 HybridNorm革新Transformer训练,兼顾稳定与性能
HybridNorm革新Transformer训练,兼顾稳定与性能







本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:HybridNorm 革新 Transformer 训练 | QKV与 FFN 双路径混合归一化,稳定训练+性能突破双赢

导读
Transformer 已成为众多机器学习任务的默认架构,尤其是在大语言模型(LLMs)中。尽管它们的表现令人瞩目,但在训练深度 Transformer 网络方面仍存在挑战,尤其是在层归一化的位置上。虽然Pre-Norm结构由于其更明显的恒等路径而便于训练,但与Post-Norm相比,它们通常会产生次优的性能。
在本文中,作者提出了HybridNorm,这是一种简单而有效的混合归一化策略,它结合了Pre-Norm和Post-Norm方法的优势。具体来说,HybridNorm在注意力机制中采用QKV归一化,在每个 Transformer 块的FFN中采用Post-Norm。这种设计不仅稳定了训练,还提高了性能,特别是在LLMs的背景下。
在密集和Sparse架构中的全面实验表明,HybridNorm在各个基准测试中始终优于Pre-Norm和Post-Norm方法,实现了最先进的结果。这些发现突出了HybridNorm作为提高深度 Transformer 模型训练和性能的更稳定和有效技术的潜力。
代码:https://github.com/BryceZhuo/HybridNorm
1. 引言
Transformer已成为大语言模型(LLM)和众多机器学习应用的 Backbone 。这些架构通过自注意力机制能够建模长距离依赖关系,这使得它们成为包括语言建模、机器翻译和图像处理在内的各种任务的优选选择。然而,随着Transformer模型变得越来越深和复杂,确保稳定的训练仍然是一个重大挑战。影响训练稳定性的一个关键因素是归一化方法的选择,这对于缓解内部协变量偏移和梯度不稳定等问题至关重要。有效解决这些挑战对于充分发挥深度Transformer模型在大规模应用中的潜力至关重要。
在Transformer中LayerNorm在稳定训练过程中发挥着核心作用,通过归一化每层的激活来提高稳定性。应用LayerNorm的两种主要策略是预层归一化(Pre-Norm)和后层归一化(Post-Norm),每种策略都有其各自的优缺点。在Pre-Norm架构中,归一化在残差添加之前进行,从而产生一个更显著的恒等路径,这有助于加快收敛速度和更稳定的梯度。