



摘要
联邦学习是一种新兴的分布式机器学习技术,旨在解决数据隐私保护与模型训练之间的矛盾。通过在多个参与方之间协作训练模型,联邦学习能够在不共享原始数据的情况下实现高效的模型优化。本文将从联邦学习的基本概念入手,逐步深入讲解其架构、代码实现、应用场景以及注意事项,并通过Mermaid格式生成相关数据流图,帮助读者全面掌握联邦学习的核心内容。
一、联邦学习概述
(一)背景与动机
随着数据隐私和安全问题的日益突出,传统的集中式机器学习方法面临着诸多挑战。数据往往分散在不同的机构或用户手中,直接共享数据可能导致隐私泄露。联邦学习应运而生,它允许数据所有者在本地进行模型训练,仅共享模型参数,从而在保护隐私的同时实现模型的联合优化。
(二)定义
联邦学习是一种分布式机器学习框架,多个参与方(客户端)在不共享数据的情况下,通过协作训练一个全局模型。其核心思想是将模型训练过程分解为多个局部训练步骤,并通过加密通信等方式确保数据隐私。
(三)优势
-
数据隐私保护:数据无需离开本地,避免了数据泄露风险。
-
模型性能提升:能够整合多个数据源的信息,提高模型的泛化能力。
-
灵活性强:支持多种机器学习算法和框架。
二、联邦学习架构
(一)架构图

