



📑 摘要
本文主要介绍了如何在本地部署大模型(以 Ollama 为例),并将其应用于实际开发中。通过详细的步骤说明和实践示例,帮助中国开发者快速掌握本地大模型的部署与使用方法。文章涵盖了环境配置、代码实现、架构设计、流程优化等多个方面,并提供了丰富的图表和代码示例,旨在为 AI 应用开发者提供一个实用性强、可操作的参考指南。
思维导图:本地大模型部署知识体系
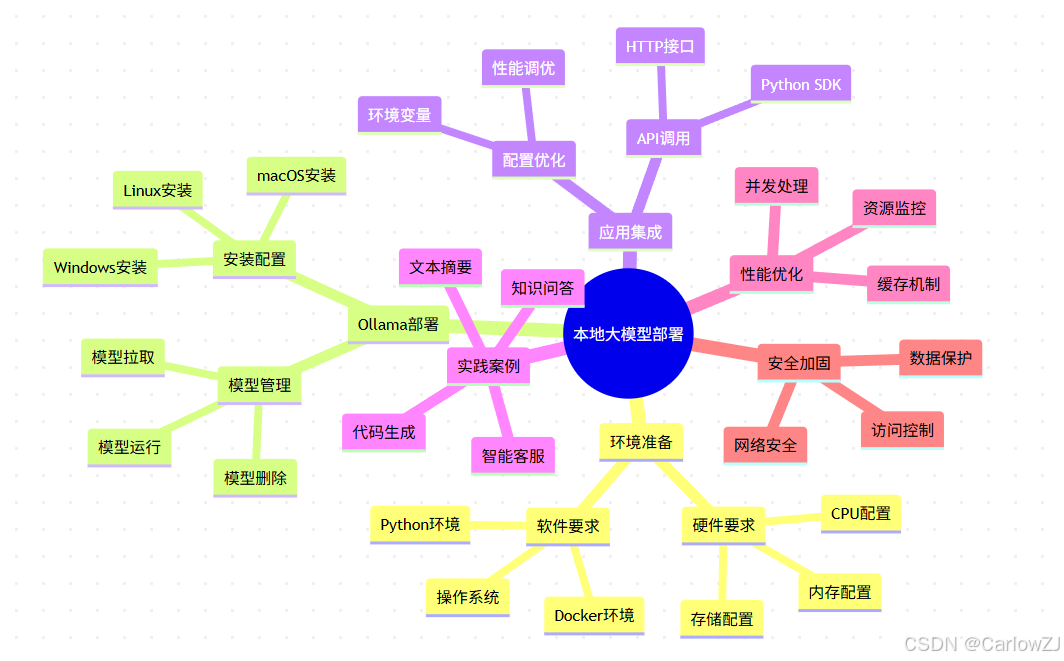
mindmap
root((本地大模型部署))
环境准备
硬件要求
CPU配置
内存配置
存储配置
软件要求
操作系统
Python环境
Docker环境
Ollama部署
安装配置
Linux安装
Windows安装
macOS安装
模型管理
模型拉取
模型运行
模型删除
应用集成
API调用
HTTP接口
Python SDK
配置优化
环境变量
性能调优
实践案例
智能客服
文本摘要
代码生成
知识问答
性能优化
缓存机制
并发处理
资源监控
安全加固
访问控制
网络安全
数据保护
第一章:引言 - 为什么选择本地大模型
随着人工智能技术的飞速发展,大语言模型(LLM)在自然语言处理(NLP)领域展现出强大的能力。然而,依赖云端 API 的方式存在成本高、网络延迟、数据隐私等问题。本地部署大模型成为一种高效且经济的解决方案。
1.1 本地部署的优势
- 数据隐私:敏感数据无需上传到第三方服务器
- 成本控制:一次性硬件投入,长期使用成本更低
- 低延迟:本地处理,响应速度更快
- 离线可用:不依赖网络连接,稳定性更高
1.2 Ollama 简介
Ollama 是一个开源的本地大模型运行平台,具有以下特点:
- 支持多种主流大模型(Llama、Mistral、Phi 等)
- 简单易用的命令行界面
- 跨平台支持(Linux、macOS、Windows)
- 容器化部署,便于管理
💡 AI 场景痛点:企业敏感数据无法上传云端,本地部署成为刚需。
第二章:环境准备 - 打好硬件和软件基础
在开始本地大模型的部署之前,需要确保开发环境已经准备就绪。
2.1 硬件要求
| 组件 | 最低配置 | 推荐配置 | 说明 |
|---|---|---|---|
| CPU | 4 核心 | 8 核心或以上 | 支持 AVX 指令集 |
| 内存 | 16GB | 32GB 或以上 | 运行大模型必需 |
| 存储 | 500GB SSD | 1TB SSD 或以上 | 模型存储和缓存 |
| GPU | 无 | NVIDIA 3090/4090 | 加速推理(可选) |
2.2 软件要求
- 操作系统:Linux(推荐 Ubuntu 20.04+)或 macOS(12.0+)
- Windows 用户:建议使用 WSL2 环境
- Python:3.8 或以上版本
- Docker:20.0 或以上版本(可选)
2.3 环境检查脚本
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
environment_checker.py
本地大模型环境检查工具
"""
import os
import sys
import platform
import subprocess
import psutil
from typing import Dict, List
class EnvironmentChecker:
"""
环境检查器
"""
def __init__(self):
"""
初始化环境检查器
"""
self.system_info = {}
def check_system_info(self) -> Dict:
"""
检查系统信息
Returns:
Dict: 系统信息
"""
print("🔍 正在检查系统信息...")
system_info = {
"os": platform.system(),
"os_version": platform.version(),
"architecture": platform.architecture()[0],
"machine": platform.machine(),
"processor": platform.processor(),
"python_version": platform.python_version()
}
print("🖥️ 系统信息:")
for key, value in system_info.items():
print(f" {key}: {value}")
self.system_info = system_info
return system_info
def check_hardware_resources(self) -> Dict:
"""
检查硬件资源
Returns:
Dict: 硬件资源信息
"""
print("\n🔍 正在检查硬件资源...")
