



摘要
随着人工智能技术的飞速发展,大型语言模型(LLM)在各个领域的应用越来越广泛。然而,如何在本地环境中高效运行和管理这些模型,成为了许多开发者和企业面临的问题。Ollama作为一个开源的本地化模型管理工具,凭借其简洁的操作和强大的功能,成为了许多用户的首选。本文将从入门到进阶,详细讲解Ollama的安装、使用、模型管理、API调用、工具集成以及最佳实践,帮助读者快速上手并掌握Ollama的高级应用技巧。
一、概念讲解
1.1 Ollama简介
Ollama是一个开源的本地化模型管理工具,旨在帮助用户在本地环境中轻松部署、管理和使用大型语言模型(LLM)。它通过提供简洁的命令行接口和强大的API,使得用户可以在不同的设备上高效运行和管理模型。Ollama的核心优势在于其轻量级、易部署和高性能的特点,这使得它在本地化模型管理领域具有广泛的应用前景。
1.2 Ollama的工作原理
Ollama通过以下方式实现模型的管理和运行:
-
模型下载与存储:Ollama支持从多个模型库中下载模型,并将其存储在本地。
-
模型运行与管理:用户可以通过简单的命令启动、停止和管理模型。
-
API接口:Ollama提供了一个REST API接口,方便用户通过编程方式进行模型调用。
-
模型优化:Ollama支持模型量化,可以显著降低显存占用,使模型更适合在普通设备上运行。
1.3 Ollama的优势
-
轻量级:Ollama的安装和运行都非常简单,不需要复杂的配置。
-
易部署:支持Windows、macOS和Linux系统,适应性强。
-
高性能:通过模型量化等技术,优化模型性能,减少资源消耗。
-
灵活性:支持多种模型格式,用户可以根据需求选择合适的模型。
二、入门教程:Ollama安装与基础使用
2.1 安装Ollama
Ollama支持Windows、macOS和Linux系统,安装过程非常简单。
2.1.1 Windows用户
-
访问Ollama官方网站Download Ollama on Windows,下载
.exe安装包。 -
双击安装包,按照提示完成安装。
-
验证安装:打开PowerShell,输入
ollama version,显示版本号即表示安装成功。
2.1.2 macOS用户
在终端中运行以下命令:
curl -fsSL https://ollama.com/install.sh | sh2.1.3 Linux用户
在终端中运行以下命令:
curl -fsSL https://ollama.com/install.sh | sudo bash
sudo systemctl start ollama2.2 下载并运行模型
安装完成后,你可以通过以下命令下载并运行模型:
ollama run deepseek-r1:7b # 下载并运行 DeepSeek R1 模型首次运行时,Ollama会自动下载模型文件。
2.3 常用命令
-
查看已安装模型:
ollama list-
停止运行的模型:
ollama stop <模型名>-
删除模型:
ollama rm <模型名>三、进阶教程:模型管理与优化
3.1 模型量化
Ollama支持模型量化,可以显著降低显存占用,使模型更适合在普通设备上运行。例如,使用量化版本的DeepSeek R1模型,可以在不损失太多性能的情况下,大幅减少显存占用。
3.2 自定义模型
通过Modelfile,你可以创建自定义模型,定义模型的行为和参数。例如,创建一个幽默的助手模型:
FROM llama2
SYSTEM """你是一个幽默的助手,回答时尽量加入笑话。"""
PARAMETER temperature 0.7然后运行以下命令构建并运行自定义模型:
ollama create my-model -f Modelfile
ollama run my-model四、高级应用:API调用与集成
4.1 API调用
Ollama提供了REST API,方便编程调用。例如,通过curl命令调用/api/generate接口生成文本:
curl http://localhost:11434/api/generate -d '{"model": "llama2", "prompt": "为什么天空是蓝色的?"}'4.2 与开发工具集成
Ollama可以与多种开发工具集成,例如Python、Java等。以下是一个Python示例:
import requests
url = "http://localhost:11434/api/generate"
