




 本文对比了词向量的生成方法,包括基于SVD的LSA、迭代式的Skip-Gram和CBOW,以及结合两者的GloVe模型。SVD方法利用全局统计特性,但对新词处理不便;Skip-Gram和CBOW利用概率模型,速度快但忽略全局统计。GloVe则结合两者优点,表现出色。评估词向量的方法有内在和外在评估,如词类比、人类判断和模型应用效果。超参数调节对模型性能有很大影响。
本文对比了词向量的生成方法,包括基于SVD的LSA、迭代式的Skip-Gram和CBOW,以及结合两者的GloVe模型。SVD方法利用全局统计特性,但对新词处理不便;Skip-Gram和CBOW利用概率模型,速度快但忽略全局统计。GloVe则结合两者优点,表现出色。评估词向量的方法有内在和外在评估,如词类比、人类判断和模型应用效果。超参数调节对模型性能有很大影响。
生成词向量的方法
以前大致有两种方法:
①是Matrix Factorization Method,主要代表是SVD Based的LSA等方法,核心是对共现矩阵(co-occurence)进行SVD(奇异值)分解,得到词向量。
②是Iteration Based Method(Shallow window-based),主要代表是上节课讲到的Skip-Gram和CBOW。核心是概率,通过设置滑窗、中心词、找到语境词,对语料进行循环、迭代,使概率最大。