# CPU 信息
cpu_count = os.cpu_count()
cpu_percent = psutil.cpu_percent(interval=1)
# 内存信息
memory = psutil.virtual_memory()
memory_total_gb = memory.total / (1024**3)
memory_available_gb = memory.available / (1024**3)
memory_percent = memory.percent
# 磁盘信息
disk = psutil.disk_usage('/')
disk_total_gb = disk.total / (1024**3)
disk_free_gb = disk.free / (1024**3)
disk_percent = (disk.used / disk.total) * 100
hardware_info = {
"cpu_count": cpu_count,
"cpu_percent": cpu_percent,
"memory_total_gb": round(memory_total_gb, 2),
"memory_available_gb": round(memory_available_gb, 2),
"memory_percent": memory_percent,
"disk_total_gb": round(disk_total_gb, 2),
"disk_free_gb": round(disk_free_gb, 2),
"disk_percent": round(disk_percent, 2)
}
print("📊 硬件资源:")
print(f" CPU 核心数: {cpu_count}")
print(f" CPU 使用率: {cpu_percent:.1f}%")
print(f" 内存总量: {memory_total_gb:.1f} GB")
print(f" 可用内存: {memory_available_gb:.1f} GB")
print(f" 内存使用率: {memory_percent:.1f}%")
print(f" 磁盘总量: {disk_total_gb:.1f} GB")
print(f" 可用磁盘: {disk_free_gb:.1f} GB")
print(f" 磁盘使用率: {disk_percent:.1f}%")
return hardware_info
def check_software_dependencies(self) -> Dict:
"""
检查软件依赖
Returns:
Dict: 软件依赖信息
"""
print("\n🔍 正在检查软件依赖...")
dependencies = {
"curl": False,
"docker": False,
"python": False,
"pip": False
}
# 检查 curl
try:
subprocess.run(["curl", "--version"],
capture_output=True,
check=True)
dependencies["curl"] = True
print("✅ curl: 已安装")
except (subprocess.CalledProcessError, FileNotFoundError):
print("❌ curl: 未安装")
# 检查 Docker
try:
result = subprocess.run(["docker", "--version"],
capture_output=True,
text=True,
check=True)
dependencies["docker"] = True
print(f"✅ Docker: {result.stdout.strip()}")
except (subprocess.CalledProcessError, FileNotFoundError):
print("❌ Docker: 未安装")
# 检查 Python
try:
result = subprocess.run(["python3", "--version"],
capture_output=True,
text=True,
check=True)
dependencies["python"] = True
print(f"✅ Python: {result.stdout.strip()}")
except (subprocess.CalledProcessError, FileNotFoundError):
try:
result = subprocess.run(["python", "--version"],
capture_output=True,
text=True,
check=True)
dependencies["python"] = True
print(f"✅ Python: {result.stdout.strip()}")
except (subprocess.CalledProcessError, FileNotFoundError):
print("❌ Python: 未安装")
# 检查 pip
try:
result = subprocess.run(["pip3", "--version"],
capture_output=True,
text=True,
check=True)
dependencies["pip"] = True
print(f"✅ pip: {result.stdout.strip()}")
except (subprocess.CalledProcessError, FileNotFoundError):
try:
result = subprocess.run(["pip", "--version"],
capture_output=True,
text=True,
check=True)
dependencies["pip"] = True
print(f"✅ pip: {result.stdout.strip()}")
except (subprocess.CalledProcessError, FileNotFoundError):
print("❌ pip: 未安装")
return dependencies
def assess_deployment_feasibility(self,
hardware_info: Dict,
dependencies: Dict) -> Dict:
"""
评估部署可行性
Args:
hardware_info (Dict): 硬件信息
dependencies (Dict): 依赖信息
Returns:
Dict: 评估结果
"""
print("\n🔍 正在评估部署可行性...")
assessment = {
"cpu_sufficient": hardware_info["cpu_count"] >= 4,
"memory_sufficient": hardware_info["memory_total_gb"] >= 16,
"disk_sufficient": hardware_info["disk_free_gb"] >= 50,
"dependencies_met": all(dependencies.values()),
"recommendations": []
}
# CPU 评估
if assessment["cpu_sufficient"]:
print("✅ CPU 配置满足要求")
else:
print("❌ CPU 配置不足(建议至少 4 核心)")
assessment["recommendations"].append("升级 CPU 至少 4 核心")
# 内存评估
if assessment["memory_sufficient"]:
print("✅ 内存配置满足要求")
else:
print("❌ 内存配置不足(建议至少 16GB)")
assessment["recommendations"].append("升级内存至至少 16GB")
# 磁盘评估
if assessment["disk_sufficient"]:
print("✅ 磁盘空间满足要求")
else:
print("❌ 磁盘空间不足(建议至少 50GB 可用空间)")
assessment["recommendations"].append("清理磁盘空间或增加存储")
# 依赖评估
if assessment["dependencies_met"]:
print("✅ 软件依赖满足要求")
else:
print("❌ 软件依赖不满足要求")
missing_deps = [k for k, v in dependencies.items() if not v]
assessment["recommendations"].append(f"安装缺失的依赖: {', '.join(missing_deps)}")
# 总体评估
if all([assessment["cpu_sufficient"],
assessment["memory_sufficient"],
assessment["disk_sufficient"],
assessment["dependencies_met"]]):
print("\n🎉 环境检查通过,可以开始部署 Ollama!")
else:
print("\n⚠️ 环境检查未完全通过,请根据建议进行调整")
return assessment
def run_full_check(self):
"""
运行完整环境检查
"""
print("🚀 开始本地大模型环境检查")
print("=" * 50)
# 检查系统信息
system_info = self.check_system_info()
# 检查硬件资源
hardware_info = self.check_hardware_resources()
# 检查软件依赖
dependencies = self.check_software_dependencies()
# 评估部署可行性
assessment = self.assess_deployment_feasibility(hardware_info, dependencies)
# 输出建议
if assessment["recommendations"]:
print("\n💡 优化建议:")
for i, recommendation in enumerate(assessment["recommendations"], 1):
print(f" {i}. {recommendation}")
return {
"system_info": system_info,
"hardware_info": hardware_info,
"dependencies": dependencies,
"assessment": assessment
}
def main():
"""
主函数
"""
checker = EnvironmentChecker()
checker.run_full_check()
if __name__ == "__main__":
# 注意:运行前请确保已安装 psutil 库
# pip install psutil
# main()
print("环境检查工具准备就绪")
2.4 安装依赖
在开始之前,确保已安装以下工具:
# Ubuntu/Debian 系统
sudo apt update
sudo apt install -y python3 python3-pip curl docker.io
# CentOS/RHEL 系统
sudo yum update
sudo yum install -y python3 python3-pip curl docker
# macOS 系统 (需要先安装 Homebrew)
brew install python3 curl docker
第三章:Ollama 本地部署 - 一步步安装配置
Ollama 是一个开源的本地大模型运行平台,支持多种模型,如 Llama2、Mistral 等。
3.1 安装 Ollama
Linux 系统安装
# 下载并安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 验证安装
ollama --version
Windows 系统安装
# 使用 PowerShell 下载安装包
Invoke-WebRequest -Uri "https://ollama.com/download/OllamaSetup.exe" -OutFile "OllamaSetup.exe"
# 运行安装程序
Start-Process -FilePath ".\OllamaSetup.exe" -Wait
macOS 系统安装
# 使用 Homebrew 安装
brew install ollama
# 或者直接下载安装包
curl -fsSL https://ollama.com/install.sh | sh
3.2 启动 Ollama 服务
# 启动 Ollama 服务
ollama serve
# 或者以后台服务方式启动
sudo systemctl start ollama
sudo systemctl enable ollama # 设置开机自启
3.3 模型管理工具
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
ollama_model_manager.py
Ollama 模型管理工具
"""
import subprocess
import json
import time
from typing import List, Dict, Optional
class OllamaModelManager:
"""
Ollama 模型管理器
"""
def __init__(self):
"""
初始化模型管理器
"""
self.ollama_available = self.check_ollama_availability()
def check_ollama_availability(self) -> bool:
"""
检查 Ollama 是否可用
Returns:
bool: 是否可用
"""
try:
result = subprocess.run(
["ollama", "--version"],
capture_output=True,
text=True,
check=True
)
print(f"✅ Ollama 可用: {result.stdout.strip()}")
return True
except (subprocess.CalledProcessError, FileNotFoundError):
print("❌ Ollama 不可用,请先安装 Ollama")
return False
def list_models(self) -> List[Dict]:
"""
列出已安装的模型
Returns:
List[Dict]: 模型列表
"""
if not self.ollama_available:
return []
try:
print("🔍 正在获取已安装模型列表...")
