



摘要
在使用AnythingLLM或Dify等本地大语言模型应用时,开发者经常遇到一个令人头疼的问题:每次对话都需要重新加载模型,严重影响性能和用户体验。本文针对中国AI应用开发者,深入分析了这一问题的根本原因,并提供了从环境配置到API调用优化的全方位解决方案。通过详细的实践示例、架构图、流程图等可视化内容,帮助读者快速定位并解决模型重载问题。文章还涵盖了常见问题解答、最佳实践建议及扩展阅读资源,确保读者能够高效应用所学知识,提升AI应用的性能和用户体验。
思维导图:知识点全景

mindmap
root((Ollama模型重载问题))
问题描述
每次对话模型重载
keep_alive参数失效
响应时间过长
原因分析
环境变量配置问题
API调用参数错误
应用层配置不当
系统资源限制
解决方案
环境变量设置
API参数优化
应用配置调整
系统优化
实践案例
AnythingLLM配置
Dify配置
Python调用示例
注意事项
环境变量持久化
模型预加载
资源监控
最佳实践
keep_alive设置策略
监控与日志分析
性能调优
扩展阅读
Ollama官方文档
替代工具介绍
高级配置选项
1. 问题描述
在使用Ollama配合AnythingLLM或Dify等本地大语言模型应用时,开发者经常遇到一个令人困扰的问题:每次对话都需要重新加载模型,即使已经设置了模型保持时间。这一问题严重影响了应用的性能和用户体验。
1.1 现象特征
- 每次发送请求时,模型都会重新加载
- 模型存活时间设置为永久(
-1),但模型仍然会卸载 - 响应时间显著延长,用户等待时间增加
- 系统资源(CPU、内存、GPU)使用率异常波动
1.2 影响分析
性能问题:每次加载模型都会消耗大量时间和计算资源,导致响应延迟显著增加。对于大型模型(如Llama2 70B),加载时间可能长达数分钟。
用户体验:响应时间变长,用户等待时间增加,严重影响交互体验。在生产环境中,这可能导致用户流失和满意度下降。
资源浪费:频繁加载和卸载模型会增加系统负担,浪费计算资源,降低整体系统效率。
2. 原因分析
要解决模型频繁重载问题,首先需要深入理解其根本原因。通过分析Ollama的工作机制和常见配置错误,我们可以将问题归结为以下几个方面:
2.1 环境变量配置问题
最常见的问题是OLLAMA_KEEP_ALIVE环境变量未正确设置或未生效:
- 环境变量名称拼写错误
- 变量值设置不正确(应为
-1表示永久保持) - 变量未正确持久化,重启后失效
- 多个环境变量设置冲突
2.2 API调用参数错误
在调用Ollama API时,keep_alive参数未正确传递或设置:
- 参数名称错误(应为
keep_alive) - 参数值设置不正确
- 参数类型错误(应为整数或字符串)
- 参数未在每次请求中正确传递
2.3 应用层配置不当
AnythingLLM或Dify等应用的配置问题:
- 应用未正确连接到Ollama服务
- 应用配置中未启用模型保持功能
- 应用版本与Ollama版本不兼容
- 应用配置文件中参数设置错误
2.4 系统资源限制
系统层面的限制也可能导致模型卸载:
- 内存不足导致系统自动卸载模型
- GPU显存不足
- 系统自动清理机制触发
- 并发请求过多导致资源竞争
3. 解决方案
针对上述问题,我们提供一套完整的解决方案,从环境配置到API调用优化,全方位解决模型重载问题。
3.1 Ollama环境变量配置优化
3.1.1 Windows系统配置
在Windows系统中,需要通过系统环境变量进行配置:
- 在任务栏中退出Ollama服务
- 搜索并打开"环境变量"设置
- 在"系统变量"区域点击"新建"
- 添加以下变量:
- 变量名:
OLLAMA_KEEP_ALIVE - 变量值:
-1
- 变量名:
- 点击"确定"保存设置
- 重新启动Ollama服务
3.1.2 Linux系统配置
在Linux系统中,可以通过以下命令配置:
# 编辑bash配置文件
echo "export OLLAMA_KEEP_ALIVE=-1" >> ~/.bashrc
# 使配置生效
source ~/.bashrc
# 重启Ollama服务
sudo systemctl restart ollama
3.1.3 macOS系统配置
在macOS系统中,配置方法如下:
# 编辑zsh配置文件(如果使用zsh)
echo "export OLLAMA_KEEP_ALIVE=-1" >> ~/.zshrc
# 使配置生效
source ~/.zshrc
# 重启Ollama服务
brew services restart ollama
3.2 API调用参数优化
在调用Ollama API时,确保正确传递keep_alive参数:
3.2.1 Python调用示例
import requests
import json
def generate_with_keep_alive(model_name, prompt):
"""
调用Ollama API并设置keep_alive参数
:param model_name: 模型名称
:param prompt: 用户输入提示
:return: API响应
"""
url = "http://localhost:11434/api/generate"
# 构造请求数据,包含keep_alive参数
data = {
"model": model_name,
"prompt": prompt,
"keep_alive": -1, # 设置为-1表示永久保持模型加载
"stream": False # 根据需要设置是否流式输出
}
try:
# 发送POST请求
response = requests.post(
url,
json=data,
headers={"Content-Type": "application/json"}
)
# 检查响应状态
if response.status_code == 200:
return response.json()
else:
print(f"请求失败,状态码: {response.status_code}")
return None
except requests.exceptions.RequestException as e:
print(f"请求异常: {e}")
return None
# 使用示例
if __name__ == "__main__":
model = "llama3:8b"
prompt = "请解释什么是人工智能?"