这种设计在训练深度模型时特别有利,因为它有助于缓解反向传播过程中出现的梯度相关问题。然而,尽管Pre-Norm可以稳定训练,但它通常比Post-Norm的最终性能较差。相比之下,PostNorm在残差连接之后进行归一化,从而产生更强的正则化效果,这有助于提高模型性能。这种方法已被证明可以改善Transformer的泛化能力,尤其是在非常深的网络中。
尽管每种方法都有其优势,但训练稳定性与最终模型性能之间存在固有的权衡。Pre-Norm结构通常能稳定训练过程,但在泛化能力方面可能表现不佳,而PostNorm架构则能提供更好的性能,但训练起来可能更困难,尤其是在深度模型中。为了调和这些权衡,作者提出了一种混合归一化方法,该方法在注意力机制中应用QKV归一化,在 FFN (FFN)中应用Post-Norm,命名为HybridNorm。注意力机制中的QKV归一化通过归一化 Query 、 Key和Value 组件,稳定了层之间的信息 Stream ,而FFN中的Post-Norm确保了在transformer的深层中有效扩展深度。
通过在大型模型上的大量实验,作者验证了HybridNorm的有效性。作者的结果表明,混合归一化方法在多个基准测试中显著优于Pre-Norm和Post-Norm,提供了稳定的训练过程和改进的模型性能。具体来说,HybridNorm在LLMs的背景下取得了优异的结果,其中两种归一化方案的益处最为明显。作者相信,这种混合方法为增强深度Transformer架构的训练稳定性和性能提供了一个有希望的解决方案,尤其是在快速发展的LLMs领域。
本文的主要贡献可以概括如下。
-
• 作者提出了HybridNorm,一种新型的混合归一化结构,它结合了Pre-Norm和Post-Norm的优点,为提升大型Transformer模型性能提供了一种简单而有效的解决方案。HybridNorm旨在利用两种归一化方法的优点,确保训练过程中的稳健收敛和优异的最终性能。
-
• 作者对所提出的混合归一化方法进行了实证分析,展示了其在梯度流稳定性、正则化效果和模型鲁棒性方面的潜在优势。该分析突出了HybridNorm如何解决深度 Transformer 架构所提出的核心挑战。
-
• 通过对大规模模型进行广泛的实验,作者实证验证了HybridNorm的有效性。作者的结果表明,混合归一化在多种任务中显著优于预归一化和后归一化,导致训练更加稳定,并提升了模型性能,尤其是在大语言模型(LLMs)的背景下。
2. 相关工作