result = subprocess.run(
["ollama", "list"],
capture_output=True,
text=True,
check=True
)
# 解析输出
lines = result.stdout.strip().split('\n')
if len(lines) <= 1:
print("💡 暂无已安装模型")
return []
models = []
# 跳过标题行
for line in lines[1:]:
parts = line.split()
if len(parts) >= 3:
model_info = {
"name": parts[0],
"size": parts[1],
"modified": parts[2] if len(parts) > 2 else "N/A"
}
models.append(model_info)
print(f"📊 已安装 {len(models)} 个模型:")
for model in models:
print(f" - {model['name']} ({model['size']})")
return models
except subprocess.CalledProcessError as e:
print(f"❌ 获取模型列表失败: {e}")
return []
except Exception as e:
print(f"❌ 解析模型列表时出错: {e}")
return []
def pull_model(self, model_name: str, timeout: int = 300) -> bool:
"""
拉取模型
Args:
model_name (str): 模型名称
timeout (int): 超时时间(秒)
Returns:
bool: 是否成功
"""
if not self.ollama_available:
return False
print(f"📥 正在拉取模型: {model_name}")
try:
start_time = time.time()
process = subprocess.Popen(
["ollama", "pull", model_name],
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
text=True
)
# 实时输出进度
while True:
output = process.stdout.readline()
if output == '' and process.poll() is not None:
break
if output:
print(f" {output.strip()}")
# 检查超时
if time.time() - start_time > timeout:
process.terminate()
print(f"⏰ 拉取模型超时 ({timeout} 秒)")
return False
rc = process.poll()
if rc == 0:
print(f"✅ 模型 {model_name} 拉取成功")
return True
else:
print(f"❌ 模型 {model_name} 拉取失败")
return False
except Exception as e:
print(f"❌ 拉取模型时出错: {e}")
return False
def remove_model(self, model_name: str) -> bool:
"""
删除模型
Args:
model_name (str): 模型名称
Returns:
bool: 是否成功
"""
if not self.ollama_available:
return False
print(f"🗑️ 正在删除模型: {model_name}")
try:
result = subprocess.run(
["ollama", "rm", model_name],
capture_output=True,
text=True,
check=True
)
print(f"✅ 模型 {model_name} 删除成功")
return True
except subprocess.CalledProcessError as e:
print(f"❌ 删除模型失败: {e.stderr}")
return False
except Exception as e:
print(f"❌ 删除模型时出错: {e}")
return False
def run_model_test(self, model_name: str, prompt: str = "Hello, world!") -> Dict:
"""
运行模型测试
Args:
model_name (str): 模型名称
prompt (str): 测试提示词
Returns:
Dict: 测试结果
"""
if not self.ollama_available:
return {}
print(f"🧪 正在测试模型: {model_name}")
print(f" 提示词: {prompt}")
try:
start_time = time.time()
result = subprocess.run(
["ollama", "run", model_name, prompt],
capture_output=True,
text=True,
timeout=120 # 2分钟超时
)
end_time = time.time()
if result.returncode == 0:
response = result.stdout.strip()
print(f"✅ 模型测试成功")
print(f" 响应: {response}")
print(f" 耗时: {end_time - start_time:.2f} 秒")
return {
"success": True,
"response": response,
"duration": end_time - start_time
}
else:
print(f"❌ 模型测试失败: {result.stderr}")
return {
"success": False,
"error": result.stderr
}
except subprocess.TimeoutExpired:
print("⏰ 模型测试超时")
return {
"success": False,
"error": "timeout"
}
except Exception as e:
print(f"❌ 模型测试时出错: {e}")
return {
"success": False,
"error": str(e)
}
def get_model_info(self, model_name: str) -> Dict:
"""
获取模型详细信息
Args:
model_name (str): 模型名称
Returns:
Dict: 模型信息
"""
if not self.ollama_available:
return {}
print(f"🔍 正在获取模型信息: {model_name}")
try:
result = subprocess.run(
["ollama", "show", model_name],
capture_output=True,
text=True,
check=True
)
# 简单解析输出
output_lines = result.stdout.strip().split('\n')
model_info = {
"name": model_name,
"details": output_lines
}
print(f"✅ 获取模型信息成功")
for line in output_lines[:10]: # 只显示前10行
print(f" {line}")
if len(output_lines) > 10:
print(f" ... (还有 {len(output_lines) - 10} 行)")
return model_info
except subprocess.CalledProcessError as e:
print(f"❌ 获取模型信息失败: {e.stderr}")
return {}
except Exception as e:
print(f"❌ 获取模型信息时出错: {e}")
return {}
def recommend_models(self) -> List[Dict]:
"""
推荐常用模型
Returns:
List[Dict]: 推荐模型列表
"""
recommendations = [
{
"name": "llama2",
"description": "Meta 开发的通用大语言模型",
"size": "3.8GB - 7GB",
"use_case": "通用对话、文本生成"
},
{
"name": "mistral",
"description": "Mistral AI 开发的高效模型",
"size": "4.1GB",
"use_case": "对话、代码生成"
},
{
"name": "phi",
"description": "Microsoft 开发的小型高效模型",
"size": "1.6GB - 3.8GB",
"use_case": "轻量级应用、代码生成"
},
{
"name": "codellama",
"description": "专门针对代码的 Llama 模型",
"size": "3.8GB - 7GB",
"use_case": "代码生成、代码理解"
}
]
print("🌟 推荐模型:")
for i, model in enumerate(recommendations, 1):
print(f" {i}. {model['name']}")
print(f" 描述: {model['description']}")
print(f" 大小: {model['size']}")
print(f" 用途: {model['use_case']}")
print()
return recommendations
def main():
"""
主函数
"""
manager = OllamaModelManager()
# 列出已安装模型
manager.list_models()
# 推荐模型
manager.recommend_models()
# 示例:拉取并测试模型(取消注释以运行)
# manager.pull_model("llama2")
# manager.run_model_test("llama2", "你好,世界!")
if __name__ == "__main__":
# 注意:运行前请确保已安装 Ollama
# main()
print("Ollama 模型管理工具准备就绪")
3.4 拉取常用模型
# 拉取 Llama2 模型(通用场景)
ollama pull llama2
# 拉取 Mistral 模型(对话场景)
ollama pull mistral
# 拉取 Phi 模型(轻量级场景)
oll拉取 Phi 模型(轻量级场景)
ollama pull phi
# 拉取 CodeLlama 模型(代码生成场景)
ollama pull codellama
3.5 测试模型
# 测试 Llama2 模型
ollama run llama2 "你好,世界!"
