






 本篇博客总结了吴恩达深度学习课程中关于序列模型的第二周内容,重点介绍了词向量(Word Embeddings)的概念和重要性。文章探讨了词向量如何解决one-hot编码的问题,以及Word2Vec的Skip-Gram模型和Negative Sampling方法。此外,还讨论了GloVe向量、词向量的特性、应用及其在情感分析和消除偏见方面的实践。
本篇博客总结了吴恩达深度学习课程中关于序列模型的第二周内容,重点介绍了词向量(Word Embeddings)的概念和重要性。文章探讨了词向量如何解决one-hot编码的问题,以及Word2Vec的Skip-Gram模型和Negative Sampling方法。此外,还讨论了GloVe向量、词向量的特性、应用及其在情感分析和消除偏见方面的实践。
第二周主要讲Word Vectors(Word Embeddings),具体的可以看:
cs224n Lecture 2 :Word2Vec Skip-Gram CBOW Negative Sampling 总结
cs224n Lecture 3: GloVe skipgram cbow lsa 等方法对比 / 词向量评估 /超参数调节 总结
GloVe :Global Vectors 全局向量 模型详解 公式推导
Introduction to Word Embeddings
Word Representation
用one-hot来表示单词,有个问题,就是无法获取单词之间的联系。比如学习算法已经学习到I want a glass of orange juice,但是如果碰到I want a glass of apple ___,就会不知所措。因为one-hot词向量,任意两个词都正交。
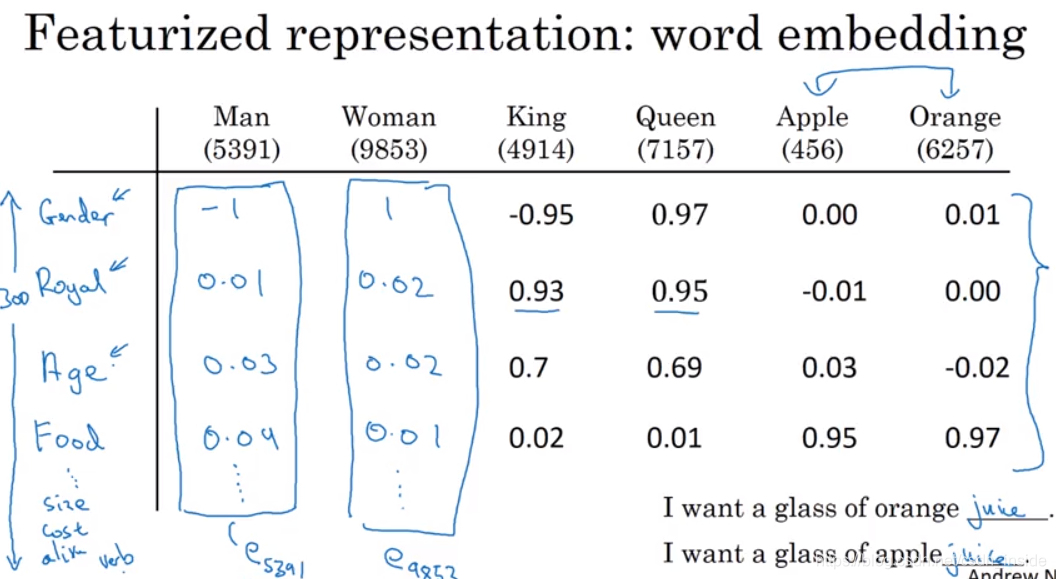
为了解决这个问题,就有了Word Embedding。每个词向量不再是非0即1,而是有具体的数值,在后面可以通过学习算法来获得这些词向量。词向量的每一个分量,表示某种特定含义 ,比如这里的第一行表示性别,第二行表示忠诚。但要注意,在实际的词向量中,每一行的意义并没有这么明显和绝对。
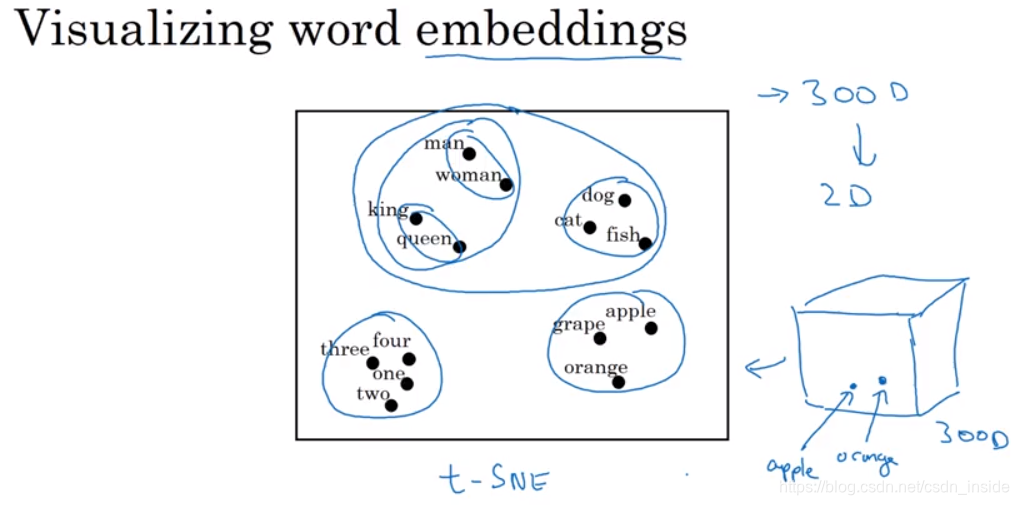
如果用t-SNE降到2维进行可视化,可以发现相似的词,聚在了一起。
Using Word Embeddings
使用Word Embedding的一个好处就是可以轻松、准确地进行一些NLP任务。
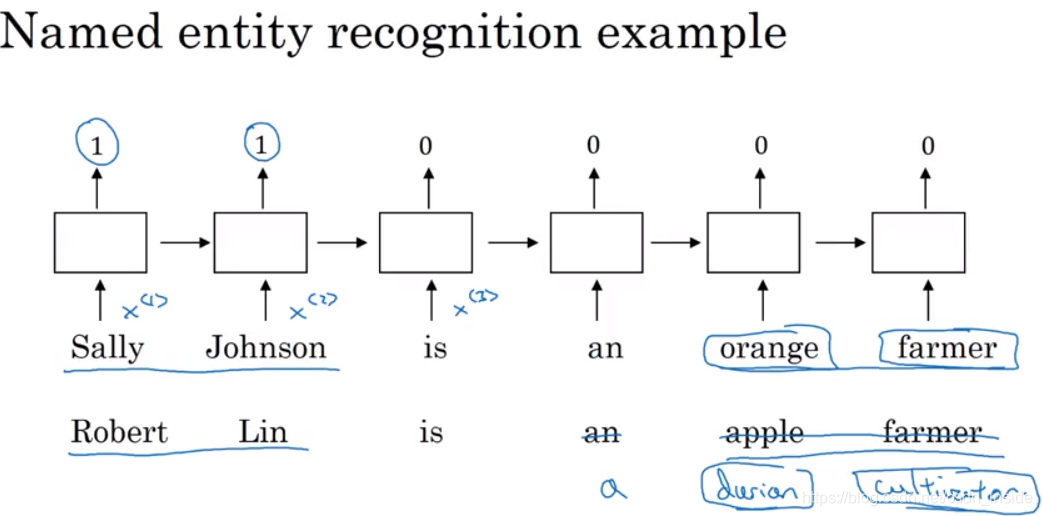