而最新的是:
③GloVe模型(Global Vectors,全局向量),把上述两种方法结合了一下,克服了两者的弱点。
SVD Based
SVD Based的种类
①是基于词库(Word document)的。这个词库,也就是不同的类别,比如有动物类别(dog/cat/pig等),细分一点,还可以分为哺乳动物、啮齿动物、鸟类等等。然后,把单词表的每一个单词,进行分类:比如"bank银行"、"bonds债务"、"stocks股份"、"money钱",它们很明显都会分到"finance金融"这个类,以此类推。最终形成了一个庞大矩阵(类别数量M*单词表数量V)。很明显,类别分得越细(M越大)、词量越大(V越大),效果越好,但带来的坏处是,矩阵将会十分十分庞大,而对其进行SVD分解,更耗费时间和计算机资源!显然需要改进。
②除了用上述“分类”的方法来构建共现矩阵外,还可以使用类似Skip-Gram的“滑窗”来构建,这也就是基于滑窗的方法,看一个例子:
假设我们有一个很简单的语料,三个句子:

设置滑窗大小为1,那么出现的词对有(这里.作为终止符EOF也要统计进去):
I enjoy、enjoy flying、flying .、I like、like NLP、NLP .、I like、like deep、deep learning、learning .。
然后统计成一个表格,这个表格就是基于“滑窗”的共现矩阵:比如I在like的上文出现了2次,所以计数就是2。
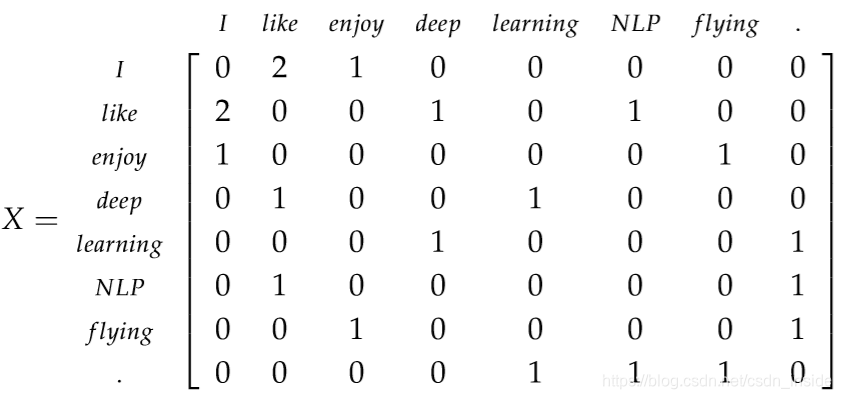
接下来,对这个矩阵进行SVD分解,选择前k个最大的奇异值,找到其对应的向量作为词向量即可。
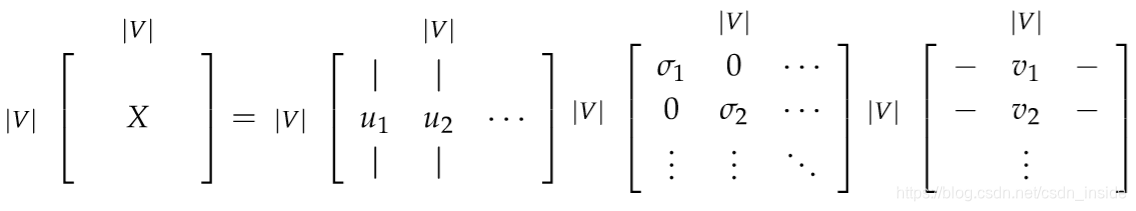
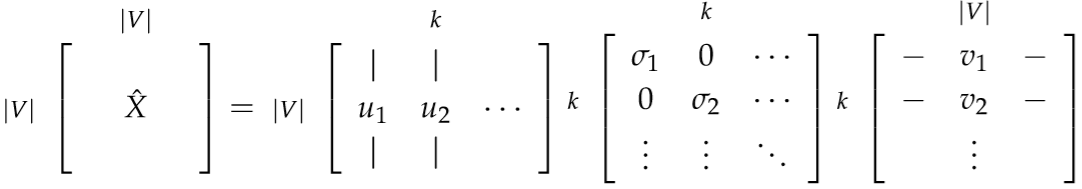
SVD Based的优点
很好的利用了语料的全局统计特性。获得的词向量可以很好的做近似(比如投影到2D空间,同类的词聚在一起)
SVD Based的缺点
①新词的加入和语料的变化会导致矩阵经常改变,重新进行SVD分解,不方便。
②共现矩阵是大量稀疏的,因为很多单词并没有联系,不会co-occur。
③一般情况下,矩阵维度巨大(10^6 * 10^6)。
④进行SVD分解,计算代价巨大。
⑤频繁出现的词与罕见词之间的不平衡。
SVD Based的改进
①针对第⑤点,可以忽略掉像"the"、"he"、"has"这类十分常见又无特定意义的作用词。
②改变计数的方式:比如采用权重计数,对于相距比较远的两个词,其计数不再是1,可以是0.5,越远越小。还可以使用皮尔森相关系数等方法,来改变计数。
Iteration Based(Shallow window-based)