# 测试 Mistral 模型
ollama run mistral "介绍一下人工智能的发展历史"
第四章:配置本地大模型 - 集成到应用中
在本地部署完成后,需要对应用进行配置,使其能够使用本地大模型。
4.1 修改配置文件
假设你的应用使用 .env 文件进行配置,可以按照以下步骤修改:
# 默认 LLM 配置
DEFAULT_LLM=ollama
OLLAMA_ENDPOINT=http://localhost:11434
OLLAMA_MODEL=llama2
# 模型参数配置
OLLAMA_TEMPERATURE=0.7
OLLAMA_MAX_TOKENS=2048
OLLAMA_TIMEOUT=300
4.2 Python 集成工具
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
ollama_client.py
Ollama 客户端工具
"""
import requests
import json
import time
from typing import Dict, List, Optional, Union
class OllamaClient:
"""
Ollama 客户端
"""
def __init__(self,
base_url: str = "http://localhost:11434",
default_model: str = "llama2",
timeout: int = 300):
"""
初始化 Ollama 客户端
Args:
base_url (str): Ollama 服务地址
default_model (str): 默认模型
timeout (int): 请求超时时间(秒)
"""
self.base_url = base_url.rstrip('/')
self.default_model = default_model
self.timeout = timeout
self.session = requests.Session()
def check_service_health(self) -> bool:
"""
检查 Ollama 服务健康状态
Returns:
bool: 服务是否健康
"""
try:
response = self.session.get(
f"{self.base_url}/api/tags",
timeout=self.timeout
)
response.raise_for_status()
print("✅ Ollama 服务运行正常")
return True
except requests.exceptions.RequestException as e:
print(f"❌ Ollama 服务不可用: {e}")
return False
def list_models(self) -> List[Dict]:
"""
列出可用模型
Returns:
List[Dict]: 模型列表
"""
try:
response = self.session.get(
f"{self.base_url}/api/tags",
timeout=self.timeout
)
response.raise_for_status()
data = response.json()
models = data.get("models", [])
print(f"📊 可用模型 ({len(models)} 个):")
for model in models:
print(f" - {model['name']}")
return models
except requests.exceptions.RequestException as e:
print(f"❌ 获取模型列表失败: {e}")
return []
except json.JSONDecodeError as e:
print(f"❌ 解析响应失败: {e}")
return []
def generate_text(self,
prompt: str,
model: Optional[str] = None,
options: Optional[Dict] = None) -> Dict:
"""
生成文本
Args:
prompt (str): 提示词
model (str): 模型名称
options (Dict): 生成选项
Returns:
Dict: 生成结果
"""
if not model:
model = self.default_model
# 构造请求数据
data = {
"model": model,
"prompt": prompt,
"stream": False
}
if options:
data["options"] = options
print(f"🤖 正在使用 {model} 模型生成文本...")
print(f" 提示词: {prompt}")
try:
start_time = time.time()
response = self.session.post(
f"{self.base_url}/api/generate",
json=data,
timeout=self.timeout
)
end_time = time.time()
response.raise_for_status()
result = response.json()
generated_text = result.get("response", "")
print(f"✅ 文本生成成功")
print(f" 生成文本: {generated_text[:100]}...")
print(f" 耗时: {end_time - start_time:.2f} 秒")
return {
"success": True,
"text": generated_text,
"model": model,
"duration": end_time - start_time,
"prompt": prompt
}
except requests.exceptions.Timeout:
print("⏰ 文本生成超时")
return {
"success": False,
"error": "timeout"
}
except requests.exceptions.RequestException as e:
print(f"❌ 文本生成失败: {e}")
return {
"success": False,
"error": str(e)
}
except json.JSONDecodeError as e:
print(f"❌ 解析响应失败: {e}")
return {
"success": False,
"error": str(e)
}
def chat(self,
messages: List[Dict],
model: Optional[str] = None,
options: Optional[Dict] = None) -> Dict:
"""
对话模式
Args:
messages (List[Dict]): 消息列表
model (str): 模型名称
options (Dict): 生成选项
Returns:
Dict: 对话结果
"""
if not model:
model = self.default_model
# 构造请求数据
data = {
"model": model,
"messages": messages
}
if options:
data["options"] = options
print(f"💬 正在使用 {model} 模型进行对话...")
try:
start_time = time.time()
response = self.session.post(
f"{self.base_url}/api/chat",
json=data,
timeout=self.timeout
)
end_time = time.time()
response.raise_for_status()
result = response.json()
message = result.get("message", {})
content = message.get("content", "")
print(f"✅ 对话成功")
print(f" 回复: {content}")
print(f" 耗时: {end_time - start_time:.2f} 秒")
return {
"success": True,
"content": content,
"model": model,
"duration": end_time - start_time,
"messages": messages
}
except requests.exceptions.Timeout:
print("⏰ 对话超时")
return {
"success": False,
"error": "timeout"
}
except requests.exceptions.RequestException as e:
print(f"❌ 对话失败: {e}")
return {
"success": False,
"error": str(e)
}
except json.JSONDecodeError as e:
print(f"❌ 解析响应失败: {e}")
return {
"success": False,
"error": str(e)
}
def embed(self,
input_text: str,
model: Optional[str] = None) -> Dict:
"""
生成文本嵌入向量
Args:
input_text (str): 输入文本
model (str): 模型名称
Returns:
Dict: 嵌入结果
"""
if not model:
model = self.default_model
# 构造请求数据
data = {
"model": model,
"input": input_text
}
print(f"🔢 正在使用 {model} 模型生成嵌入向量...")