result = generate_with_keep_alive(model, prompt)
if result:
print("模型响应:")
print(result.get("response", "无响应内容"))
3.2.2 聊天接口调用示例
import requests
import json
def chat_with_keep_alive(model_name, messages):
"""
使用Ollama聊天接口并设置keep_alive参数
:param model_name: 模型名称
:param messages: 消息历史列表
:return: API响应
"""
url = "http://localhost:11434/api/chat"
# 构造请求数据
data = {
"model": model_name,
"messages": messages,
"keep_alive": -1, # 设置为-1表示永久保持模型加载
"stream": False # 根据需要设置是否流式输出
}
try:
# 发送POST请求
response = requests.post(
url,
json=data,
headers={"Content-Type": "application/json"}
)
# 检查响应状态
if response.status_code == 200:
return response.json()
else:
print(f"请求失败,状态码: {response.status_code}")
print(f"响应内容: {response.text}")
return None
except requests.exceptions.RequestException as e:
print(f"请求异常: {e}")
return None
# 使用示例
if __name__ == "__main__":
model = "llama3:8b"
# 构造对话历史
messages = [
{
"role": "user",
"content": "你好,能介绍一下你自己吗?"
}
]
result = chat_with_keep_alive(model, messages)
if result:
print("模型响应:")
print(result.get("message", {}).get("content", "无响应内容"))
3.3 AnythingLLM配置优化
3.3.1 连接Ollama服务
在AnythingLLM中正确配置Ollama连接:
- 打开AnythingLLM应用
- 进入"Settings" > "LLM"配置页面
- 选择"LLM Provider"为"Ollama"
- 设置"Base URL"为
http://127.0.0.1:11434 - 选择已下载的模型
- 保存配置
3.3.2 验证连接状态
import requests
def check_ollama_connection():
"""
检查Ollama服务连接状态
"""
try:
# 检查Ollama是否运行
response = requests.get("http://localhost:11434/api/tags")
if response.status_code == 200:
print("✅ Ollama服务连接正常")
models = response.json().get("models", [])
print(f"📦 已加载模型数量: {len(models)}")
for model in models:
print(f" - {model['name']}")
else:
print("❌ Ollama服务连接失败")
except requests.exceptions.ConnectionError:
print("❌ 无法连接到Ollama服务,请检查服务是否启动")
# 运行连接检查
check_ollama_connection()
3.4 Dify配置优化
3.4.1 配置Ollama作为模型提供商
在Dify中配置Ollama:
- 登录Dify管理后台
- 进入"设置" > “模型提供商”
- 添加新的模型提供商,选择"Ollama"
- 设置API地址为
http://host.docker.internal:11434(Windows/macOS)或http://localhost:11434(Linux) - 保存配置并测试连接
3.4.2 Docker环境配置
如果使用Docker部署Dify,需要确保网络配置正确:
version: '3.8'
services:
dify:
image: langgenius/dify-api:0.6.5
environment:
- OLLAMA_API_BASE=http://host.docker.internal:11434
ports:
- "5001:5001"
depends_on:
- postgres
- redis
ollama:
image: ollama/ollama:latest
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
environment:
- OLLAMA_KEEP_ALIVE=-1
volumes:
ollama_data:
4. 实践案例
通过实际案例演示如何解决模型重载问题。
4.1 完整的Python应用示例
import requests
import time
import json
from typing import Optional, List, Dict
class OllamaModelManager:
"""
Ollama模型管理器,用于处理模型加载和保持
"""
def __init__(self, base_url: str = "http://localhost:11434"):
self.base_url = base_url
self.session = requests.Session()
def check_service_status(self) -> bool:
"""
检查Ollama服务状态
"""
try:
response = self.session.get(f"{self.base_url}/api/tags")
return response.status_code == 200
except:
return False
def list_models(self) -> List[str]:
"""
列出所有可用模型
"""
try:
response = self.session.get(f"{self.base_url}/api/tags")
if response.status_code == 200:
models = response.json().get("models", [])
return [model["name"] for model in models]
return []
except Exception as e:
print(f"获取模型列表失败: {e}")
return []
def generate_response(self, model: str, prompt: str, keep_alive: int = -1) -> Optional[str]:
"""
生成模型响应
"""
url = f"{self.base_url}/api/generate"
data = {
"model": model,
"prompt": prompt,
"keep_alive": keep_alive,
"stream": False
}
try:
response = self.session.post(url, json=data)
if response.status_code == 200:
result = response.json()
return result.get("response")
else:
print(f"生成响应失败: {response.status_code} - {response.text}")
return None
except Exception as e:
print(f"请求异常: {e}")
return None
def preheat_model(self, model: str) -> bool:
"""
预热模型,确保模型已加载
"""
print(f"正在预热模型: {model}")
prompt = "Hello, this is a preheat message."
response = self.generate_response(model, prompt, keep_alive=-1)
return response is not None
def main():
# 创建模型管理器实例
manager = OllamaModelManager()
# 检查服务状态
if not manager.check_service_status():
print("❌ Ollama服务未运行,请先启动服务")
return
# 列出可用模型
models = manager.list_models()
if not models:
print("❌ 未找到可用模型,请先下载模型")
return
print("📦 可用模型:")
for i, model in enumerate(models):
print(f" {i+1}. {model}")
# 选择模型
selected_model = models[0] # 默认选择第一个模型
print(f"\n🎯 选择模型: {selected_model}")
# 预热模型
if manager.preheat_model(selected_model):
print("✅ 模型预热成功")
else:
print("❌ 模型预热失败")
return
# 进行多轮对话测试
print("\n💬 开始对话测试...")
test_prompts = [
"什么是人工智能?",
"机器学习和深度学习有什么区别?",
"请推荐一些学习AI的资源"
]
for i, prompt in enumerate(test_prompts, 1):
print(f"\n--- 第{i}轮对话 ---")
print(f"用户: {prompt}")
start_time = time.time()
response = manager.generate_response(selected_model, prompt, keep_alive=-1)
end_time = time.time()
if response:
print(f"助手: {response}")
print(f"⏱️ 响应时间: {end_time - start_time:.2f}秒")
else:
print("❌ 生成响应失败")
if __name__ == "__main__":
main()
4.2 模型监控脚本
import requests
import time
import psutil
import GPUtil
from datetime import datetime
class ModelMonitor:
"""
模型监控类,用于监控Ollama模型状态和系统资源使用情况
"""
def __init__(self, ollama_url: str = "http://localhost:11434"):
self.ollama_url = ollama_url
self.session = requests.Session()
def get_system_resources(self):
"""
获取系统资源使用情况
"""
# CPU使用率
cpu_percent = psutil.cpu_percent(interval=1)
# 内存使用情况
memory = psutil.virtual_memory()
memory_percent = memory.percent
memory_used_gb = memory.used / (1024**3)
memory_total_gb = memory.total / (1024**3)
# GPU使用情况(如果有GPU)
gpu_info = []
try:
gpus = GPUtil.getGPUs()
for gpu in gpus:
gpu_info.append({
"id": gpu.id,
"name": gpu.name,
"load": f"{gpu.load*100:.1f}%",
"memory_used": f"{gpu.memoryUsed}MB",
"memory_total": f"{gpu.memoryTotal}MB"
})
except:
pass # 没有GPU或GPUtil不可用
return {
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"cpu_percent": cpu_percent,
"memory_percent": memory_percent,
"memory_used_gb": memory_used_gb,
"memory_total_gb": memory_total_gb,
"gpus": gpu_info
}
def get_ollama_status(self):
"""
获取Ollama服务状态
"""
try:
# 获取模型列表
response = self.session.get(f"{self.ollama_url}/api/tags")
if response.status_code == 200:
models = response.json().get("models", [])
return {
"status": "running",
"model_count": len(models),
"models": [m["name"] for m in models]
}
else:
return {"status": "error", "code": response.status_code}
except Exception as e:
return {"status": "unreachable", "error": str(e)}
def monitor_loop(self, interval: int = 30):
"""
持续监控循环
"""
print("🔍 开始监控Ollama服务和系统资源...")
