪感兴趣区域,避免处理背景 Token 的计算开销,从而提升效率。
-
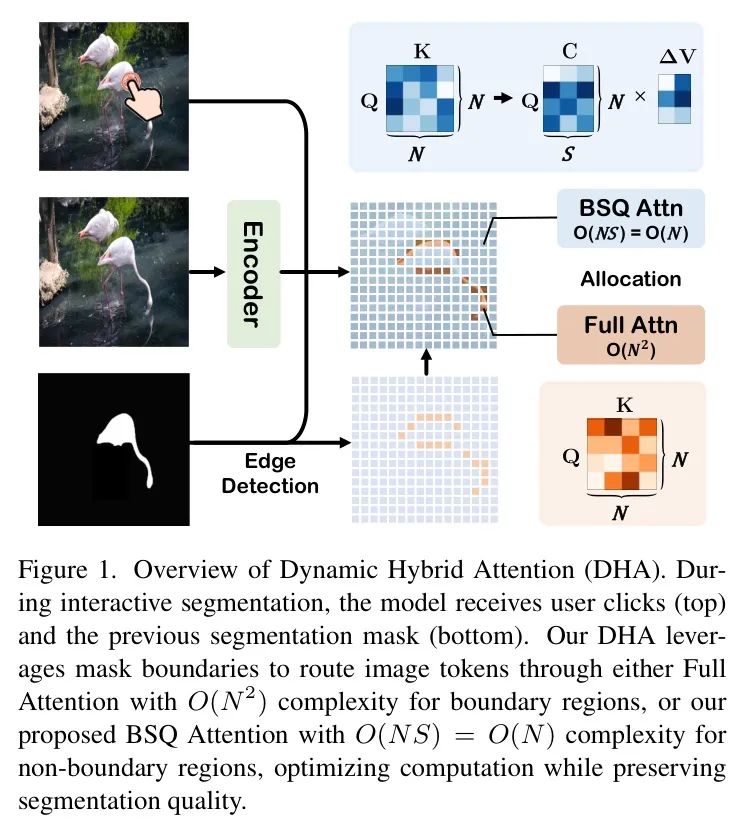
2. 动态混合注意力(DHA):根据边界信息将 Token 路由至全注意力(O(N²))或轻量级的 BSQ 注意力(O(N)),实现计算资源的差异化分配。
-
3. 混合专家混合(HMoE):在 FFN 模块中引入自适应计算策略,并通过 Token 重排优化 CPU 上的并行 MoE 计算,显著降低推理延迟。
-
4. 动态局部上采样(DLU):作为 DPE 的逆操作,仅在检测到的目标区域执行细粒度上采样,减少不必要的计算。
-
5. BSQ 注意力机制(BSQA):基于二进制球面量化(BSQ)提出新的注意力机制,在保持性能的同时实现线性复杂度。
结果相较于以前的方法有哪些提升
-
1. 在 CPU 设备上实现了 SOTA 性能:Inter2Former 在高精度交互式分割基准(如 HQSeg-44K、DAVIS)上取得了最先进的分割精度,如更低的 NoC@90/95 和更高的 5-mIoU。
-
2. 推理效率显著提升:
-
• HMoE 相较于普通 MoE 实现,在 CPU 上推理时间减少了 56% 至 85%。
-
• Inter2Former 在与 InterFormer 相比时,显著降低了推理时间,同时保持了更高的精度。
-
-
3. 兼顾高精度与高效推理:在与基于 Sparse Prompt Token 的模型(如 SAM、HRSAM++)对比时,Inter2Former 在精度上显著领先;在与基于密集 Token 的模型(如 SegNext)对比时,保持了更高的效率。
本文的局限性
-
1. 依赖高质量的边界检测信息:DHA 和 DLU 的性能在很大程度上依赖于前一步分割结果的边界质量,若初始边界不准确,可能影响后续计算分配和上采样效果。
-
2. 模型复杂度较高:多个模块(DPE、DHA、HMoE、DLU)的引入增加了模型结构的复杂性,可能影响实际部署和维护。
-
3. 对 CPU 并行化依赖较强:虽然在 CPU 上表现优异,但其优化策略(如 Token 重排)可能难以直接迁移到其他硬件平台(如 GPU 或边缘设备)。
-
4. 训练复杂度较高:由于引入了 BSQA、HMoE 等新机制,训练过程需要额外的策略(如量化注意力训练、蒸馏),可能增加训练成本和调参难度。
深入阅读版本
导读