try:
start_time = time.time()
response = self.session.post(
f"{self.base_url}/api/embeddings",
json=data,
timeout=self.timeout
)
end_time = time.time()
response.raise_for_status()
result = response.json()
embedding = result.get("embedding", [])
print(f"✅ 嵌入向量生成成功")
print(f" 向量维度: {len(embedding)}")
print(f" 耗时: {end_time - start_time:.2f} 秒")
return {
"success": True,
"embedding": embedding,
"model": model,
"duration": end_time - start_time,
"input": input_text
}
except requests.exceptions.Timeout:
print("⏰ 嵌入向量生成超时")
return {
"success": False,
"error": "timeout"
}
except requests.exceptions.RequestException as e:
print(f"❌ 嵌入向量生成失败: {e}")
return {
"success": False,
"error": str(e)
}
except json.JSONDecodeError as e:
print(f"❌ 解析响应失败: {e}")
return {
"success": False,
"error": str(e)
}
def main():
"""
主函数 - 演示 Ollama 客户端功能
"""
# 初始化客户端
client = OllamaClient()
# 检查服务健康状态
if not client.check_service_health():
return
# 列出可用模型
client.list_models()
# 示例1: 文本生成
print("\n" + "="*50)
print("示例1: 文本生成")
print("="*50)
result1 = client.generate_text(
prompt="写一首关于春天的诗",
options={"temperature": 0.7}
)
# 示例2: 对话模式
print("\n" + "="*50)
print("示例2: 对话模式")
print("="*50)
messages = [
{"role": "user", "content": "你好,介绍一下你自己"}
]
result2 = client.chat(messages)
# 示例3: 嵌入向量生成
print("\n" + "="*50)
print("示例3: 嵌入向量生成")
print("="*50)
result3 = client.embed("人工智能是未来的趋势")
if __name__ == "__main__":
# 注意:运行前请确保 Ollama 服务已启动
# main()
print("Ollama 客户端工具准备就绪")
4.3 配置优化
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
ollama_configurator.py
Ollama 配置优化工具
"""
import os
import json
from typing import Dict, Optional
class OllamaConfigurator:
"""
Ollama 配置器
"""
def __init__(self, config_file: str = ".env"):
"""
初始化配置器
Args:
config_file (str): 配置文件路径
"""
self.config_file = config_file
self.config = {}
self.load_config()
def load_config(self):
"""
加载配置文件
"""
try:
if os.path.exists(self.config_file):
with open(self.config_file, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if line and not line.startswith('#') and '=' in line:
key, value = line.split('=', 1)
self.config[key.strip()] = value.strip().strip('"\'')
print(f"✅ 配置文件加载成功: {self.config_file}")
else:
print(f"💡 配置文件不存在,将创建新配置: {self.config_file}")
except Exception as e:
print(f"❌ 加载配置文件失败: {e}")
def save_config(self):
"""
保存配置文件
"""
try:
with open(self.config_file, 'w', encoding='utf-8') as f:
for key, value in self.config.items():
f.write(f"{key}={value}\n")
print(f"✅ 配置文件保存成功: {self.config_file}")
except Exception as e:
print(f"❌ 保存配置文件失败: {e}")
def configure_ollama(self,
endpoint: str = "http://localhost:11434",
default_model: str = "llama2",
temperature: float = 0.7,
max_tokens: int = 2048,
timeout: int = 300):
"""
配置 Ollama 参数
Args:
endpoint (str): Ollama 服务地址
default_model (str): 默认模型
temperature (float): 温度参数
max_tokens (int): 最大令牌数
timeout (int): 超时时间
"""
print("🔧 正在配置 Ollama 参数...")
self.config.update({
"OLLAMA_ENDPOINT": endpoint,
"OLLAMA_DEFAULT_MODEL": default_model,
"OLLAMA_TEMPERATURE": str(temperature),
"OLLAMA_MAX_TOKENS": str(max_tokens),
"OLLAMA_TIMEOUT": str(timeout)
})
print("✅ Ollama 配置参数:")
print(f" 服务地址: {endpoint}")
print(f" 默认模型: {default_model}")
print(f" 温度参数: {temperature}")
print(f" 最大令牌: {max_tokens}")
print(f" 超时时间: {timeout} 秒")
self.save_config()
def configure_model_parameters(self,
model_name: str,
parameters: Dict):
"""
配置特定模型参数
Args:
model_name (str): 模型名称
parameters (Dict): 参数字典
"""
print(f"🔧 正在配置 {model_name} 模型参数...")
# 将参数保存为 JSON 字符串
param_key = f"OLLAMA_MODEL_{model_name.upper()}_PARAMS"
self.config[param_key] = json.dumps(parameters, ensure_ascii=False)
print(f"✅ {model_name} 模型参数已配置")
for key, value in parameters.items():
print(f" {key}: {value}")
def get_config(self) -> Dict:
"""
获取当前配置
Returns:
Dict: 当前配置
"""
return self.config.copy()
def validate_config(self) -> Dict[str, bool]:
"""
验证配置
Returns:
Dict[str, bool]: 验证结果
"""
print("🔍 正在验证配置...")
validations = {
"endpoint_format": self.config.get("OLLAMA_ENDPOINT", "").startswith(("http://", "https://")),
"default_model_set": bool(self.config.get("OLLAMA_DEFAULT_MODEL")),
"temperature_valid": 0 <= float(self.config.get("OLLAMA_TEMPERATURE", 0.7)) <= 1,
"max_tokens_valid": int(self.config.get("OLLAMA_MAX_TOKENS", 2048)) > 0,
"timeout_valid": int(self.config.get("OLLAMA_TIMEOUT", 300)) > 0
}
print("✅ 配置验证结果:")
for key, value in validations.items():
status = "✅" if value else "❌"
print(f" {status} {key}: {value}")
return validations
def main():
"""
主函数
"""
configurator = OllamaConfigurator()
# 配置 Ollama 基本参数
configurator.configure_ollama(
endpoint="http://localhost:11434",
default_model="llama2",
temperature=0.7,
max_tokens=2048,
timeout=300
)
# 配置特定模型参数
configurator.configure_model_parameters(
"llama2",
{
"temperature": 0.7,
"top_p": 0.9,
"repeat_penalty": 1.2
}
)
# 验证配置
configurator.validate_config()
if __name__ == "__main__":
# main()
print("Ollama 配置工具准备就绪")
第五章:实践案例 - 智能客服系统
5.1 场景介绍
假设我们正在开发一个智能客服系统,需要使用大模型来处理用户的问题。
5.2 智能客服系统实现
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
smart_customer_service.py
智能客服系统
"""
import json
import time
import hashlib
from typing import Dict, List, Optional
from ollama_client import OllamaClient # 假设已实现的 Ollama 客户端
class SmartCustomerService:
"""
智能客服系统
"""
def __init__(self,
ollama_client: OllamaClient,
faq_file: str = "faq.json"):
"""
初始化智能客服系统
Args:
ollama_client (OllamaClient): Ollama 客户端
faq_file (str): FAQ 文件路径
"""
self.ollama_client = ollama_client
self.faq_file = faq_file
self.faq_data = {}
self.conversation_history = {}
self.load_faq_data()
def load_faq_data(self):
"""
加载 FAQ 数据
"""
try:
with open(self.faq_file, 'r', encoding='utf-8') as f:
self.faq_data = json.load(f)
print(f"✅ FAQ 数据加载成功,共 {len(self.faq_data)} 条")
except FileNotFoundError:
print("💡 FAQ 文件不存在,将创建空数据")
self.faq_data = {}
except json.JSONDecodeError as e:
print(f"❌ FAQ 数据格式错误: {e}")
self.faq_data = {}
except Exception as e:
print(f"❌ 加载 FAQ 数据失败: {e}")
self.faq_data = {}
def save_faq_data(self):
"""
保存 FAQ 数据
"""
try:
with open(self.faq_file, 'w', encoding='utf-8') as f:
json.dump(self.faq_data, f, ensure_ascii=False, indent=2)
print("✅ FAQ 数据保存成功")
except Exception as e:
print(f"❌ 保存 FAQ 数据失败: {e}")
def add_faq(self, question: str, answer: str, category: str = "general"):
"""
添加 FAQ
Args:
question (str): 问题
answer (str): 答案
category (str): 分类
"""
# 生成问题的哈希值作为唯一标识
question_hash = hashlib.md5(question.encode()).hexdigest()[:8]
self.faq_data[question_hash] = {
"question": question,
"answer": answer,
"category": category,
"created_at": time.time()
}
print(f"✅ FAQ 已添加: {question_hash}")
self.save_faq_data()
def search_faq(self, query: str, threshold: float = 0.5) -> List[Dict]:
"""
搜索相似的 FAQ
Args:
query (str): 查询语句
threshold (float): 相似度阈值
Returns:
List[Dict]: 匹配的 FAQ 列表
"""
matches = []
# 简单的关键词匹配(实际应用中可以使用更复杂的算法)
query_keywords = set(query.lower().split())
for faq_id, faq in self.faq_data.items():
faq_keywords = set(faq["question"].lower().split())
# 计算相似度(简单的 Jaccard 相似度)
intersection = len(query_keywords.intersection(faq_keywords))
union = len(query_keywords.union(faq_keywords))
similarity = intersection / union if union > 0 else 0
if similarity >= threshold:
matches.append({
"id": faq_id,
"question": faq["question"],
"answer": faq["answer"],
"similarity": similarity
})
# 按相似度排序
matches.sort(key=lambda x: x["similarity"], reverse=True)
return matches
def generate_response_with_faq(self, user_id: str, question: str) -> Dict:
"""
基于 FAQ 生成回复
Args:
user_id (str): 用户 ID
question (str): 用户问题
Returns:
Dict: 回复结果
"""
print(f"👤 用户 {user_id}: {question}")
# 首先搜索 FAQ
faq_matches = self.search_faq(question)
if faq_matches:
# 找到匹配的 FAQ,直接返回答案
best_match = faq_matches[0]
print(f"💡 找到匹配的 FAQ (相似度: {best_match['similarity']:.2f})")
response = {
"type": "faq",
"content": best_match["answer"],
"source": "faq",
"confidence": best_match["similarity"],
"faq_id": best_match["id"]
}
else:
# 没有找到匹配的 FAQ,使用大模型生成回复
print("🤖 未找到匹配 FAQ,使用大模型生成回复")
# 构造对话历史
history = self.conversation_history.get(user_id, [])
messages = history + [{"role": "user", "content": question}]
# 调用大模型
result = self.ollama_client.chat(
messages=messages,
options={"temperature": 0.7}
)
if result["success"]:
response_content = result["content"]
response = {
"type": "generated",
"content": response_content,
"source": "llm",
"confidence": 0.8, # 大模型回复的默认置信度
"model": result["model"]
}
# 更新对话历史
messages.append({"role": "assistant", "content": response_content})
self.conversation_history[user_id] = messages[-10:] # 保留最近10轮对话
else:
response = {
"type": "error",
"content": "抱歉,暂时无法回答您的问题,请稍后再试。",
"source": "system",
"error": result.get("error", "unknown")
}
# 记录回复
print(f"🤖 客服回复: {response['content']}")
return response
def batch_process_questions(self, questions: List[Dict]) -> List[Dict]:
"""
批量处理问题
Args:
questions (List[Dict]): 问题列表,格式 [{"user_id": "123", "question": "问题"}]
Returns:
List[Dict]: 回复列表
"""
print(f"🔄 批量处理 {len(questions)} 个问题")
responses = []
for item in questions:
user_id = item["user_id"]
question = item["question"]
response = self.generate_response_with_faq(user_id, question)
response["user_id"] = user_id
response["question"] = question
responses.append(response)
return responses
def get_system_stats(self) -> Dict:
"""
获取系统统计信息
Returns:
Dict: 统计信息
"""
stats = {
"faq_count": len(self.faq_data),
"active_conversations": len(self.conversation_history),
"total_questions_answered": sum(len(history) for history in self.conversation_history.values())
}
print("📊 系统统计信息:")
print(f" FAQ 数量: {stats['faq_count']}")
print(f" 活跃对话: {stats['active_conversations']}")
print(f" 总回答数: {stats['total_questions_answered']}")
return stats
def create_sample_faq():
"""
创建示例 FAQ 数据
"""
sample_faq = {
"order_status": {
"question": "我的订单在哪里?",
"answer": "您可以通过以下方式查询订单状态:1. 登录官网个人中心查看订单详情;2. 在订单页面输入订单号查询;3. 联系客服提供订单号查询。",
"category": "order"
},
"refund_policy": {
"question": "如何申请退款?",
"answer": "退款申请流程:1. 登录账户进入订单详情页;2. 点击'申请退款'按钮;3. 填写退款原因并提交;4. 客服将在1-3个工作日内处理。",
"category": "refund"
},
"delivery_time": {
"question": "多久能收到货?",
"answer": "一般情况下,订单在支付成功后1-3个工作日内发货,发货后1-5个工作日送达(具体时间视地区而定)。",
"category": "delivery"
}
}
with open("faq.json", 'w', encoding='utf-8') as f:
json.dump(sample_faq, f, ensure_ascii=False, indent=2)
print("✅ 示例 FAQ 数据已创建")
def main():
"""
主函数 - 演示智能客服系统
"""
# 创建示例 FAQ 数据
create_sample_faq()
# 初始化 Ollama 客户端
ollama_client = OllamaClient()
# 检查服务健康状态
if not ollama_client.check_service_health():
return
# 初始化智能客服系统
客服 = SmartCustomerService(ollama_client)
# 添加更多 FAQ
客服.add_faq(
"如何修改收货地址?",
"您可以在订单未发货前修改收货地址:1. 登录账户进入订单详情;2. 点击'修改地址';3. 填写新地址并保存。",
"order"
)
# 测试问题回答
test_questions = [
{"user_id": "user_001", "question": "我的订单在哪里?"},
{"user_id": "user_002", "question": "你们的发货时间是多久?"},
{"user_id": "user_001", "question": "我想了解一下人工智能的发展历史"}
]
for item in test_questions:
客服.generate_response_with_faq(item["user_id"], item["question"])
print("-" * 50)
# 获取系统统计
客服.get_system_stats()
if __name__ == "__main__":
# 注意:运行前请确保:
# 1. Ollama 服务已启动
# 2. 已安装所需依赖
# 3. faq.json 文件存在或可创建
# main()
print("智能客服系统准备就绪")
5.3 数据准备
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
faq_data_preparer.py
FAQ 数据准备工具
"""
import json
import csv
from typing import List, Dict
class FAQDataPreparer:
"""
FAQ 数据准备工具
