




大家好,大型语言模型(LLMs)正引领人工智能技术的创新浪潮。自从OpenAI推出ChatGPT,企业、开发者纷纷寻求定制化的AI解决方案,从而催生了对开发和管理这些模型的工具和框架的巨大需求。
LlamaIndex和LangChain作为两大领先框架,二者各自的特点和优势,将决定它们在不同场景下的应用。本文介绍这两个框架的主要差异,帮助大家做出明智的选择。
1 LlamaIndex
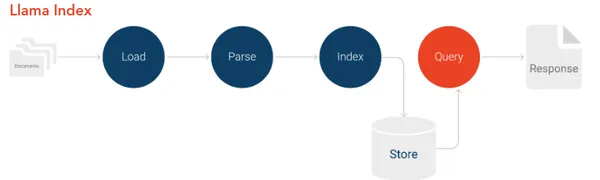
LlamaIndex 流程
LlamaIndex框架简化了对大型语言模型的个性化数据索引和查询,支持多种数据类型,包括结构化、非结构化及半结构化数据。
LlamaIndex通过将专有数据转化为嵌入向量,使数据能够被最新型的LLMs广泛理解,从而省去了重新训练模型的步骤,提高数据处理的效率和智能化水平。
1.1 工作原理
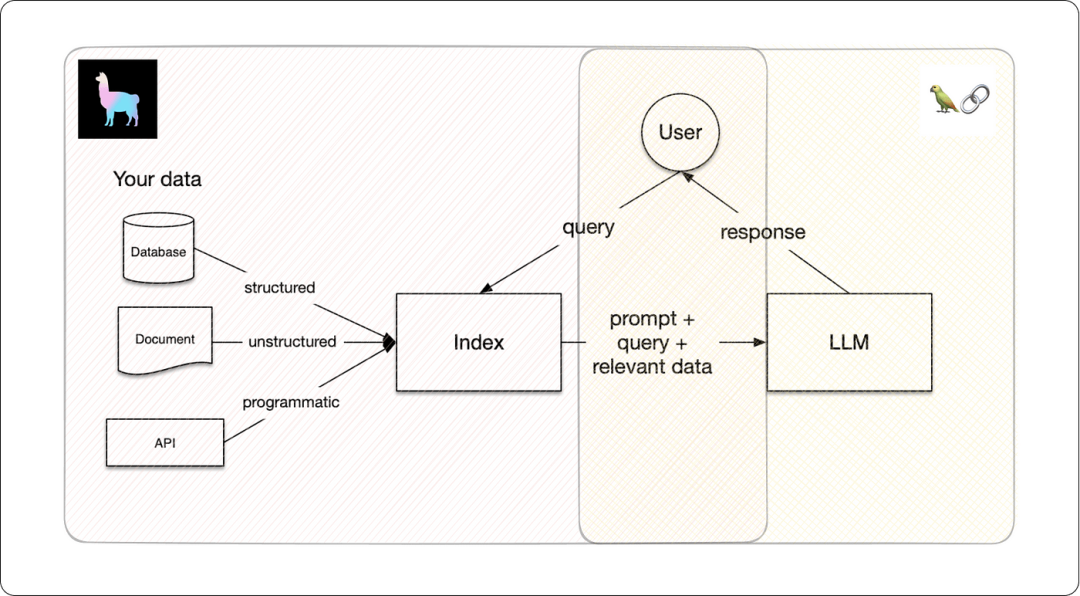
LlamaIndex 架构
LlamaIndex框架推动了大型语言模型(LLMs)的定制化发展。通过将专属数据嵌入内存,使模型在提供上下文相关回答时表现更佳,将LLMs塑造成领域知识专家。无论是作为AI助手还是对话机器人,LlamaIndex都能根据权威资料(如仅限高层访问的业务信息PDF)准确回应查询。
LlamaIndex采用检索增强生成(RAG)技术,定制化LLMs,包括两个核心步骤:
-
索引阶段:将专有数据转化为富含语义信息的向量索引。
-
查询阶段:系统接收到查询后,迅速匹配并返回最相关的信息块,结合原始问题,由LLM生成精准答案。
1.2 LlamaIndex快速入门
安装llama-index:
pip install llama-index
使用 OpenAI 的 LLM 需要 OpenAI API 密钥。获得秘钥后,在 .env 文件中这样设置:
import os
os.environ["OPENAI_API_KEY"] = "your_api_key_here"
1.3 构建问答应用:LlamaIndex实践
为了展示LlamaIndex的能力,下面进行代码演示,开发一个基于自定义文档回答问题的问答应用程序。
安装依赖项:
pip install llama-index openai nltk
使用LlamaIndex的SimpleDirectoryReader函数加载文档,开始构建索引:
from llama_index.core import (
& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1271
1271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