交互式分割(IS)通过从用户 Prompt 中分割目标区域来提高标注效率,在现实场景中具有广泛应用。当前方法面临一个关键权衡:密集 Token 方法虽然能够实现更高的精度和细节保留,但在CPU设备上处理速度过慢;而Segment Anything模型(SAM)则通过Sparse Prompt Token 实现了快速推理,但牺牲了分割质量。本文提出Inter2Former通过优化密集 Token 处理中的计算分配来应对这一挑战,引入了四个关键改进。首先,作者提出了动态 Prompt 嵌入(DPE),能够自适应地仅处理感兴趣区域,同时避免来自背景 Token 的额外开销。其次,作者引入了动态混合注意力(DHA),利用先前的分割 Mask 将 Token 路由到全注意力(O(N^2))(用于边界区域)或作者提出的BSQ注意力(O(N^2))(用于非边界区域)。第三,作者开发了混合专家混合(HMoE),在FFN模块中应用类似的自适应计算策略,并采用CPU优化的并行处理。最后,作者提出了动态局部上采样(DLU),这是DPE的逆向操作,通过轻量级MLP定位目标,并在检测到的区域仅执行细粒度上采样。在用于高精度IS基准的实验结果表明,Inter2Former在CPU设备上实现了高效且SOTA的性能。
1. 引言
交互式分割(IS)[5, 18, 23, 32]通过从少量标注者 Prompt 中分割感兴趣区域,极大地提升了图像分割标注流程。这些方法扩展了图像分割在现实世界中的应用,例如医学影像[2]、工业缺陷检测[3]和自动驾驶[4]。近年来,Segment Anything Model(SAM)[23]成为IS领域的里程碑,在实时、高质量的分割方面表现出色,尤其是在主流基于点击的IS中。
SAM [23] 和 InterFormer [18] 同时为该任务引入了一种类似的二阶段流程:一个预处理阶段,使用编码器将图像编码为token,随后是一个交互阶段,解码器处理这些token以及用户 Prompt 来生成分割 Mask 。虽然这些模型共享相似的编码器,但在解码器设计上存在显著差异。InterFormer [18] 将点击转换为密集 Prompt token以增强空间感知能力,并实现更优的分割精度。然而,这种方法导致高计算成本,使其在CPU设备上运行速度极慢,对大规模众包标注且GPU资源有限的场景构成了显著限制。相比之下,SAM [23] 使用Sparse Prompt token进行高效的交叉注意力机制和更快的推理,但牺牲了空间感知能力和边界精度。随后,SegNext [34] 通过引入密集 Prompt token改进了SAM的解码器,提升了精度但进一步增加了计算需求。HRSAM [19] 专注于升级SAM的编码器,同时保留其高效但精度较低的Sparsetoken解码器。尽管采取了这些措施,但在计算约束下实现高精度交互式分割仍然具有挑战性 [19, 34],特别是在高分辨率图像中,性能与效率的权衡更为严重。