比如在下面的命名实体识别里面,在训练的时候,知道Sally、Johnson是人名,orange是水果,farmer是职业。
当有一个新句子需要识别时,通过词嵌入,就可以做类比,Robert---Sally,Lin---Johnson,durian---orange,cultivator---farmer,所以Robert、Lin是人名,durian是水果,cultivator也是职业。
相比自己来学习词向量,一种可行的方法是利用迁移学习,用别人训练好的词向量(比如GloVe),做适当调整,放到自己的模型里,可节省大量时间、精力。

Properties of word Embeddings
词嵌入的一个特性,就是可以获得词之间的类似(analogy reasoning),比如man is to woman as king is to queen。
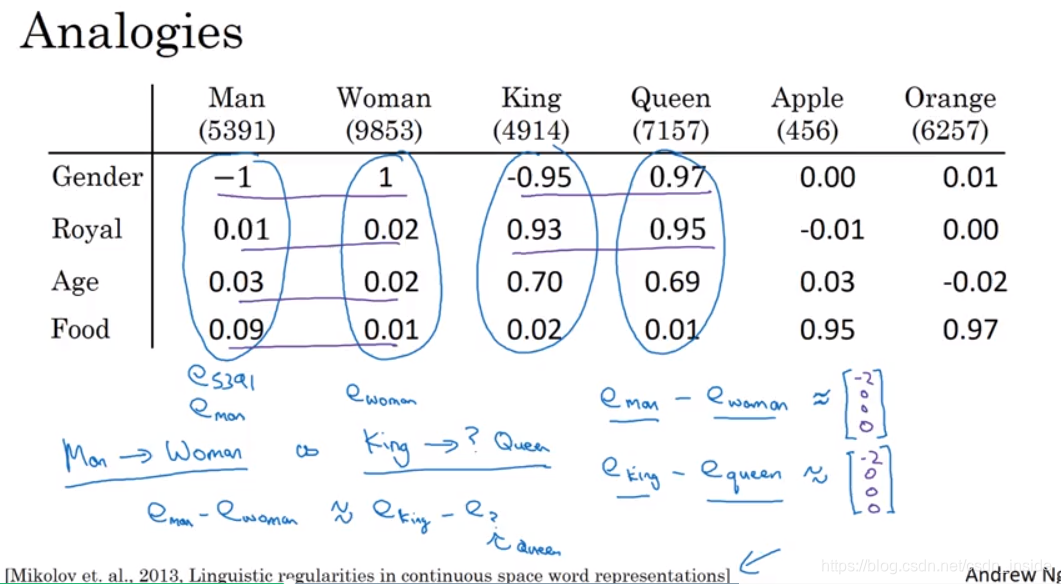
一般用一个Similarity相似函数来评估这种相似。

常见的有Cosine距离,还有欧几里得距离,来作为相似函数。

Embedding matrix
通常有一个n_features * m_words的Embedding Matrix,这也是在后面需要学习的矩阵。