(二)架构组成
联邦学习通常由以下几部分组成:
-
客户端(Client):数据所有者,负责在本地进行模型训练并上传模型参数。
-
服务器(Server):协调客户端的训练过程,聚合模型参数并更新全局模型。
-
全局模型(Global Model):由服务器维护,整合所有客户端的训练结果。
三、联邦学习流程
(一)流程图
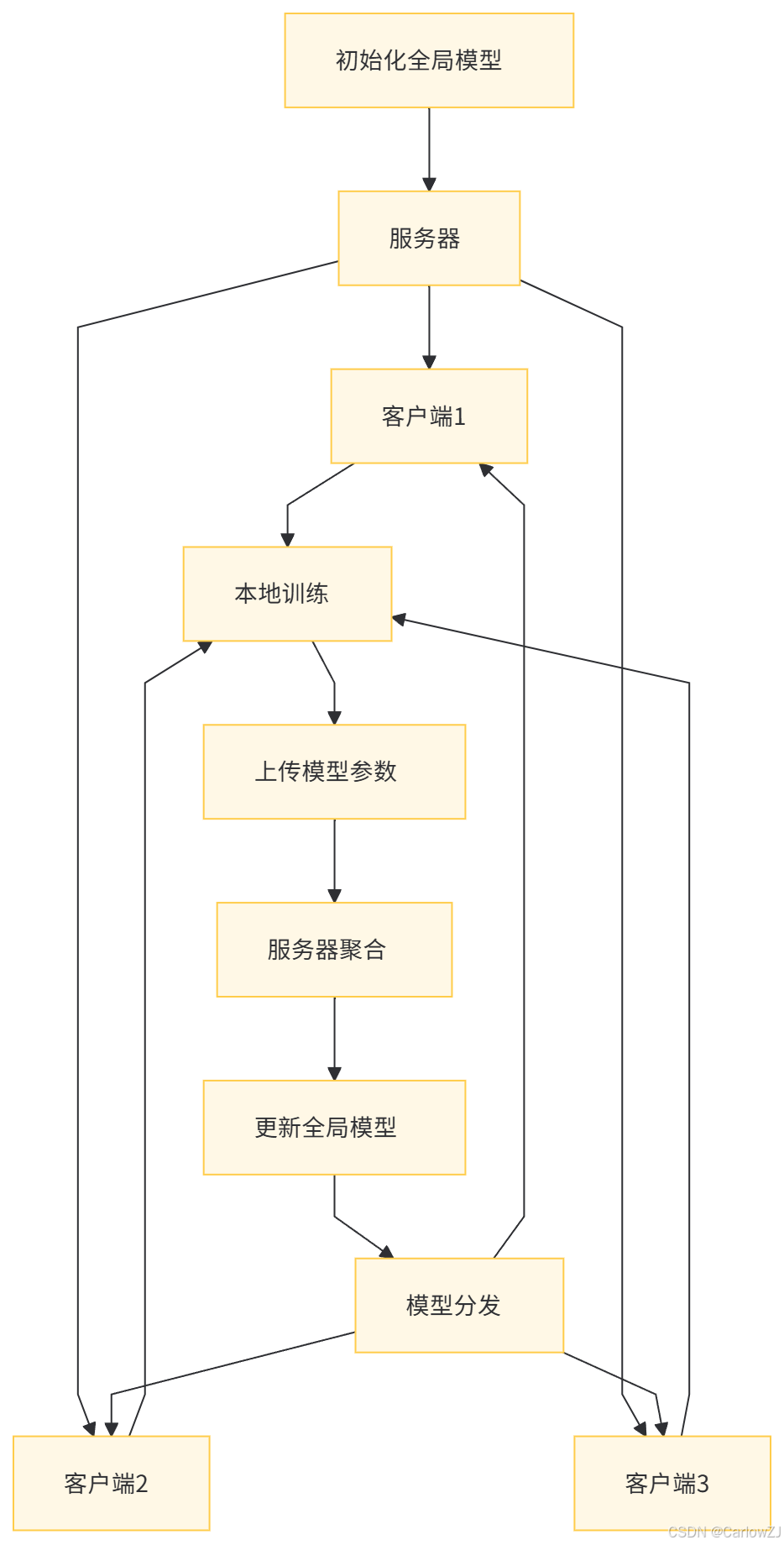
(二)流程说明
-
初始化全局模型:服务器初始化一个全局模型并分发给所有客户端。
-
本地训练:每个客户端在本地数据上训练模型,并生成本地模型参数。
-
上传模型参数:客户端将本地模型参数上传至服务器。
-
服务器聚合:服务器聚合所有客户端的模型参数,更新全局模型。
-
模型分发:更新后的全局模型再次分发给客户端,重复上述过程,直至模型收敛。
四、联邦学习代码示例
(一)环境准备
import tensorflow as tf
import tensorflow_federated as tff
(二)模拟数据生成
# 生成模拟数据
def create_data():
client_data = []
for i in range(3): # 假设有3个客户端
x = tf.random.normal([100, 2]) # 每个客户端有100个样本
y = tf.random.uniform([100], minval=0, maxval=2, dtype=tf.int32)
client_data.append((x, y))
return client_data
client_data = create_data()
(三)模型定义
def create_keras_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='relu', input_shape=(2,)),
tf.keras.layers.Dense(2, activation='softmax')
])
return model
def model_fn():
keras_model = create_keras_model()
return tff.learning.models.from_keras_model(
keras_model,
input_spec=client_data[0],
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]
)
(四)联邦学习训练
# 联邦学习算法
fed_avg = tff.learning.algorithms.build_unweighted_fed_avg(
model_fn=model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.02),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=1.0)
)
# 模拟联邦学习训练过程
state = fed_avg.initialize()
for round_num in range(10):
state, metrics = fed_avg.next(state, client_data)
print(f'Round {round_num}: {metrics}')
五、联邦学习应用场景
(一)医疗领域
在医疗数据中,患者隐私至关重要。联邦学习可以用于多医院之间的医学图像分析、疾病预测等任务,无需共享患者数据,从而保护患者隐私。
(二)金融领域
金融机构可以利用联邦学习整合不同地区的客户数据,进行风险评估和欺诈检测,同时避免数据泄露风险。
(三)物联网
在物联网设备中,数据分散在各个设备上。联邦学习可以在设备端进行模型训练,减少数据传输开销,同时提高模型的实时性和隐私性。
六、联邦学习注意事项
(一)数据异构性
不同客户端的数据分布可能存在差异,这可能导致模型训练的不均衡。需要通过数据预处理或算法优化来缓解这一问题。
(二)通信开销
联邦学习需要频繁的客户端与服务器之间的通信,可能会导致较高的通信开销。可以通过压缩模型参数或优化通信协议来降低开销。
(三)安全与隐私
虽然联邦学习在一定程度上保护了数据隐私,但仍需考虑模型参数泄露等潜在风险。可以引入加密技术(如同态加密)进一步增强安全性。
七、总结
联邦学习作为一种创新的分布式机器学习技术,为数据隐私保护和模型优化提供了新的解决方案。通过本文的介绍,读者可以对联邦学习的基本概念、架构、实现方法以及应用场景有更深入的理解。希望本文能够为读者在联邦学习领域的学习和研究提供帮助。



















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