为解决上述挑战,作者研究了一种基于密集 Prompt Token 的方法[18, 34],同时保持高效的推理能力。作者观察到密集 Prompt Token 的低效性源于交互式分割(IS)过程中资源分配的次优性。具体而言,现有模型在整个IS过程中对所有 Token 进行均匀的计算分配。然而,主要目标区域通常在最初的几次点击中确定,而后续大多数用户点击则专注于细化目标边界。因此,计算资源应优先分配给边界区域。这种均匀分配浪费了对已确定的主要目标区域的计算资源,同时对关键边界区域提供的计算资源不足,导致精度和效率的次优性。此外,IS过程中的每一步分割结果都包含边界线索,但现有模型仅将分割结果作为附加特征[18, 23, 24, 32]来优化下一次交互,未能充分利用边界信息进行计算优化。
在本文中,作者介绍了Inter2Former,旨在优化计算分配以实现高效的超高精度图像分割。首先,作者提出了动态 Prompt 嵌入(DPE),通过动态区域裁剪仅处理感兴趣区域,从而避免背景 Token 的计算开销。其次,作者提出了动态混合注意力(DHA),以差异化分配计算资源给动态检测到的边界 Token 和非边界 Token 。在DHA(图1)中,边界 Token 通过传统的全注意力(FA)[45]进行处理,而非边界 Token 则采用作者轻量级的BSQ注意力(BSQA)。作者的BSQA受[30]启发,应用二进制球量化[54]压缩键值对,将非边界 Token 的复杂度从降低至。第三,作者在FFN模块中提出了混合专家混合(HMoE),以动态地将边界和非边界 Token 路由到MoE或传统FFN,以优化计算分配。此外,作者通过重新排列 Token 来优化CPU上的MoE计算,以增强Low-Level矩阵计算并减少延迟。第四,作者提出了动态局部上采样(DLU)以加速 Mask 预测,其功能是DPE的逆操作。DLU首先采用轻量级MLP和Canny算子定位感兴趣区域,然后在这些区域内进行上采样,以最小的计算成本实现细粒度分割。
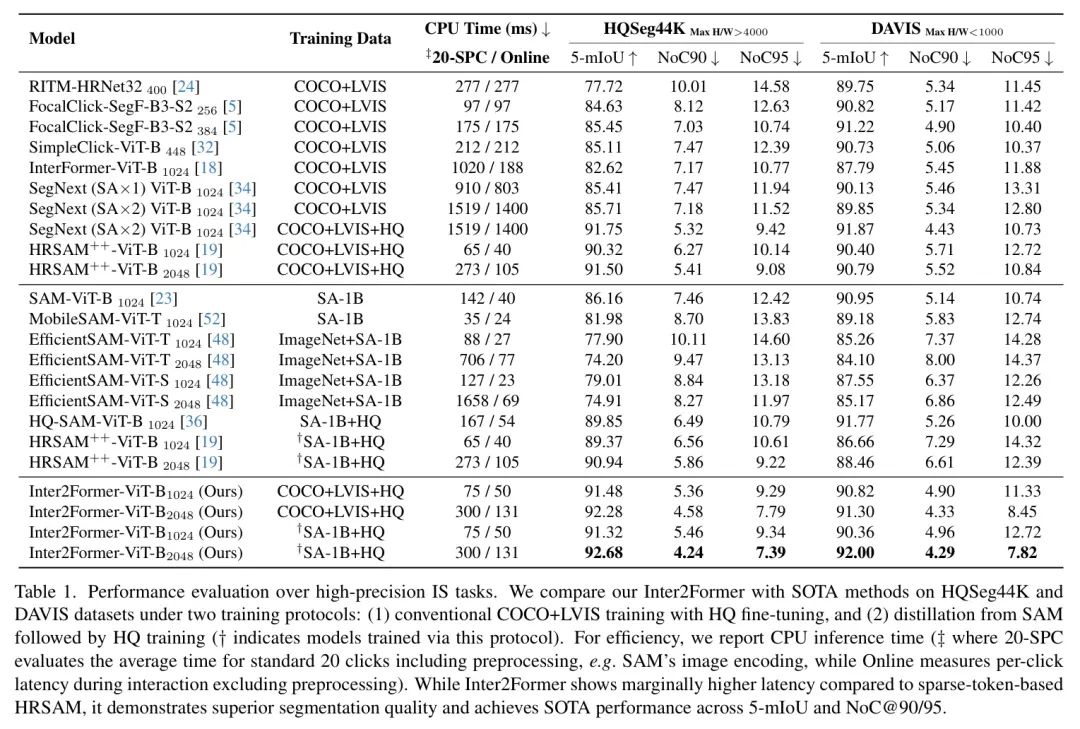
作者在高精度交互式分割基准测试 [19, 21, 34, 40] 上评估了 Inter2Former。Inter2Former在Sparse Token 模型 [19, 23] 上实现了SOTA性能,并略微增加了延迟。CPU优化的HMoE相较于普通的MoE实现将推理时间减少了56%至85%。
作者的主要贡献如下:
-
• 作者提出了DHA,它根据先前的分割结果将 Token 分配给全注意力(FA)或作者新型的BSQ注意力(BSQA),以优化计算分配。
-