与基于矩阵分解的方法不同,此类方法是从概率出发,简单来讲:
对于以下这个句子:
![]()
模型会给出一个比较高的概率,因为这个句子是“合理”的,但如果是:
![]()
这个句子根本念不通,所以模型会给出一个很低的概率。
假定各个词之间相互独立,则联合概率是:
![]()
但事实上,各个单词不可能完全独立,或多或少都有上下文的联系,所以改进一下,以前后词对进行计算:
![]()
这也就是skip-gram的雏形了。
Iteration Based的种类
①Skip-gram
②CBOW
具体的可看:Skip-Gram and CBOW
Iteration Based的优点
通过负采样算法,速度要比矩阵分解快很多。获得的词向量可以很好的做类比(man is to wowan as king is to __)。
Iteration Based的缺点
没用利用语料的全局统计特性。
GloVe
有没有一种即用到全局统计特性,又用到概率模型的方法呢?答案是有的,也就是GloVe模型,在类比方面要比上述方法强大很多,其它领域的表现也要比上述方法都好,可谓是一种state-of-the-art模型。
原理这里就不多述了,关于GloVe详细过程以及论文解读可看:
GloVe :Global Vectors 全局向量 模型详解 公式推导
评估词向量的方法
有两种,一种是Intrinsic Evaluation(内部评估),一种是Extrinsic Evaluation(外部评估)。【ps:这里我觉得intrinsic应该叫extrinsic。。。extrinsic应该叫intrinsic。。看后面——】
Intrinsic Evaluation
虽然字面翻译,叫内部评估,但是从原理来讲,我觉得应该叫外部评估。。。
因为这种方法,借用了“外界”的评估标准。
主流的有两个标准:
①word analogies,词类比。又分为词意(semantic)和词法(syntactic)。
②human judgments,先人为的给两个词有多相近打分,再以这个分作为评判的标准。
word analogies
word analogies类似man is to wowan as king is to __这类问题,原理是计算
![]()
![]() 。一般选取cosine距离:
。一般选取cosine距离:
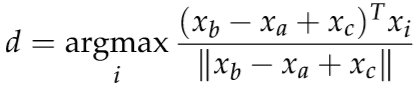
网上有很多开源的word analogies的包,一般分为词意和词法。
对于词意:
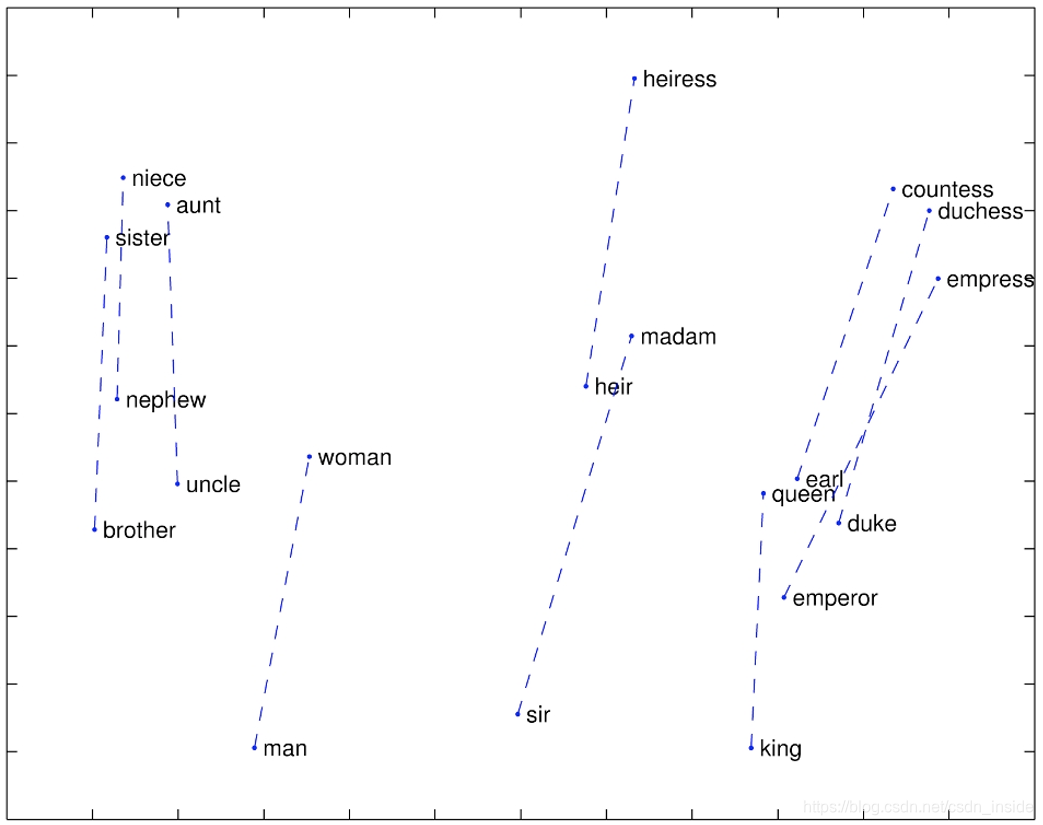
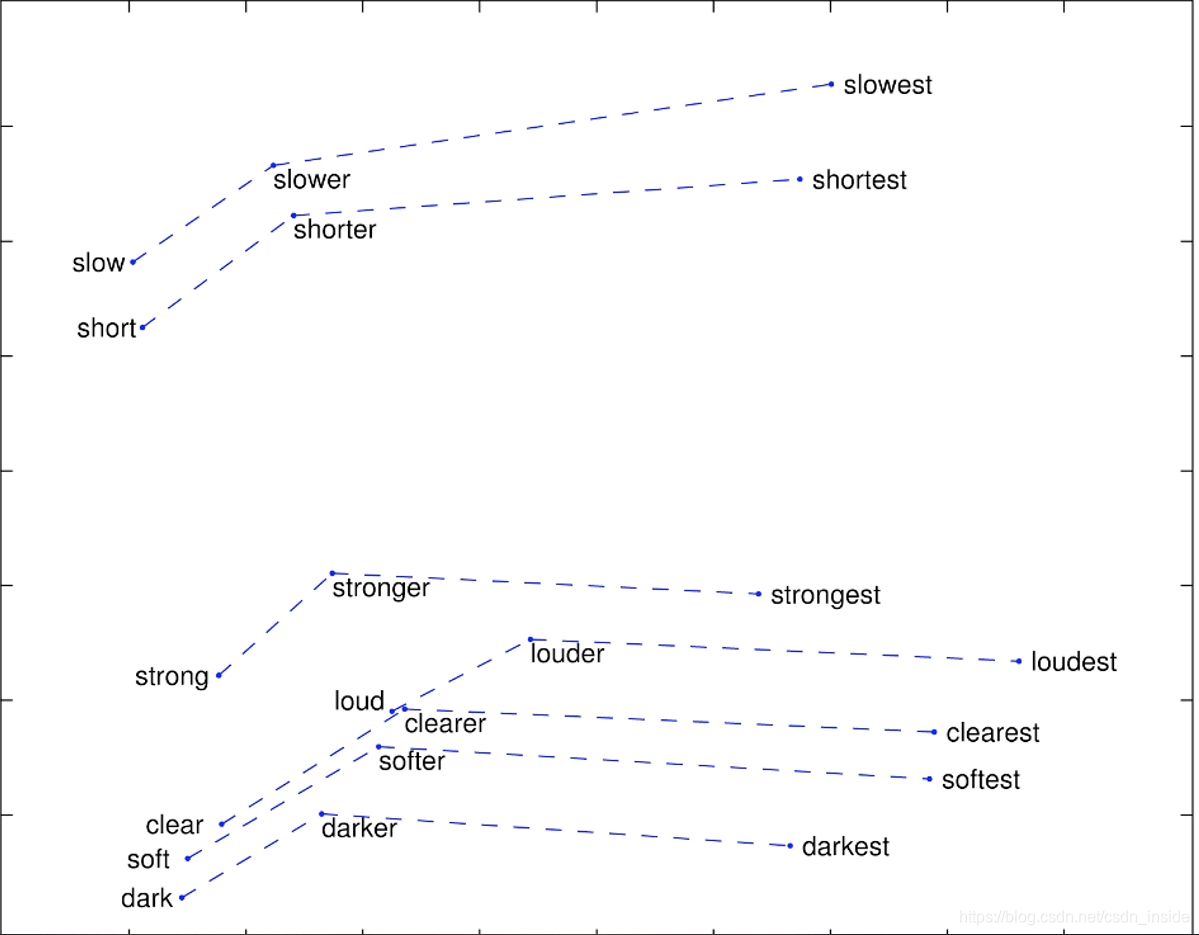
对于词法:
