




 GloVe(Global Vectors)旨在结合矩阵分解和滑窗概率算法的优点,解决词向量表示的问题。通过共现矩阵和概率比值,GloVe发现比率能反映词对之间的内在规律。通过内积和指数函数,建立了词向量的数学模型,并引入权重项f(Xij)优化不同词的重要性。该模型在处理类比问题和全局统计特性上表现出色。
GloVe(Global Vectors)旨在结合矩阵分解和滑窗概率算法的优点,解决词向量表示的问题。通过共现矩阵和概率比值,GloVe发现比率能反映词对之间的内在规律。通过内积和指数函数,建立了词向量的数学模型,并引入权重项f(Xij)优化不同词的重要性。该模型在处理类比问题和全局统计特性上表现出色。
在cs224n Lecture 3: GloVe skipgram cbow lsa 等方法对比 / 词向量评估 /超参数调节 总结 中,
我们知道,以往生成词向量有两种算法,一种是基于矩阵分解(Matrix Factorization)的,代表有LSA,改进的HAL算法等;一种是基于滑窗概率(Shallow Window)的,代表有Skip-Gram和CBOW。这两种算法,或多或少都存在一些问题,比如,对于矩阵分解的算法而言,其共现矩阵(Co-occurence)是十分庞大的,而对其进行SVD分解,计算更是复杂,得到的词向量无法处理类比(man is to woman as king is to queen)问题;对于滑窗概率算法而言,虽然解决了计算量上的问题,效果不错,但是没有充分利用到语料的全局统计特性。GloVe算法,就是旨在克服上述两种算法的缺点,对优点“结合”了一下。
GloVe算法的如何诞生的?作者是如何想出这个idea的?大致是这样:
既然要用到语料的全局统计特性,那共现矩阵,自然是不能少的了,所以保留了矩阵分解算法的共现矩阵,就像这样:
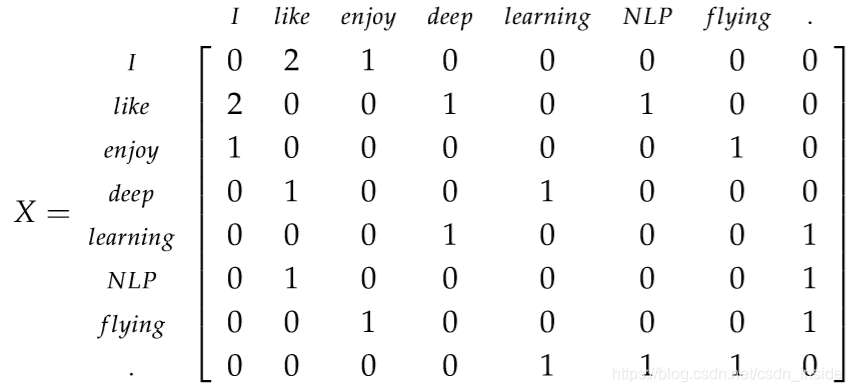
我们知道滑窗概率模型是根据概率建模的,如何把共现矩阵跟概率结合起来呢?算一下每个语境词出现在某个中心词的次数不就行了。比如这里的第一行,就是I作为中心词,其它各个词作为语境词的概率,像Like就是2/3,enjoy就是1/3。
作者做了大量实验,发现虽然和“概率”结合了起来,但是这些概率并没有什么卵用:
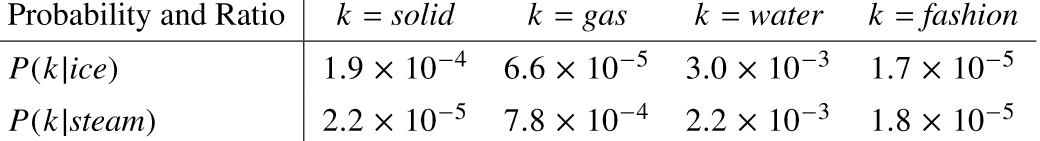
k是语境词,ice和steam分别是两个中心词,这些概率,很难看出有什么规律。但是,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