• 作者提出了HMoE以实现更好的计算分配,通过 Token 重排优化CPU上的并行MoE计算,相较于普通的MoE实现,将推理延迟降低了56%至85%。
-
• 作者提出了DPE和DLU用于高效的 Prompt 编码和 Mask 预测。DPE动态裁剪感兴趣区域,而DLU通过使用轻量级MLP执行逆操作,识别目标区域以进行选择性上采样和细粒度分割。
-
• Inter2Former在CPU设备上保持高效率的同时实现了SOTA。
2. 相关工作
交互式分割。交互式分割最初在DIOs [50] 中与深度学习相结合,将深度神经网络引入该领域,并建立了主流点击式交互的标准训练和评估协议。后续研究通过提升性能和效率推动了该领域的发展 [1, 5, 18, 20, 27, 29, 32, 33, 37, 42, 49, 53]。SAM [23] 的引入通过特征重用显著提升了推理效率,并启发了众多下游应用 [25, 36, 38]。这一演进导致了高精度交互式分割 [19, 34, 46] 的出现,其旨在精确标注数据集上实现更优的精度 [21, 40]。
向量量化表示学习。向量量化变分自编码器(VQ-VAE)[44]通过可学习的码本量化开创了离散表示学习。后续工作通过感知损失[10]、归一化[51]、隐式码本[39]、分解量化[9]和动态更新[55]等方法解决了码本坍塌问题。尤为突出的是,BSQ[54]通过在超球面上投影和二值化潜在向量,引入了一种无参数方法,为视觉Transformer实现了高效的 Token 化。
高效注意力机制。注意力机制[45]彻底改变了计算机视觉领域[8, 11, 22, 47]。然而,其二次方计算复杂度促使人们不断探索高效解决方案。先前研究通过局部窗口[35]、Sparse模式[13]和层次结构[15, 26]来提升效率。在实现层面,Flash Attention[6, 7]和EMA[41]通过优化的计算调度来减少内存占用。最近,Transformer-VQ[30]通过向量量化表示键,实现了线性时间复杂度,其中注意力计算仅需在 Query 和固定大小的码本之间进行,而非在整个键序列上。
3. 方法
3.1. 背景

3.2. Inter2Former概述
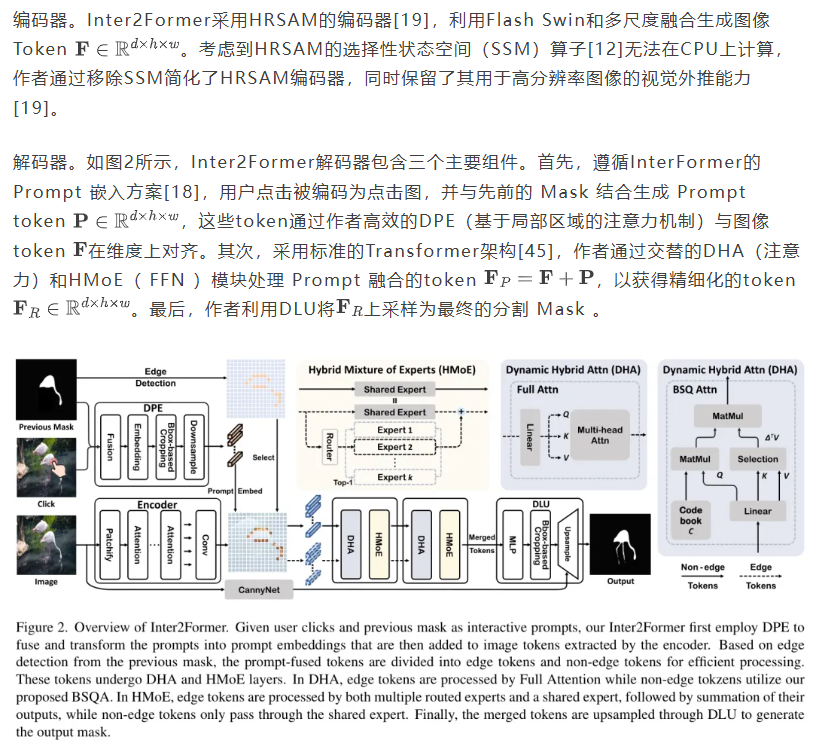
3.3. 动态 Prompt 嵌入

3.4. 动态混合注意力

3.5. 二元球面量化注意力
受VQ-Transformer[30]启发,作者提出了BSQA,通过引入更有效的二进制球形量化(BsQ)方案来增强VQ注意力机制,同时保持其线性时间复杂度。下面作者将分别详细阐述VQ注意力机制、BSQ以及作者提出的BSQA。


3.6. 专家混合混合体


