




大家好,在机器学习模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络时,过拟合具体表现在模型训练数据损失函数较小,预测准确率较高,但是在测试数据上损失函数比较大,预测准确率较低。Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
1.机器学习中的Dropout正则化
Dropout正则化是机器学习领域中一种有效的技术,通过随机丢弃神经网络中的某些单元,实现对多个不同网络架构的并行训练。
这种方法对于减少模型在训练过程中的过拟合现象非常关键,有助于提升模型的泛化能力。
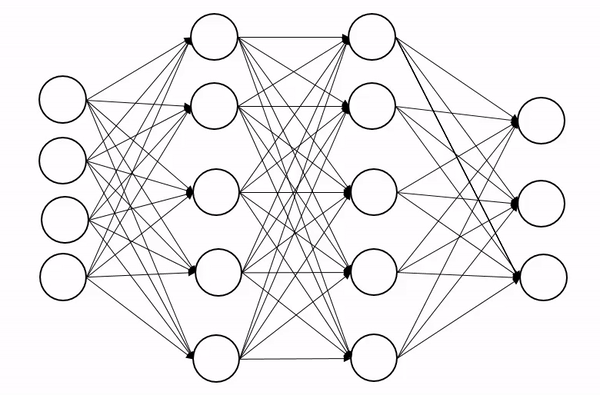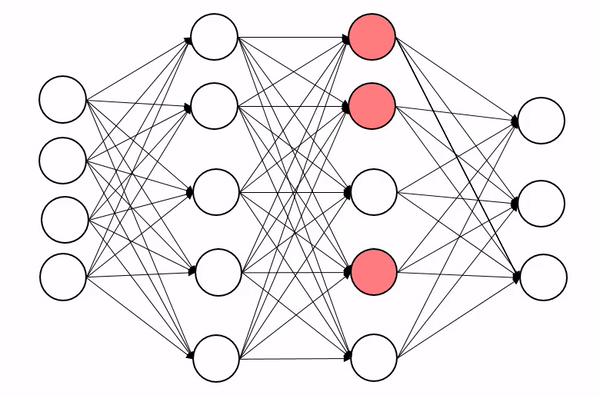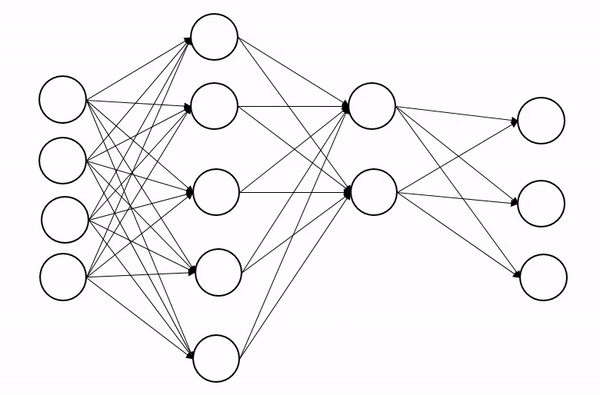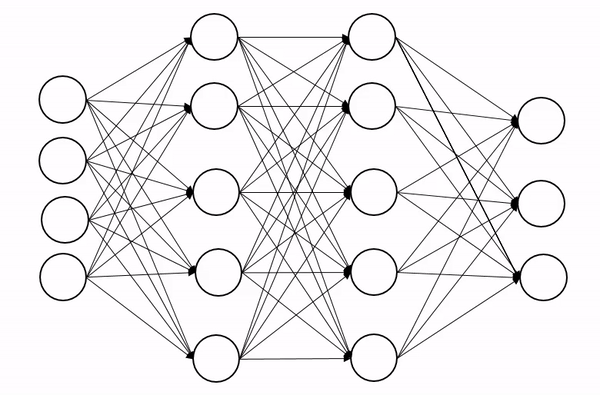
深度网络
2.在PyTorch模型中集成Dropout
要在PyTorch模型中加入Dropout正则化,可以使用torch.nn.Dropout类来实现。这个类需要一个Dropout率作为输入参数,表示神经元被关闭的可能性,这可以应用于任何非输出层。
self.dropout = nn.Dropout(0.25)
3.观察Dropout对模型性能的影响
为了研究Dropout的效果,这里将训练一个用于图像分类的模型。最初,训练一个经过正则化的网络,然后是一个没有Dropout正则化的网络。两个模型都将在Cifar-10数据集上训练8个周期。
步骤1:首先,将导入需要实现网络的依赖项和库。
import torch
from torch import nn
from torch import optim
from torch.nn import functional as F
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
步骤2:将加载数据集并准备数据加载器。
BATCH_SIZE = 32
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root="./data", train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root="./data", train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=BATCH_SIZE,
shuffle=False, num_workers=2)
CLASS_NAMES = ("plane", "car", "bird", "cat",
"deer", "dog", "frog", "horse", "ship", "truck")
步骤3:加载并可视化一些数据
def show_batch(image_batch, label_batch):
plt.figure(figsize=(10,10))
for n in range(25):
ax = plt.subplot(5,5,n+1)
img = image_batch[n] / 2 + 0.5 # 取消归一化
img = img.numpy()
plt.imshow(np.trans 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