"""
def __init__(self, output_file: str = "faq.json"):
"""
初始化数据准备工具
Args:
output_file (str): 输出文件路径
"""
self.output_file = output_file
self.faq_data = {}
def load_from_csv(self, csv_file: str) -> bool:
"""
从 CSV 文件加载 FAQ 数据
Args:
csv_file (str): CSV 文件路径
Returns:
bool: 是否成功
"""
try:
with open(csv_file, 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
# 生成唯一 ID
faq_id = row.get('id') or f"faq_{len(self.faq_data) + 1}"
self.faq_data[faq_id] = {
"question": row['question'],
"answer": row['answer'],
"category": row.get('category', 'general')
}
print(f"✅ 从 CSV 文件加载 {len(self.faq_data)} 条 FAQ 数据")
return True
except Exception as e:
print(f"❌ 从 CSV 文件加载数据失败: {e}")
return False
def load_from_json(self, json_file: str) -> bool:
"""
从 JSON 文件加载 FAQ 数据
Args:
json_file (str): JSON 文件路径
Returns:
bool: 是否成功
"""
try:
with open(json_file, 'r', encoding='utf-8') as f:
data = json.load(f)
self.faq_data.update(data)
print(f"✅ 从 JSON 文件加载 {len(data)} 条 FAQ 数据")
return True
except Exception as e:
print(f"❌ 从 JSON 文件加载数据失败: {e}")
return False
def add_faq_item(self, question: str, answer: str, category: str = "general"):
"""
添加单个 FAQ 项目
Args:
question (str): 问题
answer (str): 答案
category (str): 分类
"""
faq_id = f"faq_{len(self.faq_data) + 1}"
self.faq_data[faq_id] = {
"question": question,
"answer": answer,
"category": category
}
def validate_data(self) -> Dict[str, int]:
"""
验证数据完整性
Returns:
Dict[str, int]: 验证结果
"""
issues = {
"missing_questions": 0,
"missing_answers": 0,
"empty_questions": 0,
"empty_answers": 0
}
for faq_id, faq in self.faq_data.items():
if "question" not in faq:
issues["missing_questions"] += 1
elif not faq["question"].strip():
issues["empty_questions"] += 1
if "answer" not in faq:
issues["missing_answers"] += 1
elif not faq["answer"].strip():
issues["empty_answers"] += 1
print("🔍 数据验证结果:")
for issue, count in issues.items():
status = "✅" if count == 0 else "⚠️"
print(f" {status} {issue}: {count}")
return issues
def export_to_json(self) -> bool:
"""
导出为 JSON 文件
Returns:
bool: 是否成功
"""
try:
with open(self.output_file, 'w', encoding='utf-8') as f:
json.dump(self.faq_data, f, ensure_ascii=False, indent=2)
print(f"✅ FAQ 数据已导出到: {self.output_file}")
print(f" 总计 {len(self.faq_data)} 条数据")
return True
except Exception as e:
print(f"❌ 导出数据失败: {e}")
return False
def export_to_csv(self, csv_file: str) -> bool:
"""
导出为 CSV 文件
Args:
csv_file (str): CSV 文件路径
Returns:
bool: 是否成功
"""
try:
with open(csv_file, 'w', encoding='utf-8', newline='') as f:
fieldnames = ['id', 'question', 'answer', 'category']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for faq_id, faq in self.faq_data.items():
writer.writerow({
'id': faq_id,
'question': faq['question'],
'answer': faq['answer'],
'category': faq.get('category', 'general')
})
print(f"✅ FAQ 数据已导出到: {csv_file}")
return True
except Exception as e:
print(f"❌ 导出 CSV 数据失败: {e}")
return False
def create_sample_data():
"""
创建示例数据
"""
preparer = FAQDataPreparer("sample_faq.json")
# 添加示例数据
sample_faqs = [
{
"question": "如何注册账户?",
"answer": "您可以通过官网首页点击'注册'按钮,填写邮箱和密码完成注册。",
"category": "account"
},
{
"question": "忘记密码怎么办?",
"answer": "在登录页面点击'忘记密码',输入注册邮箱,系统会发送重置链接到您的邮箱。",
"category": "account"
},
{
"question": "支持哪些支付方式?",
"answer": "我们支持支付宝、微信支付、银行卡支付等多种支付方式。",
"category": "payment"
}
]
for faq in sample_faqs:
preparer.add_faq_item(faq["question"], faq["answer"], faq["category"])
# 验证数据
preparer.validate_data()
# 导出数据
preparer.export_to_json()
def main():
"""
主函数
"""
create_sample_data()
if __name__ == "__main__":
# main()
print("FAQ 数据准备工具准备就绪")
第六章:架构设计与流程优化
6.1 系统架构设计
6.2 处理流程优化
6.3 性能监控工具
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
performance_monitor.py
性能监控工具
"""
import time
import psutil
import threading
from typing import Dict, List, Callable
from collections import defaultdict, deque
class PerformanceMonitor:
"""
性能监控器
"""
def __init__(self):
"""
初始化性能监控器
"""
self.metrics = defaultdict(deque)
self.max_history = 1000
self.monitoring = False
self.monitor_thread = None
def start_monitoring(self, interval: float = 1.0):
"""
开始监控
Args:
interval (float): 监控间隔(秒)
"""
if self.monitoring:
print("⚠️ 监控已在运行中")
return
self.monitoring = True
self.monitor_thread = threading.Thread(
target=self._monitor_loop,
args=(interval,),
daemon=True
)
self.monitor_thread.start()
print(f"✅ 开始性能监控 (间隔: {interval} 秒)")
def stop_monitoring(self):
"""
停止监控
"""
self.monitoring = False
if self.monitor_thread:
self.monitor_thread.join()
print("⏹️ 性能监控已停止")
def _monitor_loop(self, interval: float):
"""
监控循环
Args:
interval (float): 监控间隔
"""
while self.monitoring:
try:
# 收集系统指标
timestamp = time.time()
# CPU 使用率
cpu_percent = psutil.cpu_percent(interval=0.1)
self._add_metric("cpu_percent", timestamp, cpu_percent)
# 内存使用率
memory = psutil.virtual_memory()
self._add_metric("memory_percent", timestamp, memory.percent)
self._add_metric("memory_used_gb", timestamp, memory.used / (1024**3))
# 磁盘使用率
disk = psutil.disk_usage('/')
disk_percent = (disk.used / disk.total) * 100
self._add_metric("disk_percent", timestamp, disk_percent)
time.sleep(interval)
except Exception as e:
print(f"❌ 监控过程中出错: {e}")
def _add_metric(self, metric_name: str, timestamp: float, value: float):
"""
添加指标数据
Args:
metric_name (str): 指标名称
timestamp (float): 时间戳
value (float): 指标值
"""
self.metrics[metric_name].append((timestamp, value))
# 保持历史数据在限制范围内
while len(self.metrics[metric_name]) > self.max_history:
self.metrics[metric_name].popleft()
def record_operation(self, operation_name: str, duration: float):
"""
记录操作性能
Args:
operation_name (str): 操作名称
duration (float): 持续时间(秒)
"""
timestamp = time.time()