3.7. 动态局部上采样


3.8. 训练策略
BSQA训练。在训练过程中,作者使用公式14在执行完整的FA计算时,仅用量化后的键向量替换注意力计算中的键。这种训练策略鼓励量化后的注意力接近标准注意力的行为。在推理时,作者切换到公式8中的高效计算方案以实现线性时间复杂度。

4. 实验
第4.1节详细介绍了作者的实现。第4.2节描述了数据集和训练协议。第4.3节展示了主要的定量比较。第4.4节分析了作者关键组件的计算效率。此外,作者在补充材料中提供了代码。
4.1. 实现细节

4.2. 实验设置
数据集。基于最近的高精度交互式分割基准测试[19, 34],作者在COCO[28]、LVIS[14]和HQSeg-44K[21]数据集上训练模型。作者在HQSeg-44K验证集和DAVIS[40]上评估模型,这两个数据集都包含高质量标注的 Mask ,用于对高精度IS任务进行严格评估。
训练。遵循先前的高精度IS工作,作者采用两种训练协议进行全面评估。第一个协议遵循[34],作者在COCO和LVIS上训练160K次迭代,然后对HQSeg44K进行40K次迭代的微调。第二个协议涉及从SAM-ViT-Huge[21]进行蒸馏,作者首先使用MSE损失在COCO和LVIS的无标签图像上训练编码器160K次迭代以与SAM特征对齐,然后随机初始化Inter2Former解码器,并在HQSeg44K上训练完整模型80K次迭代。两种协议都利用先前工作的点击模拟[18, 24, 32]和NFL[24]来指导模型从点击生成与GT对齐的分割 Mask 。
评估。遵循标准评估协议[5, 18, 23, 24, 32, 34, 48, 52],在高精度IS任务[19, 34]中,通过NoC@90/95(在20次点击预算内达到90%或95% IoU所需的平均点击次数)和5-mIoU(五次点击后的mIoU)来衡量分割质量。在CPU设备上的效率评估中,作者采用两个指标:20-SPC(每点击秒数)[19]和Online SPC。20-SPC指标测量完成20次点击的平均时间,包括预处理开销(例如SAM方法中的图像编码)。相比之下,Online SPC捕捉交互过程中的单次点击延迟,不包括预处理时间。对于SAM之前的传统IS模型,这两个指标给出相同的值,因为它们不需要预处理步骤。
4.3. 主要结果