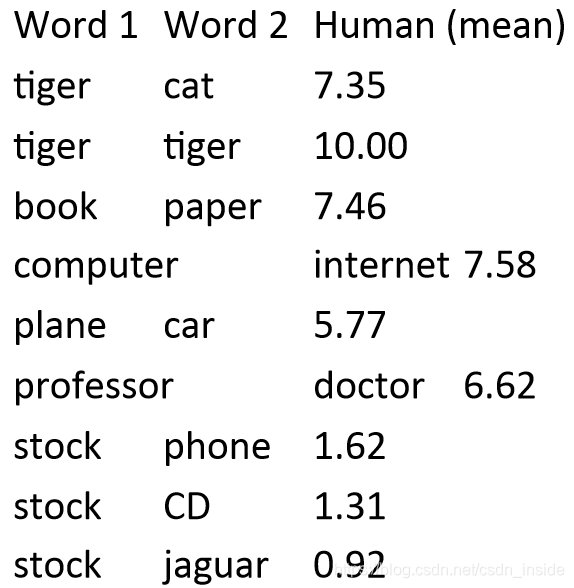
human judgments
有WS353、MC、RG、SCWS、RW等开源的包。
Extrinsic Evaluation
虽然叫“外部”,其实原理而言,我觉得是“内部”。
所谓extrinsic evaluation,说白了,就是不借助外面的Benchmark,比如CV的imageNet,这里的WS353。
而是像传统的机器学习一样,利用Dev sets和Test sets,来计算模型的准确率,从而评估一个模型的好坏。
比如,对于一个“命名实体识别”系统(named-entity recognition:NER),有以下Dev或者Test样例:
![]()
正确的分类是:
![]()
![]()
![]()
![]()
如果模型把Jim分到Organization,那就错了。
这样,就像机器学习一样,来计算“分类”的正确率,从而调整模型,这就是extrinsic evaluation,是不是很像“内部”。。。
模型超参数调节
在Word Vector各个模型中,超参数有词向量的维度大小,语料的大小、语料的内容、滑窗的大小、训练时长。
不同模型、不同向量维度、滑窗、语料,效果对比
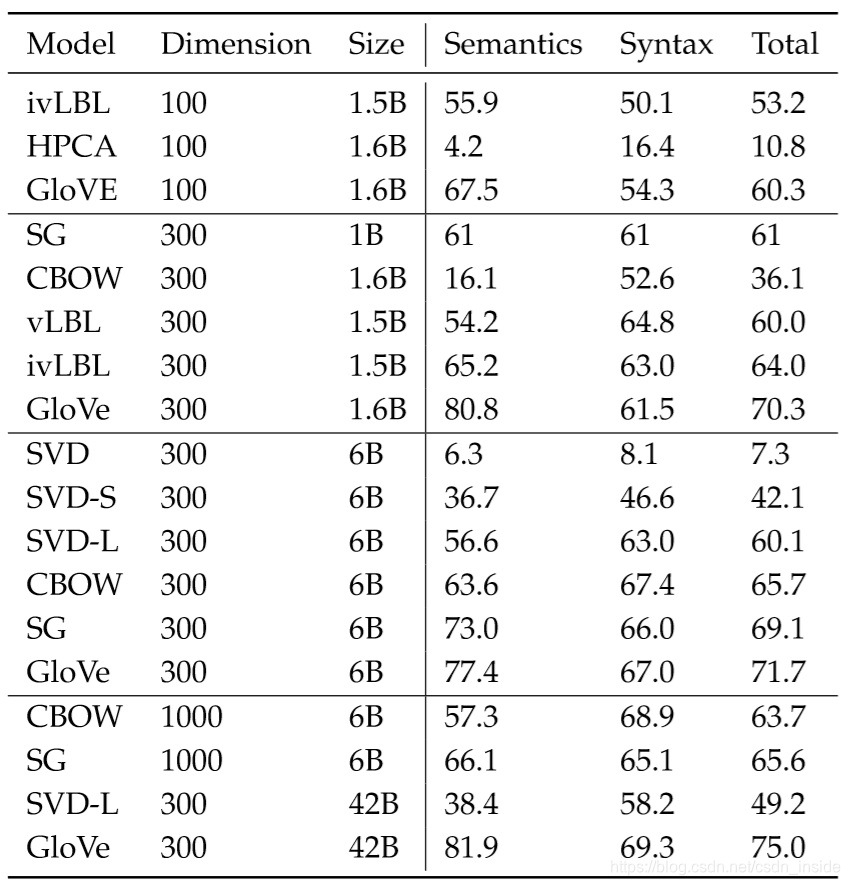
控制变量,逐一分析,大致规律:
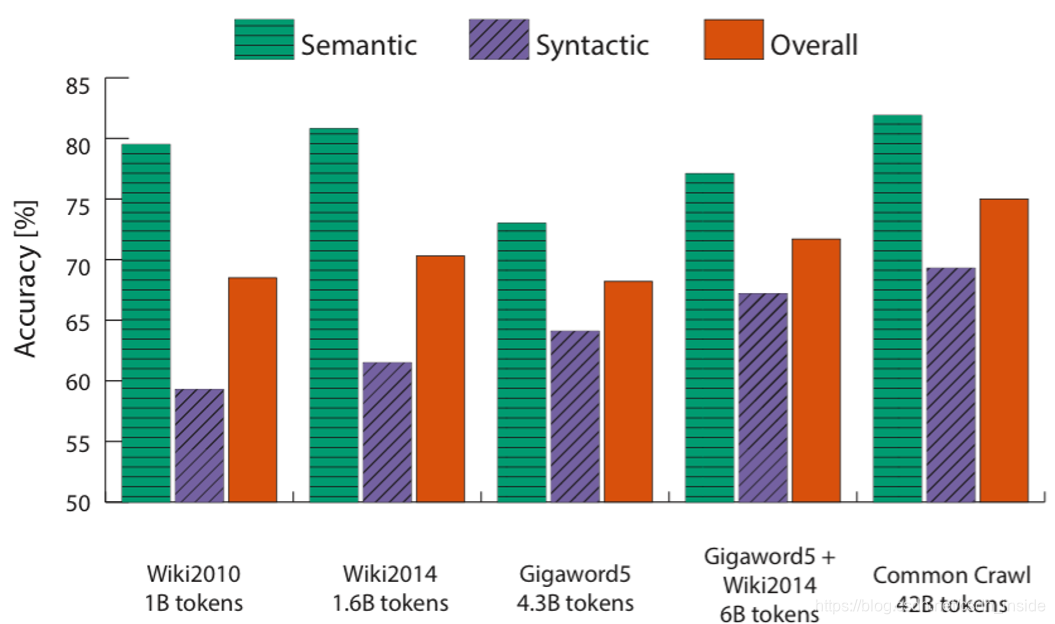
同语料下,词向量维度越高,效果越好,但是词向量维度最后会趋于饱和。比如第三行的GloVe在1.6B的语料下,100维度得分才60.3,而第8行,GloVe在同样的语料下,300维度得分提升到了70.3。
同词向量维度下,语料越大,效果越好,比如第14行的GloVe在6B的语料下,评分为71.7,比第8行1.6B的70.3高。
同时还依赖于语料的内容。下图中,第三列Gigaword5语料高达4.3B,在Semantic方面,效果还不及1B的Wiki2010语料。
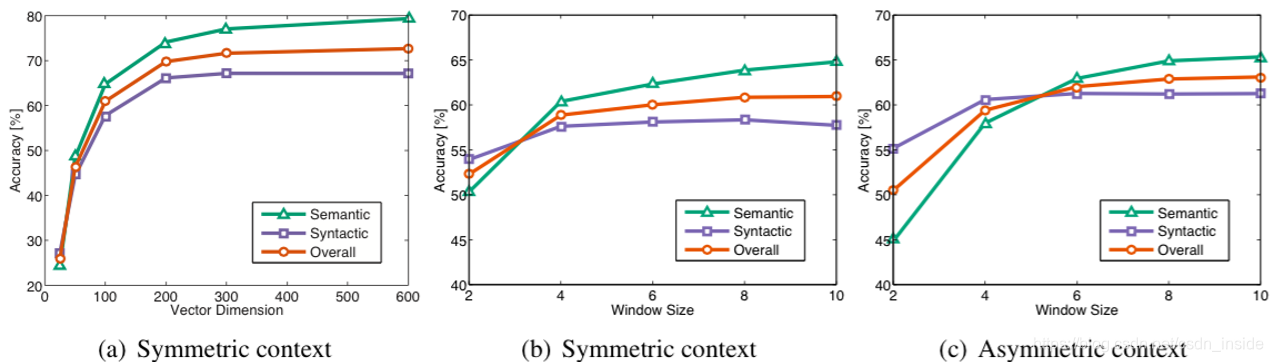
画个图其实是最直观的:对于向量维度而言,300就饱和了;对于滑窗而言,5个最合适。
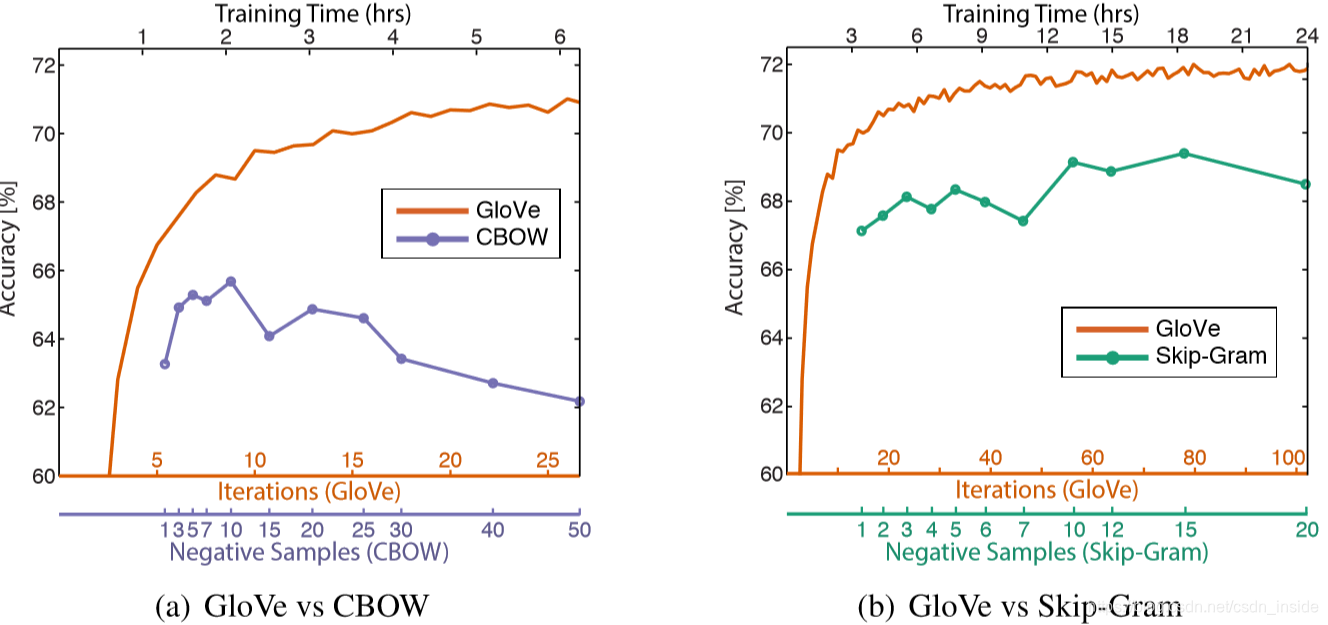
训练时长效果对比
对于GloVe而言,基本趋势是随着训练时间的增加,效果逐渐变好,但最后还是会收敛。
对于基于NS的Skip-gram/CBOW,如果负采样的数量太大(超过10),反而会降低效果。
参考资料:
GloVe论文

















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