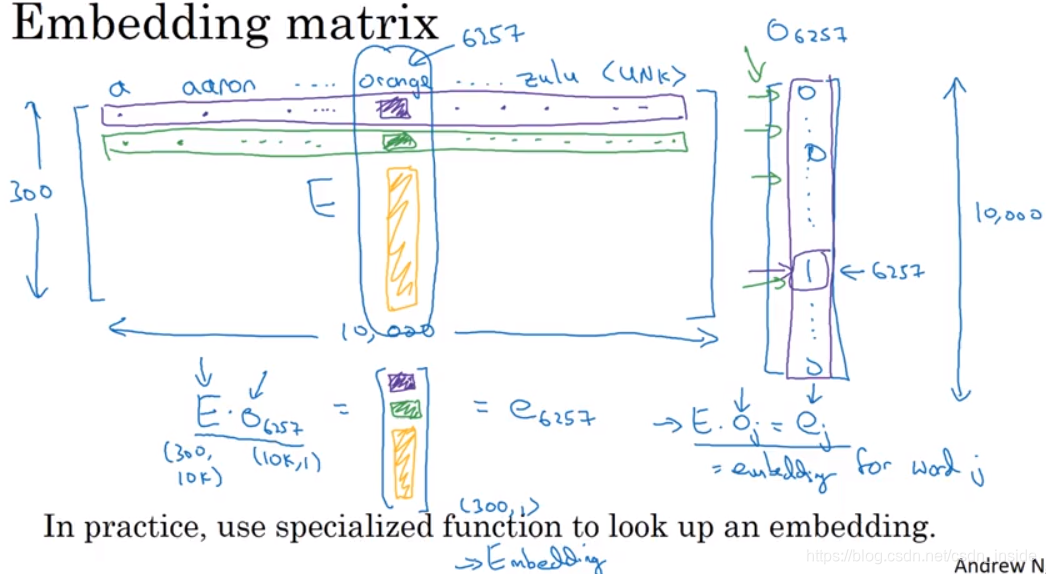
一般,还需要用一个One-hot向量,来筛选具体某个单词的词向量。
Learning Word Embeddings:Word2vec & GloVe
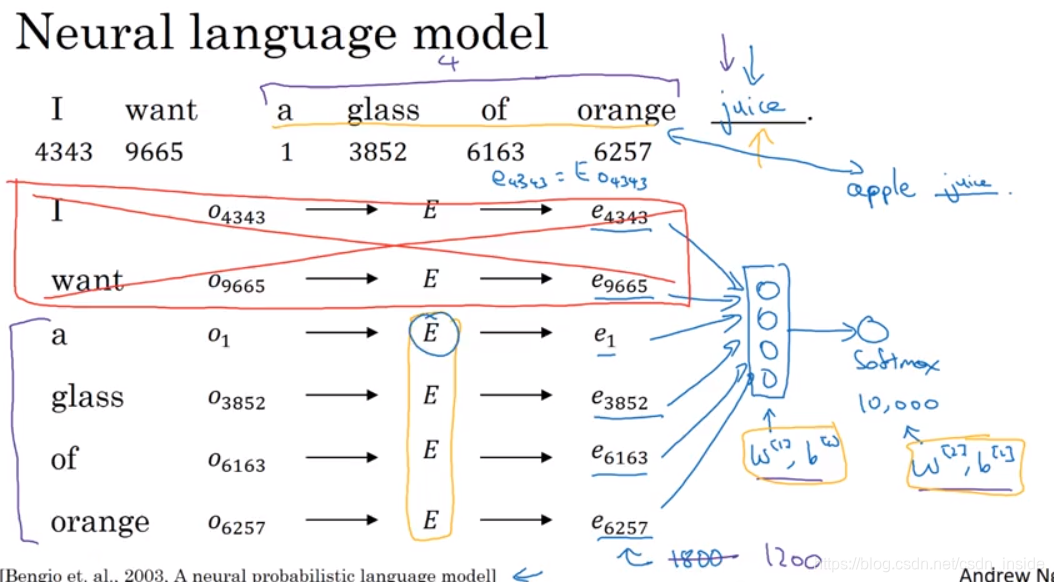
Learning word embeddings
有两种学习词向量的方法:
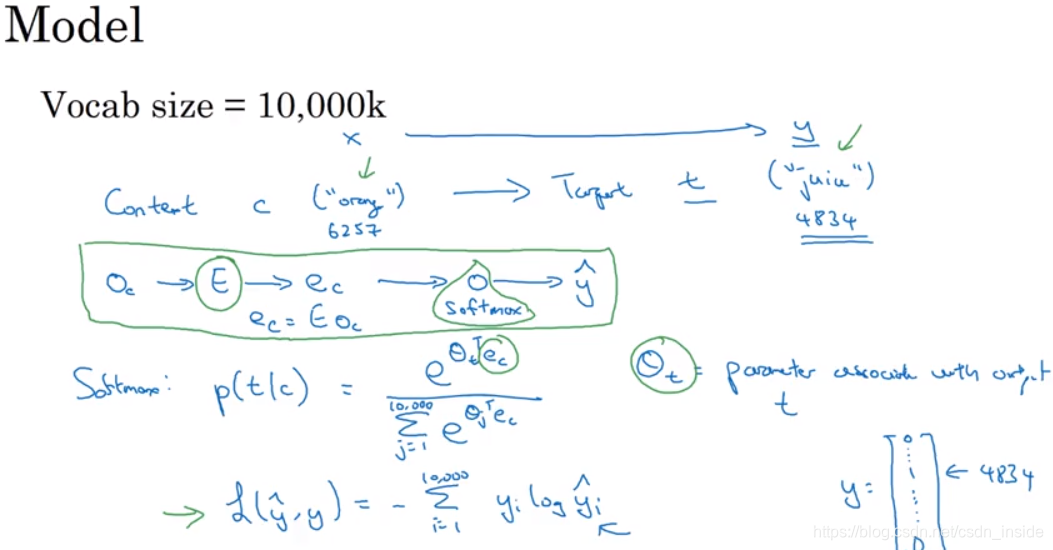
一种将句子里所有前N-1单词的词向量组合成一个矩阵,送入softmax,输出词汇表数量个概率,选择最高的那个,与ground truth(文本第N个单词)进行比较。
另一种是Skip-Gram方法。其背景词不再是整个句子,而是可以指定。

Word2Vec(Skip-Gram)
详见:cs224n Lecture 2 :Word2Vec Skip-Gram CBOW Negative Sampling 总结

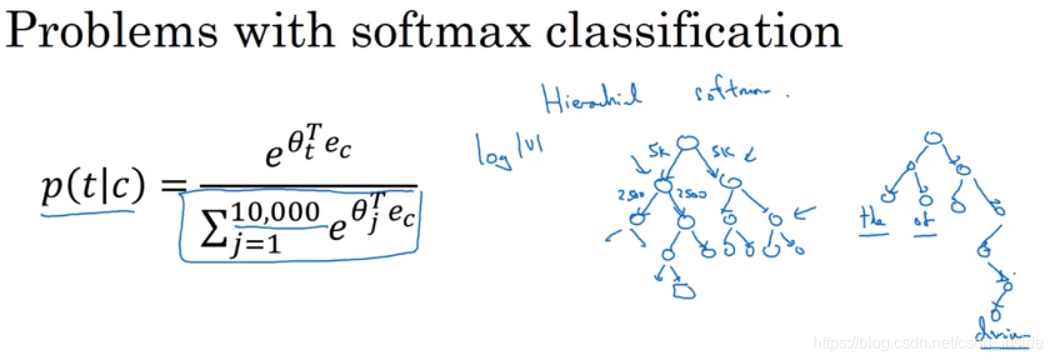
SG模型最后的softmax要遍历整个词汇表,计算量很大,有了改进的分级softmax,像二叉树一样。
由于本文中有大量a、of、the这些词,所以背景词的选定不应该是随机均匀分布的,要做改变。

