






 本文详细介绍了如何在NVIDIA Orin/Xavier设备上通过Docker安装和配置TensorFlow深度学习环境。步骤包括安装Docker和nvidia-docker2,拉取TensorFlow镜像,并测试GPU是否正常工作。同时,文章提醒注意Jetson版本和TensorFlow版本的匹配,以及镜像大小和存储需求。
本文详细介绍了如何在NVIDIA Orin/Xavier设备上通过Docker安装和配置TensorFlow深度学习环境。步骤包括安装Docker和nvidia-docker2,拉取TensorFlow镜像,并测试GPU是否正常工作。同时,文章提醒注意Jetson版本和TensorFlow版本的匹配,以及镜像大小和存储需求。
本文章将介绍如何通过docker在边缘计算设备nvidia orin/xavier上快速配置深度学习环境.该方法适用于Tensorflow,Pytorch,但是本文以介绍Tensorflow的安装为主.
文章目录
第一步:安装docker
首先我们需要安装docker,可以直接通过小鱼来安装:
wget http://fishros.com/install -O fishros && . fishros
安装完成后,我们需要给用户赋予权限:
sudo docker ps
sudo docker images
sudo gpasswd -a $USER docker
newgrp docker
docker ps
docker images
sudo systemctl restart docker
加载重启docker
service docker restart
查看是否成功
docker info
如果打印出来以下信息,说明docker已经配置完毕了
Client:
Context: default
Debug Mode: false
Plugins:
app: Docker App (Docker Inc., v0.9.1-beta3)
buildx: Docker Buildx (Docker Inc., v0.9.1-docker)
Server:
Containers: 0
Running: 0
Paused: 0
Stopped: 0
Images: 0
Server Version: 20.10.21
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
userxattr: false
Logging Driver: json-file
Cgroup Driver: cgroupfs
Cgroup Version: 1
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
Swarm: inactive
Runtimes: io.containerd.runc.v2 io.containerd.runtime.v1.linux nvidia runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 770bd0108c32f3fb5c73ae1264f7e503fe7b2661
runc version: v1.1.4-0-g5fd4c4d
init version: de40ad0
Security Options:
seccomp
Profile: default
Kernel Version: 5.10.104-tegra
Operating System: Ubuntu 20.04.4 LTS
OSType: linux
Architecture: aarch64
CPUs: 8
Total Memory: 29.82GiB
Name: tegra-ubuntu
ID: xxx
Docker Root Dir: /var/lib/docker
Debug Mode: false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
还可以运行一个hello的容器测试一下:
docker run hello-world
会显示以下信息:
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
7050e35b49f5: Pull complete
Digest: sha256:faa03e786c97f07ef34423fccceeec2398ec8a5759259f94d99078f264e9d7af
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(arm64v8)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
第二步:安装nvidia-docker2
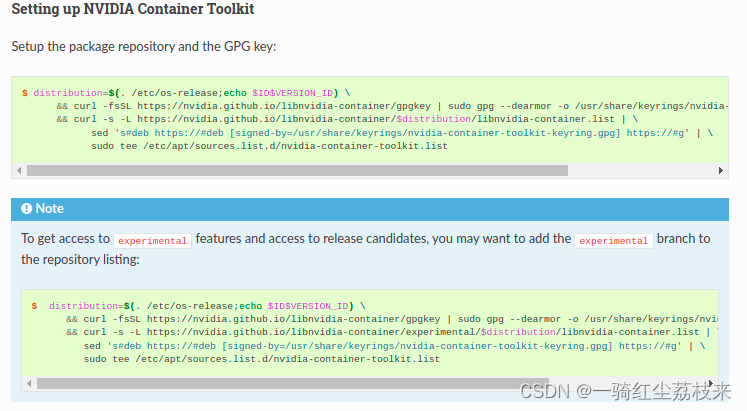
官方的指导网站为:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
运行前三步就可以了,没必要去pull那个nvidia/cuda的镜像,太大了,pull下来比较慢而且占空间.
第三步:拉取tensorflow镜像
3.1 确定容器版本
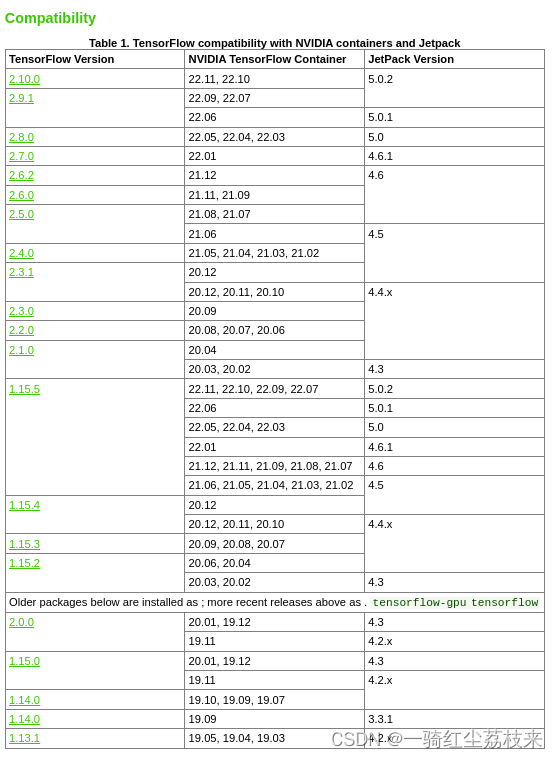
安装pytorch或者tensorflow最好是遵守Jetson的版本(否则很有可能安装完后运行出BUG).所以我们需要查看Jetson,NVIDIA Tensorflow Container和tensorflow的版本.