Transformer架构修改。近期在Transformer架构修改方面的努力旨在优化模型的计算效率和表达能力。这些努力包括对注意力机制和 FFN 的修改,所有这些修改都是为了在各种任务上提高性能,从语言建模到视觉任务。例如,多头潜在注意力(MLA)、专家混合(MoE)。虽然这些修改有助于更高效的训练,但它们也需要与其他组件,如归一化层,进行谨慎的集成,以保持模型稳定性和性能。
Transformer中的归一化类型。归一化层对于深度学习模型的成功至关重要,Transformer也不例外。在Transformer中最常用的归一化技术是层归一化,它独立地对每一层的激活进行归一化。然而,在特定环境下,已经提出了如RMSNorm等替代方法,该方法使用均方根统计进行归一化,作为更有效的替代方案。这些方法旨在缓解内部协变量偏移和梯度不稳定性等挑战,这对于大规模Transformer模型的成功至关重要。
performance. 在注意力机制中的归一化设置。为了训练的稳定性,QK-Norm过在注意力计算过程中直接对 Query 和Key组件进行归一化来修改标准的注意力机制。在此基础上,QKVNorm通过归一化 Query、Key和Value组件来扩展该方法。这种全面的归一化确保了注意力机制的所有关键组件都得到归一化,从而提高了稳定性和性能。
归一化层的位置。另一条研究线关注归一化的位置。在Transformer文献中,Pre-Norm和Post-Norm架构之间的选择已经被广泛研究。Pre-Norm,即在残差连接之前应用归一化,已被证明在深度网络中更稳定,并加速收敛。尽管Post-Norm的训练更具挑战性,但它通过在残差连接之后进行归一化,往往能提供更好的最终性能。DeepNorm被提出作为一种解决深度Transformer训练不稳定性的策略,它通过一个精心选择的因子缩放残差连接,以改善梯度流并减轻梯度爆炸或消失。与HybridNorm最相似的是Mix-LN,它将Post-Norm应用于早期层,将Pre-Norm应用于深层层,实现了改进的训练稳定性和更好的性能。相比之下,作者的HybridNorm在每个Transformer块内整合了Pre-Norm和Post-Norm。
3. 方法
在本节中,作者首先回顾了在Transformer架构中占主导地位的两种归一化策略:后归一化和前归一化。随后,作者介绍了作者提出的混合归一化方法,即HybridNorm,并给出了其形式定义。
3.1. 前言

3.2 后规范与预规范
Transformer架构由L个块堆叠而成,每个块包含两个关键组件:多头注意力(MHA)和前馈神经网络(FFN)。在每个块中,对MHA和FFN都应用了残差连接和归一化层,以促进有效训练并提高模型稳定性。图2(a)和(b)分别展示了后归一化和前归一化。