如表1所示,Inter2Former在所有评估指标上均实现了SOTA性能,同时保持了具有竞争力的效率。其卓越性能可归因于Inter2Former解码器中的密集 Token 设计。与继承SAM的Sparse Token 解码器的HRSAM++不同,Inter2Former的密集 Token 设计能够从零开始进行更有效的训练,尤其是在使用高质量数据集进行微调时尤为有益。在效率方面,虽然Inter2Former与HRSAM++相比存在略微更高的延迟,但它在与其他高精度方法如SegNext相比时仍保持显著的速率优势,同时实现了更高的精度。此外,Inter2Former在与快速SAM变体如EfficientSAM [48]相比时表现出具有竞争力的效率,并且与InterFormer [18]相比显著降低了推理时间。
4.4. 效率分析
作者使用目标 Mask 标注在COCO数据集上评估了作者提出的DPE、DHA和DLU的计算效率。多样的目标尺度为不同面积比下的效率分析提供了客观基准。此外,作者还分析了HMoE在不同专家数量下的效率。
DPE效率。如图3(a)所示,非DPE(具有相同的卷积架构)的延迟保持不变,而作者的DPE则随着面积比呈线性增加,但仍然保持显著的效率优势。值得注意的是,对于主要的小目标,DPE的延迟要求不到非DPE的25%。
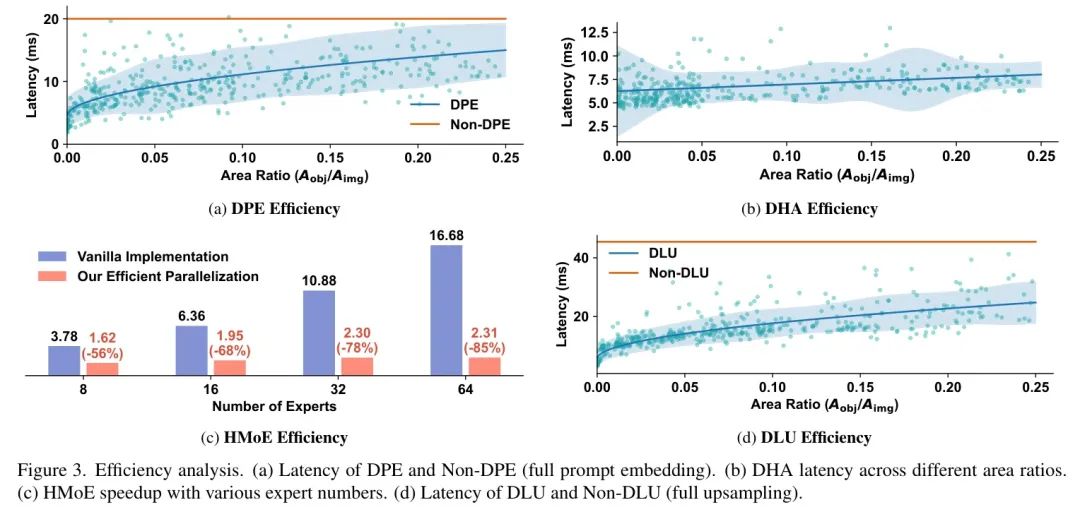
DHA效率。如图3(b)所示,随着区域比例的增长,DHA的延迟呈现缓慢的线性上升。这种稳定趋势源于DHA对边缘的关注。虽然目标区域呈平方级增长,但边缘像素的数量增长较慢,从而即使在处理大型目标时也能实现高效处理。
HMoE效率。如图3(c)所示,作者比较了高效的并行HMoE与普通实现在不同专家数量下的表现。HMoE随着专家数量的增加表现出明显的加速效果,在64个专家时实现了85%的延迟减少。
DLU效率。如图3(d)所示,DLU作为DPE的倒数,表现出相似的速度模式。作者的DLU在相同结构下运行速度远快于Non-DLU。
每个模块性能的详细消融研究已提供在补充材料中。
4.5. 定性结果
如图4所示,Inter2Former在20次点击内实现了对挑战性细小结构的精确分割。
5. 结论
本文介绍了Inter2Former,一种用于高精度交互式分割的模型,旨在解决密集 Prompt Token 处理中性能与效率之间的关键权衡问题。通过提出的动态 Prompt 嵌入、动态混合注意力、混合专家混合和动态局部上采样等自适应计算分配机制,Inter2Former在保持效率的同时优化了性能,在CPU设备上实现了具有竞争力的速度和SOTA性能。
参考
[1]. Inter2Former: Dynamic Hybrid Attention for Efficient High-Precision Interactive Segmentation
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









