




本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发及AI大模型算法学习视频及资料,尽在 聚客AI学院。
在人工智能领域,Transformer架构无疑是大模型发展史上最重要的里程碑之一。它不仅构成了当前大模型处理任务的基础架构,更是深入理解现代大模型系统的关键。今天我将通过结合论文原理与PyTorch源码API,深度解析Transformer的设计思路与实现细节。如有遗漏,欢迎交流。
一、整体架构设计
Transformer模型分为两个主要部分:左侧的编码器(Encoder)和右侧的解码器(Decoder)。
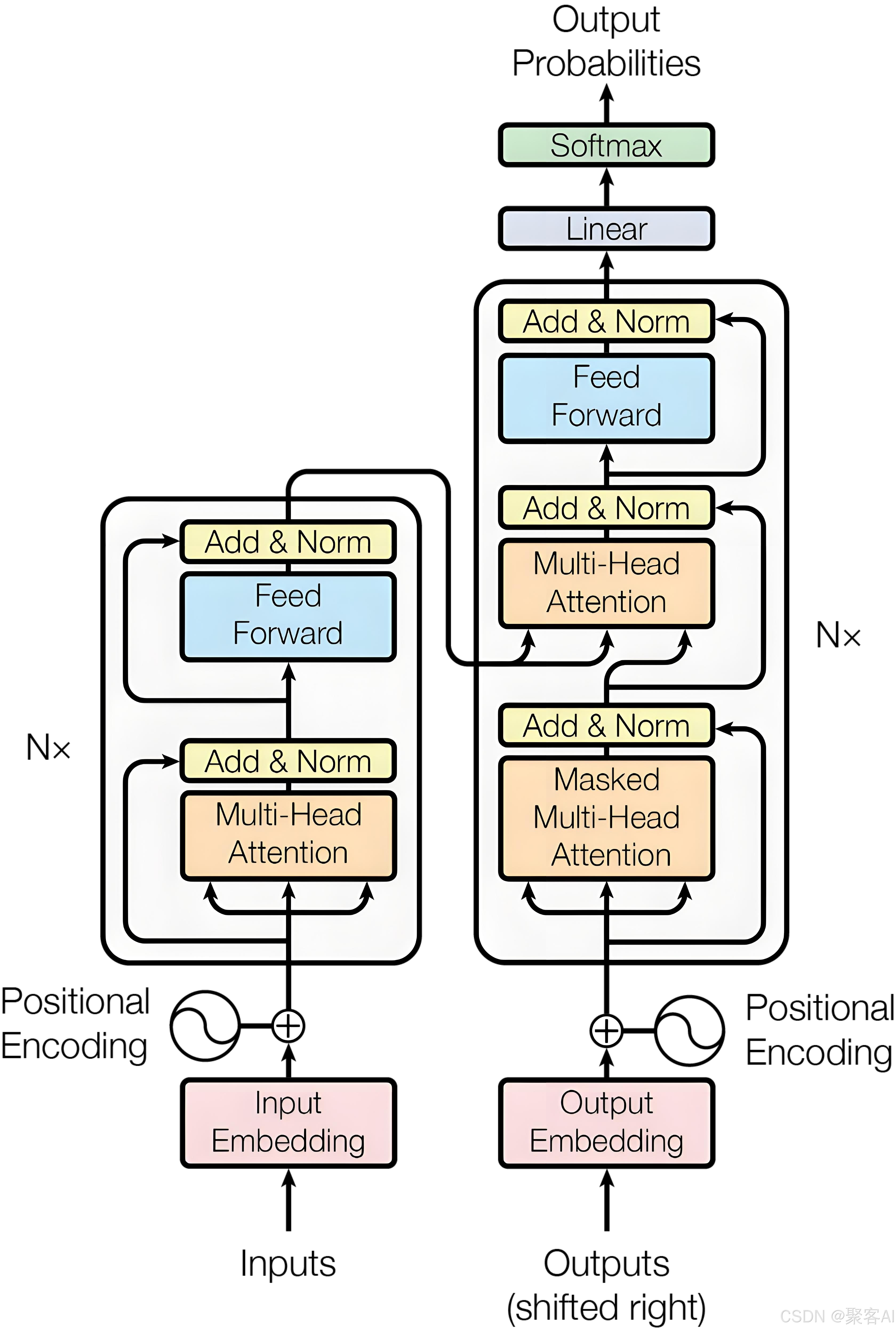
编码器负责接受完整的源序列输入,将其转换为富含语义信息的表示序列。以机器翻译任务为例,编码器的作用类似于深度理解原文的专家,需要充分把握整个句子的含义、语法结构和上下文关系。
解码器承担着更为复杂的任务:它需要同时接受目标序列和编码器输出的表示序列,然后输出词汇/字符的概率分布。这好比翻译专家既要理解原文含义(通过编码器输出),又要根据已翻译内容决定下一个合适的词汇。
二、位置编码机制
Transformer模型本身对位置信息不敏感。例如"我爱你"和"你爱我"这两个句子,在没有位置信息的情况下,模型无法识别它们是语义完全不同的表达。这就像人类失去对词语顺序的感知能力,显然无法正确理解语言。
因此,需要引入带有位置信息的向量,将其添加到每个input embedding上,使不同位置获得不同的表征。这就是Positional Encoding模块的作用。
在设计位置编码时,遵循三个重要假设:
- 确定性原则:每个位置的编码应该是确定的数字,不同序列中相同位置的编码必须一致。如果采用等分设计方法,将序列在0~1之间做均匀划分,那么序列长度不同时每个位置上的编码也会不同,这将违反确定性原则。
- 相对关系一致性:不同句子中,任意两个位置之间的相对距离关系应该保持一致。这一设计目的是让模型学习通用的语言关系,例如"修饰词位于被修饰词前一个位置"这种通用模式。
- 泛化能力:位置编码需要能够推广到训练时未见过的更长序列。即使测试集中的句子长度超过训练时的最大长度,模型仍能通过位置编码进行处理。
基于这些假设,Transformer采用正弦和余弦函数的组合来表征绝对位置信息:
- 向量维度为偶数:PE(pos, 2i) = sin(pos/10000^(2i/d_model))
- 向量维度为奇数:PE(pos, 2i+1) = cos(pos/10000^(2i/d_model))
这种设计的关键优势在于:pe(pos+k)可以表示为pe(k)的线性组合(利用三角函数公式sin(A+B)=sin(A)cos(B)+cos(A)sin(B))。这意味着即使测试集中出现pos+k这种未见过的位置,也可以表示为训练集中已见过位置的线性组合,从而保证了对长句子的推广能力。
关于位置信息在深层网络中可能丢失的担忧,通过残差连接机制得到解决。假设有N层神经网络,输入x₀包含位置编码,那么:
第1层: x₁ = x₀ + F₁(x₀)
第2层: x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5586
5586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