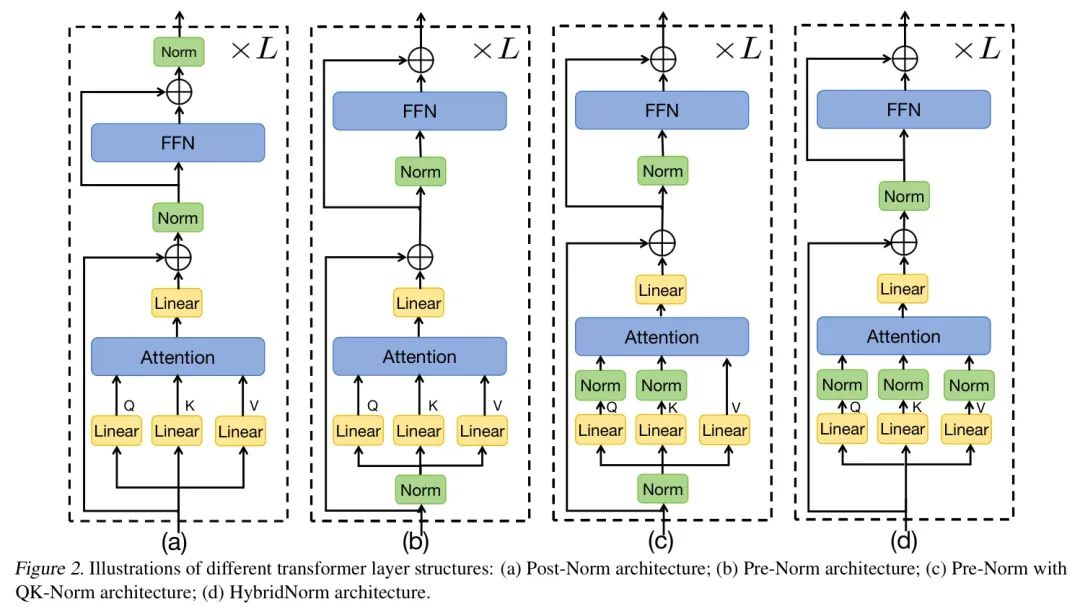

该结构有利于更好的梯度 Stream 和稳定收敛,尤其是对于深度模型。然而,其对残差连接前归一化的依赖可能导致与后归一化相比性能不佳,因为归一化没有考虑到残差连接与子层输出的相互作用。
3.3 混合归一化
为解决Post-Norm和Pre-Norm之间的权衡问题,作者提出了HybridNorm,这是一种混合归一化策略,它整合了它们的优点。具体来说,HybridNorm将MHA中的QKV-Norm(Menary等,2024;Rybakov等,2024)与FFN中的Post-Norm相结合。
QKV 正规化在注意力机制中的应用。在注意力机制中, Query (query)、键(key)和值(value)矩阵在计算注意力输出之前分别进行归一化。然后,归一化的QKV矩阵被用于缩放点积注意力。QKV-Norm增强了模型训练的稳定性,并导致下游性能的提升。形式上,带有QKV-Norm的注意力定义为:

架构图可在图2(d)中找到,伪代码在算法1中展示。通过在注意力机制中集成QKV归一化和在FFN中集成PostNorm,HybridNorm实现了稳定的训练动态和增强的最终性能。理论梯度分析可在附录A中找到。
备注3.1:与HybridNorm最密切相关的是Mix-LN,该方法将Post-Norm应用于早期层,将Pre-Norm应用于深层层,从而提高了训练的稳定性和性能。相比之下,作者提出的HybridNorm在每个Transformer块内整合了Pre-Norm和Post-Norm,提供了一种统一的方法来利用两种归一化策略的优势。此外,实验表明,与Mix-LN相比,HybridNorm实现了更优越的下游性能(见表4)。
第一块的特殊处理。受先前工作(DeepSeek-AI,2024)的启发,该工作采用混合专家(MoE)架构并对第一层进行专门处理,作者探讨了引入专门归一化到第一 Transformer 块的影响。在HybridNorm中,通过应用预归一化到MHA和FFN,而保持QKV归一化,对 Transformer 的第一层进行特殊处理。具体来说,作者第一层的结构定义为:
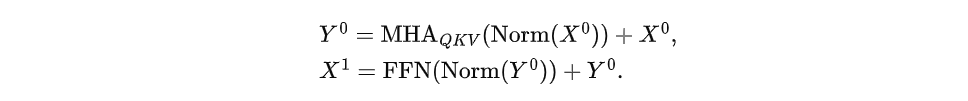
作者将这种包含专用首块处理的HybridNorm变体称为HybridNorm*。该设计旨在通过改善训练早期阶段的梯度 Stream ,稳定首个Transformer块的训练并提升整体性能。