self._add_metric(f"operation_{operation_name}_duration", timestamp, duration)
print(f"⏱️ 操作 {operation_name} 耗时: {duration:.3f} 秒")
def get_system_metrics(self, minutes: int = 5) -> Dict:
"""
获取系统指标
Args:
minutes (int): 时间范围(分钟)
Returns:
Dict: 系统指标
"""
cutoff_time = time.time() - (minutes * 60)
metrics_summary = {}
for metric_name, data_points in self.metrics.items():
# 过滤时间范围内的数据
recent_data = [(t, v) for t, v in data_points if t >= cutoff_time]
if recent_data:
values = [v for t, v in recent_data]
metrics_summary[metric_name] = {
"count": len(values),
"min": min(values),
"max": max(values),
"avg": sum(values) / len(values),
"latest": values[-1] if values else None
}
return metrics_summary
def print_system_summary(self, minutes: int = 5):
"""
打印系统摘要
Args:
minutes (int): 时间范围(分钟)
"""
metrics = self.get_system_metrics(minutes)
print(f"\n📊 系统性能摘要 (最近 {minutes} 分钟)")
print("=" * 50)
# 系统资源指标
resource_metrics = ["cpu_percent", "memory_percent", "disk_percent"]
for metric in resource_metrics:
if metric in metrics:
data = metrics[metric]
print(f"{metric}:")
print(f" 平均: {data['avg']:.1f}%")
print(f" 最高: {data['max']:.1f}%")
print(f" 最低: {data['min']:.1f}%")
print(f" 当前: {data['latest']:.1f}%")
print()
# 操作性能指标
operation_metrics = [k for k in metrics.keys() if k.startswith("operation_")]
if operation_metrics:
print("⏱️ 操作性能:")
for metric in operation_metrics:
data = metrics[metric]
operation_name = metric.replace("operation_", "").replace("_duration", "")
print(f" {operation_name}:")
print(f" 平均耗时: {data['avg']:.3f} 秒")
print(f" 最大耗时: {data['max']:.3f} 秒")
print(f" 最小耗时: {data['min']:.3f} 秒")
print()
def timed_operation(monitor: PerformanceMonitor, operation_name: str):
"""
装饰器:记录操作耗时
Args:
monitor (PerformanceMonitor): 性能监控器
operation_name (str): 操作名称
"""
def decorator(func: Callable):
def wrapper(*args, **kwargs):
start_time = time.time()
try:
result = func(*args, **kwargs)
return result
finally:
end_time = time.time()
duration = end_time - start_time
monitor.record_operation(operation_name, duration)
return wrapper
return decorator
def main():
"""
主函数 - 演示性能监控
"""
monitor = PerformanceMonitor()
# 开始监控
monitor.start_monitoring(interval=1.0)
# 模拟一些操作
@timed_operation(monitor, "model_inference")
def simulate_model_inference():
"""模拟模型推理"""
time.sleep(0.5) # 模拟推理时间
return "模型推理完成"
@timed_operation(monitor, "data_processing")
def simulate_data_processing():
"""模拟数据处理"""
time.sleep(0.2) # 模拟处理时间
return "数据处理完成"
# 执行操作
for i in range(10):
simulate_model_inference()
simulate_data_processing()
time.sleep(0.1)
# 打印摘要
monitor.print_system_summary(minutes=1)
# 停止监控
monitor.stop_monitoring()
if __name__ == "__main__":
# main()
print("性能监控工具准备就绪")
第七章:注意事项与最佳实践
7.1 内存管理
大模型运行需要大量内存,建议配置足够的内存:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
memory_manager.py
内存管理工具
"""
import psutil
import gc
import torch # 如果使用 PyTorch 模型
from typing import Dict
class MemoryManager:
"""
内存管理器
"""
def __init__(self, memory_threshold: float = 80.0):
"""
初始化内存管理器
Args:
memory_threshold (float): 内存使用率阈值(百分比)
"""
self.memory_threshold = memory_threshold
print(f"🔧 内存管理器初始化,阈值: {memory_threshold}%")
def check_memory_usage(self) -> Dict:
"""
检查内存使用情况
Returns:
Dict: 内存使用信息
"""
memory = psutil.virtual_memory()
usage_info = {
"total_gb": memory.total / (1024**3),
"available_gb": memory.available / (1024**3),
"used_gb": memory.used / (1024**3),
"percent": memory.percent,
"threshold_exceeded": memory.percent > self.memory_threshold
}
status = "⚠️" if usage_info["threshold_exceeded"] else "✅"
print(f"{status} 内存使用情况:")
print(f" 总量: {usage_info['total_gb']:.1f} GB")
print(f" 已用: {usage_info['used_gb']:.1f} GB")
print(f" 可用: {usage_info['available_gb']:.1f} GB")
print(f" 使用率: {usage_info['percent']:.1f}%")
return usage_info
def cleanup_memory(self):
"""
清理内存
"""
print("🧹 正在清理内存...")
# 强制垃圾回收
collected = gc.collect()
print(f" 垃圾回收: {collected} 个对象")
# 如果使用 PyTorch,清理 CUDA 缓存
if torch.cuda.is_available():
torch.cuda.empty_cache()
print(" CUDA 缓存已清理")
# 检查清理后的内存使用情况
self.check_memory_usage()
def monitor_and_manage(self):
"""
监控并管理内存
"""
usage = self.check_memory_usage()
if usage["threshold_exceeded"]:
print("🚨 内存使用率超过阈值,建议清理内存")
self.cleanup_memory()
else:
print("✅ 内存使用正常")
def main():
"""
主函数
"""
manager = MemoryManager(memory_threshold=80.0)
manager.monitor_and_manage()
if __name__ == "__main__":
# main()
print("内存管理工具准备就绪")
7.2 模型选择指南
根据实际需求选择合适的模型:
| 模型 | 大小 | 特点 | 适用场景 |
|---|---|---|---|
| Llama2 | 3.8GB-7GB | 通用能力强 | 通用对话、文本生成 |
| Mistral | 4.1GB | 对话效果好 | 客服对话、聊天机器人 |
| Phi | 1.6GB-3.8GB | 轻量高效 | 资源受限环境 |
| CodeLlama | 3.8GB-7GB | 代码理解 | 代码生成、技术问答 |
7.3 安全配置
确保本地网络的安全,防止未授权访问:
# 配置防火墙(Ubuntu/Debian)
sudo ufw enable
sudo ufw allow from 192.168.1.0/24 to any port 11434 # 仅允许局域网访问
sudo ufw deny 11434 # 拒绝外部访问
# 使用 reverse proxy(Nginx)增加安全层
sudo apt install nginx
第八章:常见问题解答
Q1: 本地部署大模型需要多长时间?
A: 通常需要 10-30 分钟,具体取决于硬件配置和网络速度。
Q2: 如何选择合适的模型?
A: 根据应用场景选择,例如 Llama2 适合通用场景,Mistral 适合对话场景。
Q3: 如何优化性能?
A: 可以通过缓存机制、模型微调等方式优化性能。
Q4: Windows 系统如何部署?
A: 建议使用 WSL2 环境或者 Docker Desktop 运行 Ollama。
Q5: 模型运行时内存不足怎么办?
A: 可以尝试使用参数量化模型,或者升级硬件配置。
第九章:扩展阅读
9.1 推荐文档
9.2 相关工具
- LM Studio: 本地模型运行平台
- Jan: 开源的本地 AI 操作系统
- GPT4All: 本地运行的大语言模型
9.3 最佳实践文章
本地大模型部署实施计划甘特图
模型性能对比饼图
智能客服系统时序图
🏁 总结
本文详细介绍了如何在本地部署大模型(以 Ollama 为例),并将其应用于实际开发中。通过环境准备、部署步骤、配置方法、实践案例、架构设计、流程优化等多个方面的讲解,帮助开发者快速掌握本地大模型的使用方法。
关键要点总结:
- 环境准备:确保硬件配置满足要求,安装必要的软件依赖
- Ollama 部署:正确安装和配置 Ollama 服务
- 模型选择:根据应用场景选择合适的模型
- 应用集成:将大模型集成到实际业务系统中
- 性能优化:通过缓存、监控等手段优化系统性能
- 安全加固:确保本地部署的安全性
实践是检验真理的唯一标准,立即动手 部署属于你的本地大模型吧!



















 7507
7507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