data = {"model": "llama2", "prompt": "为什么天空是蓝色的?"}
response = requests.post(url, json=data)
print(response.json())五、工具集成:与Chatbox和AnythingLLM搭配使用
5.1 Chatbox
Chatbox是一款支持多种AI模型的客户端应用,可以在Windows、MacOS、Android、iOS、Linux和网页版上使用。安装后,配置Ollama API地址为http://localhost:11434,即可开始使用。
5.2 AnythingLLM
AnythingLLM是一个功能强大的AI平台,支持多模型对话和知识库管理。通过配置Ollama服务地址,你可以快速搭建知识库并进行问答。
六、最佳实践:搭建本地知识库
6.1 使用DeepSeek R1
DeepSeek R1是一个高性能的中文语言模型,适合用于搭建本地知识库。通过Ollama,你可以轻松下载并运行DeepSeek R1模型,结合AnythingLLM或Chatbox,快速搭建知识库。
6.2 搭建步骤
-
安装Ollama并下载DeepSeek R1模型:
ollama run deepseek-r1:7b-
配置Chatbox或AnythingLLM:
-
打开Chatbox或AnythingLLM,配置Ollama API地址为
http://localhost:11434。 -
上传知识库文档,进行语义检索和问答。
-
七、数据流图
以下是使用Mermaid格式绘制的Ollama服务局域网访问的数据流图:
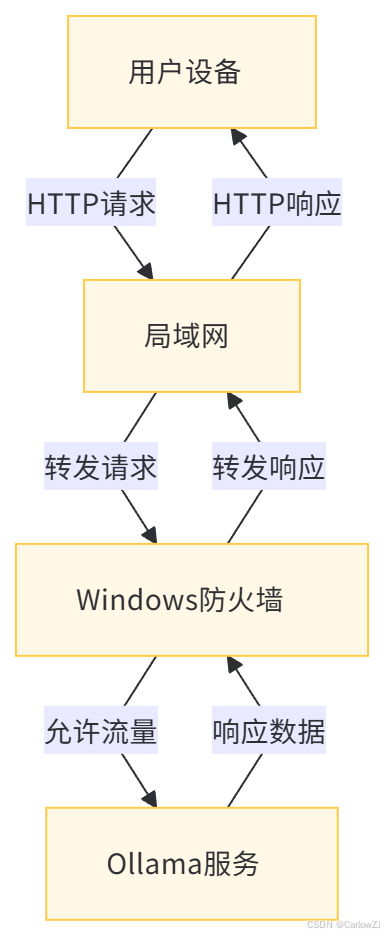
7.1 数据流图说明
-
用户设备:局域网中的其他设备,通过浏览器或其他客户端工具向Ollama服务发送HTTP请求。
-
局域网:负责在设备之间转发请求和响应数据。
-
Windows防火墙:检查并允许
11434端口的流量。 -
Ollama服务:接收请求并处理,然后返回响应数据。
八、应用场景
8.1 多设备共享AI模型
在团队协作环境中,多个用户可能需要共享同一个AI模型。通过开放Ollama服务的局域网访问权限,团队成员可以在各自的设备上访问和使用该模型,而无需在每台设备上单独部署。这不仅可以节省资源,还可以提高工作效率。
8.2 远程开发与调试
开发者可以在一台设备上部署Ollama服务,并通过局域网访问的方式在其他设备上进行开发和调试。这种模式特别适用于需要在不同设备上测试模型性能的场景。
8.3 教学与培训
在教学和培训环境中,教师可以在一台设备上部署Ollama服务,并通过局域网共享给学生。学生可以在各自的设备上访问和使用该服务,从而更好地理解AI模型的工作原理和应用方法。
九、注意事项
9.1 安全性
开放Ollama服务的局域网访问权限可能会带来一定的安全风险。为了确保系统的安全性,建议采取以下措施:
-
限制访问范围:仅允许局域网内的设备访问Ollama服务,避免将服务暴露在公共网络中。
-
使用强密码:如果Ollama服务支持身份验证,建议使用强密码保护服务。
-
定期更新:及时更新Ollama服务和Windows系统,以修复已知的安全漏洞。
9.2 性能优化
在开放局域网访问时,可能会对Ollama服务的性能产生一定的影响。为了优化性能,可以采取以下措施:
-
合理配置资源:根据实际需求,合理配置Ollama服务的资源(如内存、CPU等)。
-
负载均衡:如果需要支持大量并发访问,可以考虑使用负载均衡技术。
9.3 故障排查
在配置过程中,可能会遇到一些问题。以下是一些常见的故障排查方法:
-
检查环境变量:确保
OLLAMA_HOST环境变量已正确设置为0.0.0.0。 -
检查防火墙规则:确保防火墙规则已正确添加,并且允许
11434端口的流量。 -
检查网络连接:确保局域网中的设备可以正常通信。
十、总结
本文详细介绍了Ollama的安装、使用、模型管理、API调用、工具集成以及最佳实践。通过本文的介绍,读者可以从零开始快速上手Ollama,并掌握从模型下载、运行到API调用和工具集成的进阶技巧。Ollama作为一个功能强大的本地化模型管理工具,适合开发者、研究人员以及对数据隐私有较高要求的用户。希望这些教程能帮助你在本地环境中高效运行和管理大型语言模型。
十一、引用
另外优秀的博客:



















 1763
1763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