4. 实验
在本节中,作者通过在大语言模型(LLMs)中进行广泛的实验,展示了Hybrid-Norm的有效性。
4.1 实验设置
Baseline 。作者评估了HybridNorm在两组模型上的表现:密集模型和混合专家(MoE)模型。密集模型包括两个规模:550M和1B,后者包含大约12.7亿个参数,采用与Llama 3.2(Dubey等,2024)相似的架构。所有分析实验都是在550M密集模型上进行的。对于MoE模型,作者使用了OLMoE框架(Muennighoff等,2025),该框架在总共69亿个参数中激活了13亿个参数(MoE-1B-7B)。这两个模型都是在OLMoE Mix数据集1(Muennighoff等,2025)上从头开始训练的。
模型配置。550M密集模型具有1536的模型维度,FFN维度为4096,每个注意力头使用16个注意力头,每个注意力头有4个键/值头。1.2B模型具有更大的模型维度2048和FFN维度9192,32个注意力头,每个注意力头有8个键/值头。MoE-1B-7B模型采用16个注意力头,模型维度为2048,FFN维度为1024。值得注意的是,它从64个专家中选出8个,提供了更精细的计算资源分配。所有模型均由16层组成,并使用4096个一致上下文长度进行训练。更多详细信息请见附录B。

评估指标。为了评估HybridNorm在LLM中的性能,作者采用了一系列公开的基准测试,包括ARC-Easy(ARC-E),ARC-Challenge(ARC-C),HellaSwag,PIQA,SciQ,CoQA,Winogrande,MMLU,BoolQ,COPA,CSQA,OBQA和SocialIQA。作者利用LM Eval Harness进行标准化的性能评估。
4.2 密集模型的主要结果
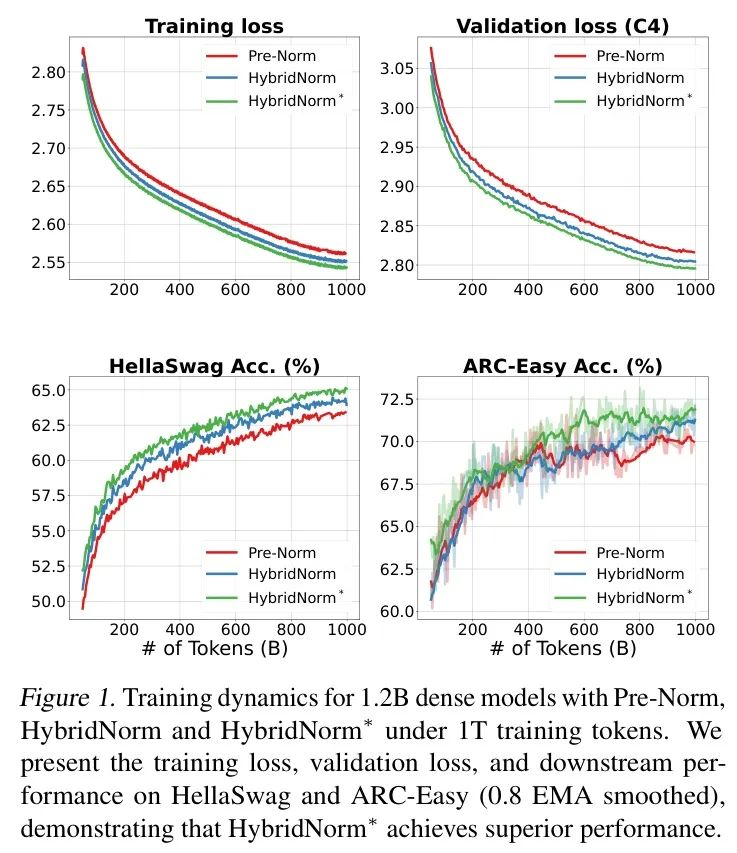
作者评估了HybridNorm和HybridNorm*在1.2B密集型Transformer模型上的性能。图1比较了不同归一化方法下密集型模型的训练动态。如图所示,与Pre-Norm相比,采用HybridNorm和HybridNorm*的模型在整个训练过程中表现出持续更低的训练损失和验证困惑度,突显了它们在增强训练稳定性和收敛性方面的有效性。
4.3 MoE模型的主要结果
对于MoE模型,作者在从64个专家中选出的8个专家组成的池中对MoE-1B7B进行了实验。图3展示了不同归一化策略下MoE模型的训练动态。在整个训练过程中,HybridNorm*与Pre-Norm相比,始终实现了更低的训练损失和验证困惑度。这些发现表明,HybridNorm*有效地缓解了大规模MoE模型中的优化困难,从而实现了更稳定的训练和增强的下游性能。