print("按 Ctrl+C 停止监控")
try:
while True:
# 获取系统资源信息
resources = self.get_system_resources()
# 获取Ollama状态
ollama_status = self.get_ollama_status()
# 打印监控信息
print(f"\n[{resources['timestamp']}] 监控报告:")
print(f" CPU使用率: {resources['cpu_percent']:.1f}%")
print(f" 内存使用: {resources['memory_used_gb']:.2f}GB / {resources['memory_total_gb']:.2f}GB ({resources['memory_percent']:.1f}%)")
if resources['gpus']:
print(" GPU状态:")
for gpu in resources['gpus']:
print(f" GPU {gpu['id']} ({gpu['name']}): 负载 {gpu['load']}, 内存 {gpu['memory_used']}/{gpu['memory_total']}")
print(f" Ollama状态: {ollama_status['status']}")
if ollama_status['status'] == 'running':
print(f" 加载模型数: {ollama_status['model_count']}")
if ollama_status['models']:
print(f" 模型列表: {', '.join(ollama_status['models'])}")
# 等待下次监控
time.sleep(interval)
except KeyboardInterrupt:
print("\n⏹️ 监控已停止")
# 使用示例
if __name__ == "__main__":
monitor = ModelMonitor()
monitor.monitor_loop(interval=30)
5. 注意事项
在实施解决方案时,需要注意以下关键点:
5.1 环境变量持久化
确保环境变量在系统重启后仍然有效:
- Windows系统:需要将变量设置为系统变量,而非用户变量
- Linux/macOS系统:需要将变量添加到shell配置文件中(
.bashrc或.zshrc) - Docker环境:需要在Dockerfile或docker-compose.yml中正确设置环境变量
5.2 模型预加载策略
为了确保模型始终保持加载状态,可以采用以下策略:
# 启动时预加载模型
ollama run llama3:8b &
# 定时发送心跳请求以维持模型加载状态
echo "*/10 * * * * curl -X POST http://localhost:11434/api/generate -d '{\"model\":\"llama3:8b\",\"prompt\":\"heartbeat\",\"keep_alive\":-1}'" | crontab -
5.3 资源监控和管理
持续监控系统资源使用情况,防止资源耗尽:
import psutil
import time
def check_resources():
"""
检查系统资源使用情况
"""
# 检查内存使用率
memory = psutil.virtual_memory()
if memory.percent > 90:
print("⚠️ 内存使用率过高,请检查模型是否占用过多资源")
# 检查CPU使用率
cpu_percent = psutil.cpu_percent(interval=1)
if cpu_percent > 95:
print("⚠️ CPU使用率过高,请检查是否有过多并发请求")
return memory.percent, cpu_percent
# 定期检查资源使用情况
while True:
mem_percent, cpu_percent = check_resources()
print(f"内存使用率: {mem_percent:.1f}%, CPU使用率: {cpu_percent:.1f}%")
time.sleep(60) # 每分钟检查一次
6. 最佳实践
通过遵循以下最佳实践,可以进一步优化模型性能和稳定性:
6.1 模型保持时间设置策略
根据不同应用场景选择合适的keep_alive设置:
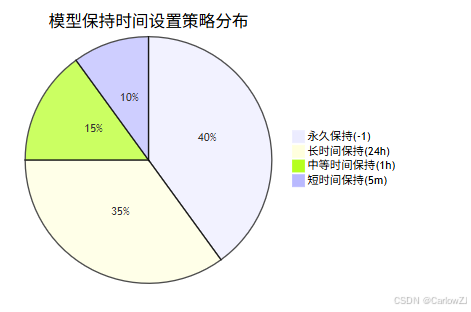
6.2 并发处理优化
合理配置并发参数以提高处理效率:
# 设置并发处理数量
export OLLAMA_NUM_PARALLEL=4
# 设置最大队列长度
export OLLAMA_MAX_QUEUE=1024
# 设置最大加载模型数量
export OLLAMA_MAX_LOADED_MODELS=3