Negative Sampling
由于词汇表很大,所以大部分词对都是负例,是稀疏的,与其计算所有负例,不如选择K个负例出来,同样具有代表性,这就是负采样方法的思想。
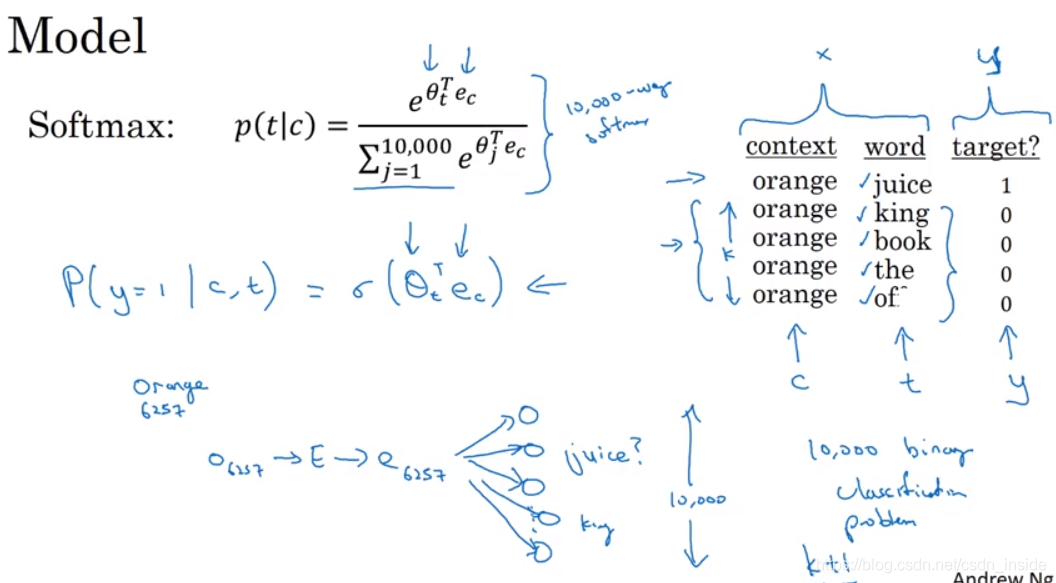
负采样从文本中,采样出K个负例,比如这里的orange king、orange book等。
关于采样具体采样多少负例,有一个经验公式:

GloVe vectors
详见:GloVe :Global Vectors 全局向量 模型详解 公式推导
Application using Word Embeddings
Sentiment Classification
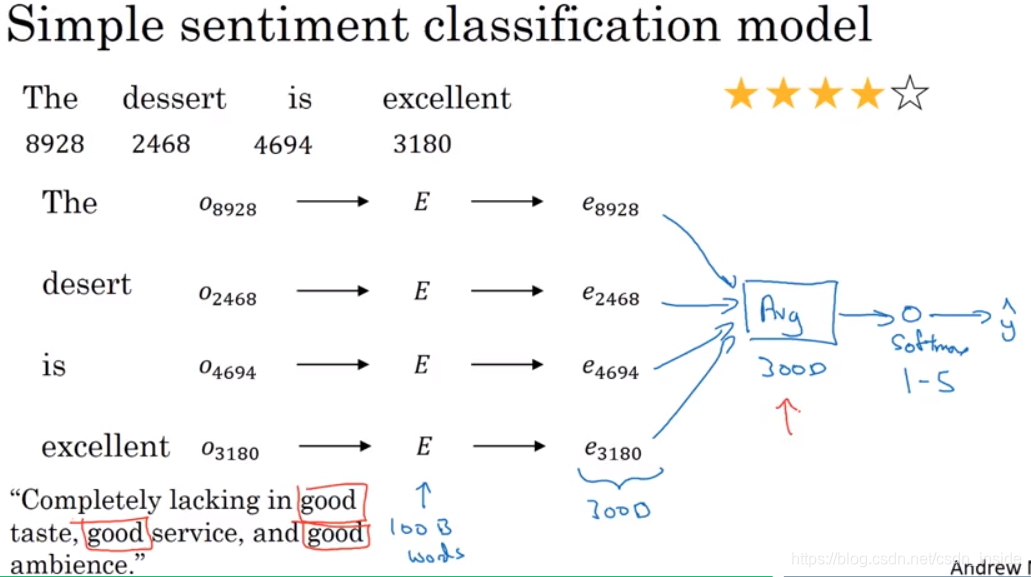
情感分析大致也有两种方法,第一种很简单,将句子里所有单词的词向量加在一起,然后平均,最后送入softmax,进行训练。
这种方法,有个弊端,当句子出现大量good,而所有good前面有一个否定词时,就会嗝儿屁。(good的比重太大,模型会以为是“好”的)。
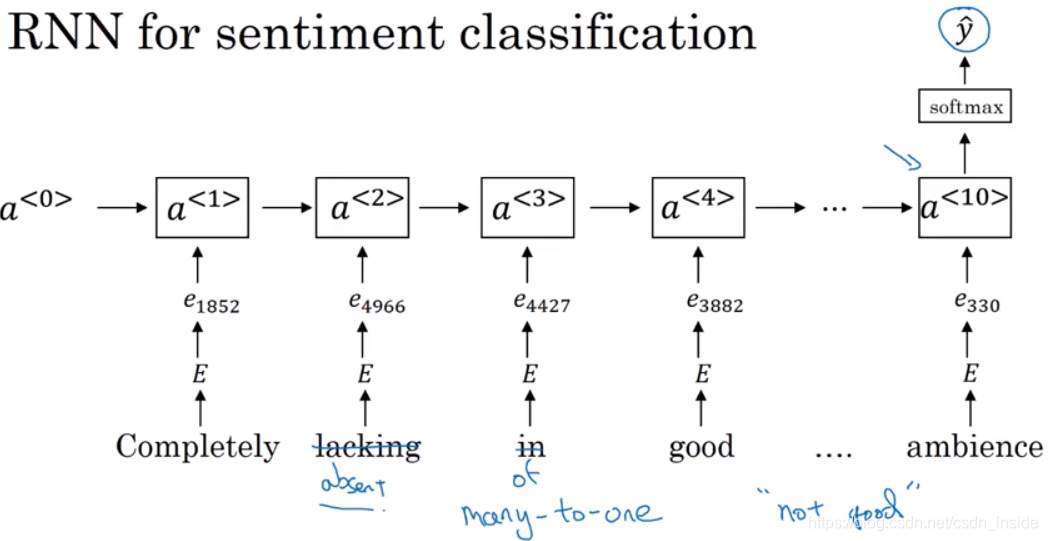
这样就引出了第二种方法,基于RNN的,是一个典型的many-to-one模型。遇到lacking的同义词absent这些,通过word vector,也可以做出正确的预测。
这周的编程作业,Emojifier就用了上述两种方法。
Debiasing word embeddings
Word Embeddings会有一些“偏见”。比如像“码农”这个单词,应该是中性的。同样,“医生”也是中性的,“护士”也不是没有男的。

为了解决偏见,这里以gender性别为例,第一步是要找到gender属性的方向,怎么找?简单来讲,就是用一堆“性别”的词,进行相减,在求平均,就是gender的方向。比如用He的词向量减去She的词向量,还有Boy的词向量减去Girl的词向量,以此类推。
在确定了gender方向,也就是bias方向之后,与bias垂直的其它N-1维就是non-bias方向。第二步,就是把有“偏见”的词,投影到与bias方向垂直的non-bias方向上,比如下图把doctor和babysister投影到了non-bias方向上。第三步,就是调整距离,使其不再有偏见。
这周的编程作业,会有详细介绍。


















 36万+
36万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