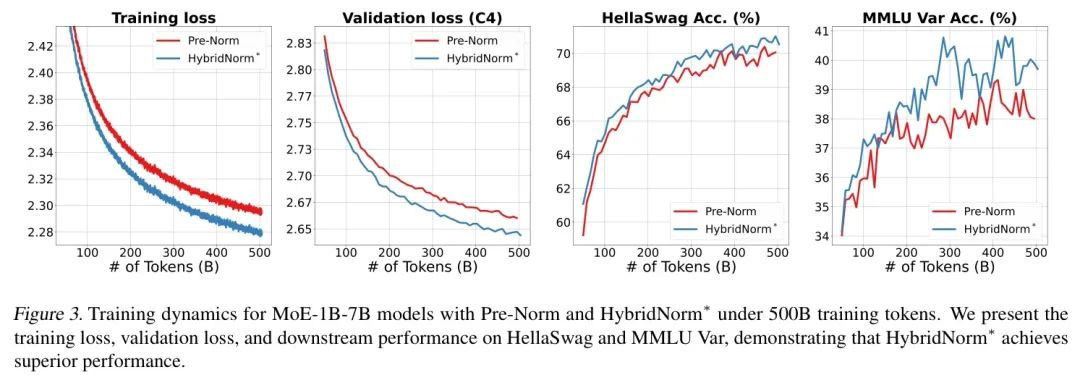
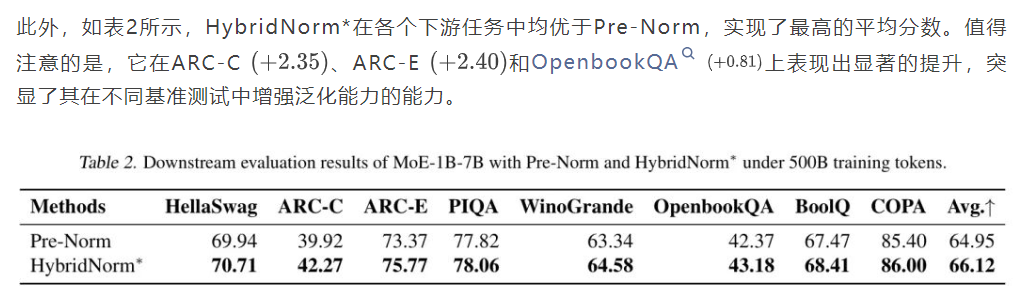
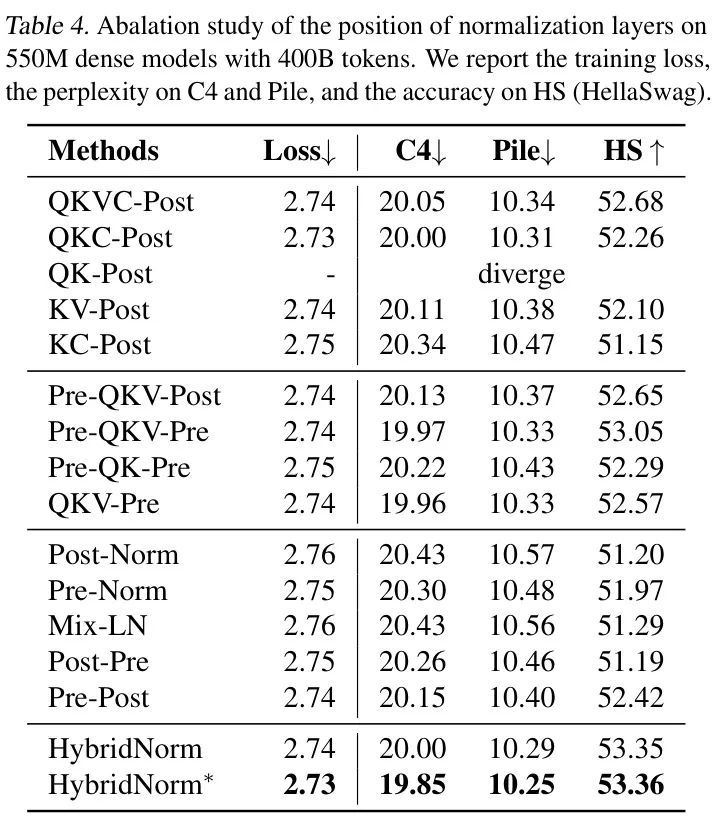
4.4. 消融研究

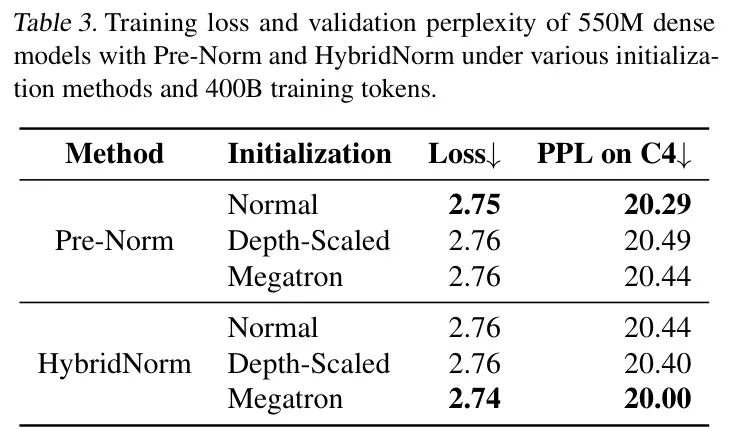
如表3所示,Pre-Norm和HybridNorm在不同初始化方法下均表现出敏感性,分别在正常初始化和Megatron初始化下实现了最低的训练损失和困惑度。因此,作者在所有实验中将Pre-Norm的默认初始化方法设置为正常初始化,将HybridNorm的默认初始化方法设置为Megatron初始化,以确保即使在可能更有利于 Baseline 模型的设置下,HybridNorm的优势也能得到有效体现。
规范化位置。作者研究了规范化层在Transformer块中的位置对模型的影响。首先,作者考察了改变QKV规范化(例如,注意力中的规范化设置)位置的效果。作者扩展了规范化设置,不仅考虑了Query(Q)、Key(K)和Value(V)组件,还包括了Context(C),它指的是注意力机制的输出。例如,QKVC-Norm对Query、Key、Value和Context这四个组件进行规范化,而KV-Norm和KC-Norm分别专注于Key-Value和Key-Context对的规范化。QKVC-Post指的是在MHA中使用QKVC-Norm,同时在FFN中使用Post-Norm的Transformer块。其次,作者探讨了将QKV-Norm整合到不同的Transformer架构中的效果。例如,Pre-QKV-Pre指的是在MHA层中使用Pre-Norm进行QKVNorm,而FFN层使用Post-Norm的配置。其他配置遵循类似定义。最后,作者比较了各种Pre-Norm和Post-Norm的混合组合。Pre-Post指的是在MHA中使用Pre-Norm,在FFN中使用Post-Norm的Transformer块,而Post-Pre采用相反的配置。上述方法的数学公式可以在附录E中找到。