6.3 监控与日志分析
建立完善的监控和日志分析体系:
# 查看Ollama服务日志
journalctl -u ollama -f
# 监控系统资源使用情况
watch -n 1 "free -h && nvidia-smi"
# 查看Ollama进程信息
ps aux | grep ollama
6.4 性能调优配置
根据不同硬件环境进行性能调优:
# CPU优化设置
export OLLAMA_NUM_THREAD=8 # 根据CPU核心数调整
# GPU优化设置
export OLLAMA_GPU_LAYERS=33 # 设置GPU加速层数
# 内存优化设置
export OLLAMA_CONTEXT_LENGTH=4096 # 根据需求调整上下文长度
7. 常见问题解答
7.1 环境变量设置后未生效
问题描述:设置了OLLAMA_KEEP_ALIVE=-1环境变量,但模型仍然会自动卸载。
解决方案:
- 确认环境变量已正确设置并持久化
- 重启Ollama服务使配置生效
- 验证环境变量是否在Ollama进程中可见:
# 查看Ollama进程的环境变量
ps eww -o pid,cmd,euid,egid,env | grep ollama
7.2 API调用中keep_alive参数无效
问题描述:在API调用中设置了keep_alive参数,但模型仍然会卸载。
解决方案:
- 确认参数名称和值正确(应为
keep_alive: -1) - 确认每次请求都包含该参数
- 检查Ollama版本是否支持该参数
7.3 模型加载时间过长
问题描述:模型首次加载时间过长,影响用户体验。
解决方案:
- 使用模型预加载策略
- 优化硬件配置(增加内存、使用SSD等)
- 选择更小的模型版本
7.4 多模型并发访问问题
问题描述:同时访问多个模型时出现资源竞争或加载失败。
解决方案:
- 合理设置
OLLAMA_MAX_LOADED_MODELS参数 - 使用模型加载队列管理
- 优化硬件资源配置
8. 扩展阅读
8.1 官方文档和资源
8.2 相关工具和替代方案
8.3 高级配置选项
对于需要更精细控制的用户,可以参考以下高级配置选项:
# 网络配置
export OLLAMA_HOST="0.0.0.0:11434" # 绑定到所有网络接口
export OLLAMA_ORIGINS="*" # 允许跨域访问
# 安全配置
export OLLAMA_DEBUG="1" # 启用调试模式
export OLLAMA_INTEL_GPU="1" # 启用Intel GPU支持
# 存储配置
export OLLAMA_MODELS="/data/ollama/models" # 自定义模型存储路径
实施计划甘特图
交互流程时序图
总结
本文全面分析了在使用Ollama配合AnythingLLM或Dify等本地大语言模型应用时遇到的模型频繁重载问题,并提供了从环境配置到API调用优化的全方位解决方案。
关键要点回顾:
-
问题根源:模型重载问题主要源于环境变量配置不当、API调用参数错误和应用层配置问题。
-
解决方案:
- 正确设置
OLLAMA_KEEP_ALIVE=-1环境变量并确保其持久化 - 在每次API调用中正确传递
keep_alive参数 - 优化应用层配置,确保与Ollama服务正确连接
- 正确设置
-
实施步骤:
- 环境变量配置(根据操作系统选择合适方法)
- API调用优化(Python示例代码)
- 应用配置调整(AnythingLLM和Dify配置指南)
-
最佳实践:
- 模型预加载策略
- 系统资源监控
- 性能调优配置
- 日志分析和问题诊断
实践建议:
-
逐步实施:按照本文提供的步骤逐步实施解决方案,每完成一步都要进行验证。
-
监控效果:部署监控系统,持续观察模型加载状态和系统资源使用情况。
-
持续优化:根据实际使用情况调整配置参数,找到最适合您环境的设置。
-
备份方案:准备替代方案(如Dify),以防主要方案无法满足需求。
通过正确实施本文提供的解决方案,您可以显著提升本地大语言模型应用的性能和用户体验,避免因模型频繁重载而导致的响应延迟和资源浪费问题。
参考资料
- Ollama官方文档: https://github.com/ollama/ollama
- AnythingLLM官方文档: https://docs.anythingllm.com/
- Dify官方文档: https://docs.dify.ai/
- Python requests库文档: https://docs.python-requests.org/
- psutil库文档: https://psutil.readthedocs.io/
- GPUtil库文档: https://github.com/anderskm/gputil



















 9073
9073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