如表4所示,HybridNorm(也称为QKV-Post)及其变体HybridNorm在所有配置中均表现优异。值得注意的是,HybridNorm在HellaSwag上实现了最低的训练损失和困惑度,同时达到了最高的准确率。具体而言,通过将HybridNorm与表4中的第一个块进行比较,作者发现QKV-Norm是注意力中最有效的归一化设置。同样,将HybridNorm与第二个块进行比较,作者观察到在FFN中将QKV-Norm与Post-Norm结合使用可以获得更好的性能。从第三个块中可以看出,Pre-Post配置确实导致了性能的提升,而将MHA中的Pre-Norm替换为QKV-Norm以形成HybridNorm进一步增强了性能,实现了最佳结果。
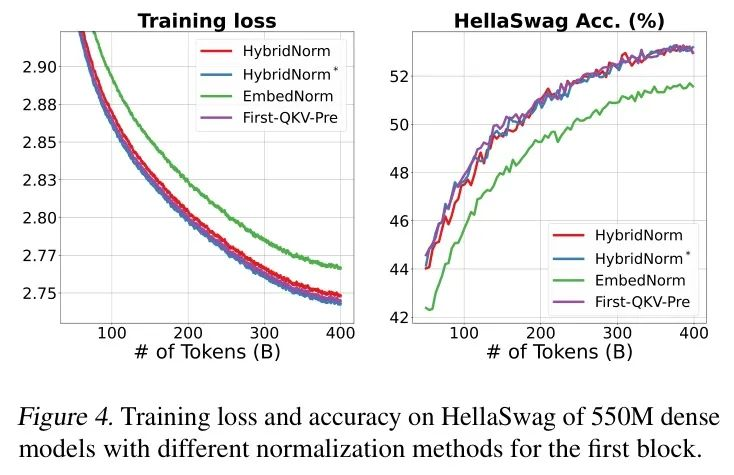
对第一块的特别处理。对于第一块的特别处理,作者测试了不同的架构,例如在嵌入层后添加归一化层(称为EmbedNorm),并在FNN中为第一块配备了QKV-norm和Pre-Norm(称为First-QKV-Pre),其公式如下:
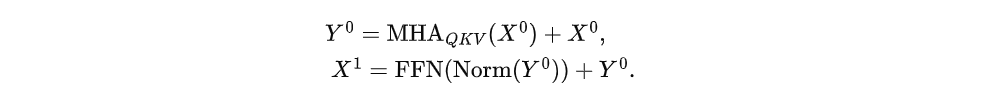
如图4所示,作者可以看到,除了Embed-Norm外,对第一个块的特别处理有效地降低了训练损失并提升了下游性能。
4.5 梯度分析
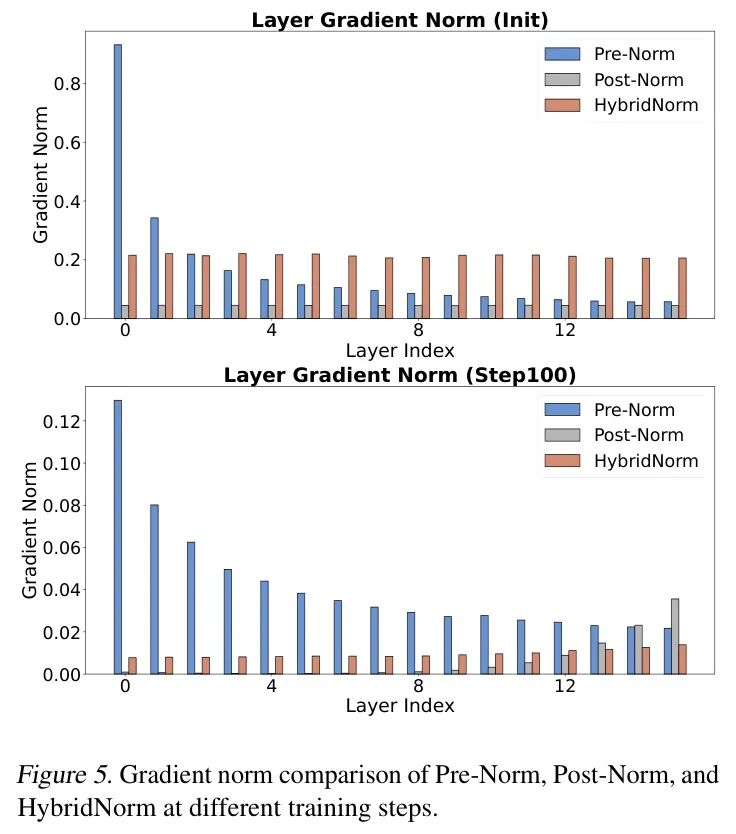
为了更深入地了解HybridNorm引入的稳定性改进,作者分析了训练迭代过程中的梯度范数。如图5所示,作者比较了Pre-Norm、Post-Norm和HybridNorm在步骤1和100时的梯度范数。结果表明,Pre-Norm在深层模型中倾向于出现梯度爆炸,而PostNorm则遭受梯度消失的问题,这两者都阻碍了有效的优化。相比之下,HybridNorm在整个训练过程中保持梯度流的良好平衡,有效地缓解了这些问题。直观理解是,Pre-Norm倾向于放大梯度,而Post-Norm则减弱它们。HybridNorm在这两种归一化策略之间交替,导致在反向传播过程中梯度传播更加稳定,有效地防止了梯度爆炸或消失。这种平衡的梯度传播有助于优化动态更加平滑,收敛速度更快,进一步强化了HybridNorm在稳定transformer训练中的有效性。
4.6. 规模化定律实验
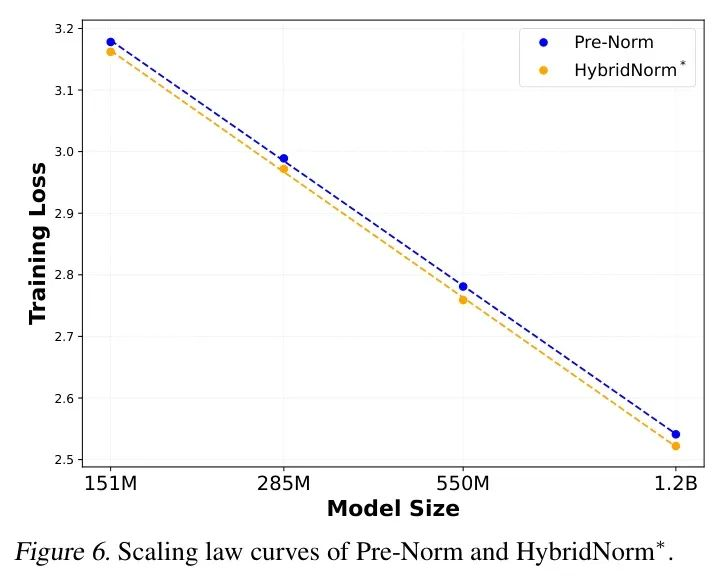
作者比较了Pre-Norm和HybridNorm*在多种密集模型大小范围内的损失缩放曲线,模型大小从1.51亿到12亿参数不等。用于缩放定律实验的模型大小在表6中详细说明,所有模型均使用相同的设置和超参数进行训练,以确保公平比较,具体见表7。具有1.51亿、2.85亿、5.5亿和12亿参数的模型分别训练在2000亿、2000亿、3000亿和1万亿个token上。如图6所示,HybridNorm*表现出更优越的缩放特性,随着模型大小的增加,训练损失更低。这突显了它维持训练稳定性和性能的能力,即使是对于极其大的模型,因此使其非常适合扩展到百亿参数 Level 。
4.7 深度模型
为了进一步评估HybridNorm和HybridNorm在更深层次架构中的鲁棒性,作者在参数预算可比的情况下,对深度从16层到29层的transformer进行了实验。这种设置允许对深层transformer架构中不同的归一化策略进行公平的比较。如表5所示,HybridNorm和HybridNorm在各个深度上均持续优于Pre-Norm和Post-Norm,证明了它们在稳定深层模型训练中的有效性。
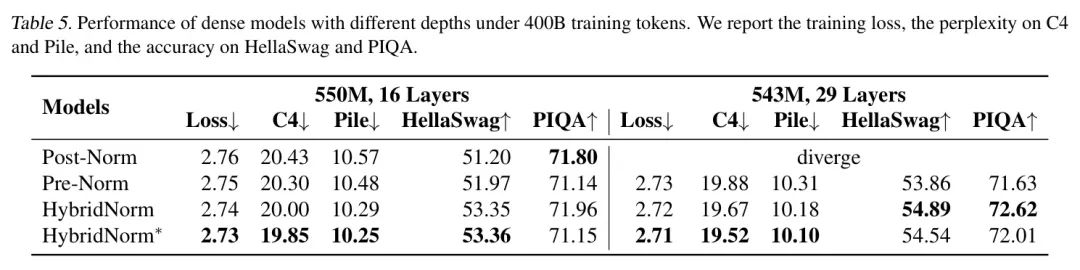
一个特别引人注目的观察结果是,Post-Norm在29层时未能收敛,这进一步证实了它在深层架构中的不稳定性问题。相比之下,HybridNorm和HybridNorm*不仅确保了所有深度的稳定训练,而且在C4和Pile数据集上实现了显著降低的训练损失和困惑度。这些改进表明,基于HybridNorm的归一化策略可以缓解深层transformer中常见的优化困难。此外,HybridNorm*在具有挑战性的下游基准测试(如HellaSwag和PIQA)上取得了最高的准确率,这表明其益处不仅限于训练稳定性,还扩展到了增强现实世界任务上的泛化能力。这些结果提供了强有力的经验证据,表明基于HybridNorm的归一化方案能够在保持卓越的优化效率和下游任务性能的同时,实现更深层的transformer训练。
5. 结论
本文提出了一种名为HybridNorm的新型混合归一化方法,该方法有效整合了Pre-Norm和Post-Norm的优势,以解决Transformer训练中长期存在的权衡问题。作者提供了实证见解,说明了HybridNorm如何稳定梯度流同时保持强大的正则化效果,展示了其提高收敛性和最终模型性能的潜力。在多个基准上的广泛实验验证了HybridNorm的有效性,结果显示HybridNorm在稳定性和准确性方面均优于传统的归一化策略。
作者的发现强调了重新评估归一化在Transformer架构中位置的重要性,从而为混合策略的进一步探索奠定了基础。作者认为,HybridNorm在更稳健和高效的深度Transformer模型设计方面取得了重大进步,为下一代大规模神经网络的训练提供了实际优势。
参考
[1]. HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