关于NVIDIA Tensorflow Container的包含的内容,版本等信息,可以查看这个网站:
https://docs.nvidia.com/deeplearning/frameworks/support-matrix/index.html#framework-matrix-2021
tensorflow版本要求,可以看这个:
https://docs.nvidia.com/deeplearning/frameworks/install-tf-jetson-platform-release-notes/tf-jetson-rel.html#tf-jetson-rel
tensorflow版本截图如下:
关于如何查询Jetson版版本,可以查看这个文章:
https://blog.youkuaiyun.com/condom10010/article/details/128100956
我们这里Jetson版本是 5.0.2,而我们需要tensorflow2.x,因此确定我们需要拉取的Nvidia tensorflow Container版本为22.10.
3.2 拉取镜像
使用终端命令拉取:
docker run --runtime=nvidia -it nvcr.io/nvidia/tensorflow:22.10-tf2-py3
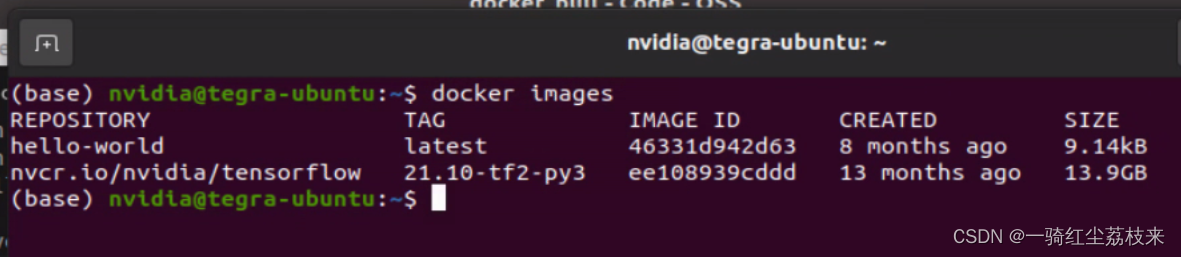
下载的大小6-7GB,所以需要很久,放一边等着就行了.下载完毕之后可以查看一下,发现镜像有13.9GB.
3.3 测试是否能够正常使用GPU
$ python
>>> import tensorflow as tf
# If tf2
>>> tf.config.list_physical_devices("GPU").__len__() > 0
返回一个True说明此时已经配置完毕了。
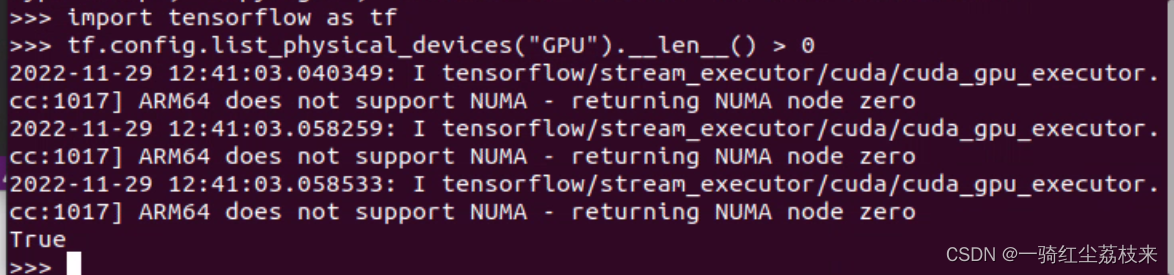
也可以再试一下tf.config.list_physical_devices("GPU"),也会打印出当前可用的GPU。

3.4 打包镜像
通过docker images查看发现这个镜像大的离谱
然后我们把这个镜像离线保存下来,避免下次配置的时候还要消耗流量。
由于镜像打包起来也非常大,而且非常耗时间和cpu算力,所以打包的还是不要操作机器,预留20GB空间,再进行打包。
docker save -o nvidia_tensorflow_21.10-tf2-py3.tar nvcr.io/nvidia/tensorflow
打包后的镜像有14GB。体积并没有缩小。
附录
最初,我是在这个网站上找到了教程:https://cloud.tencent.com/developer/article/2073473
,教程里面提到了nvidia的NGC官网,打开找到深度学习框架,再点击tensorflow,会跳转到tensorflow的docker镜像页中,也可以找到pytorch的docker镜像页.
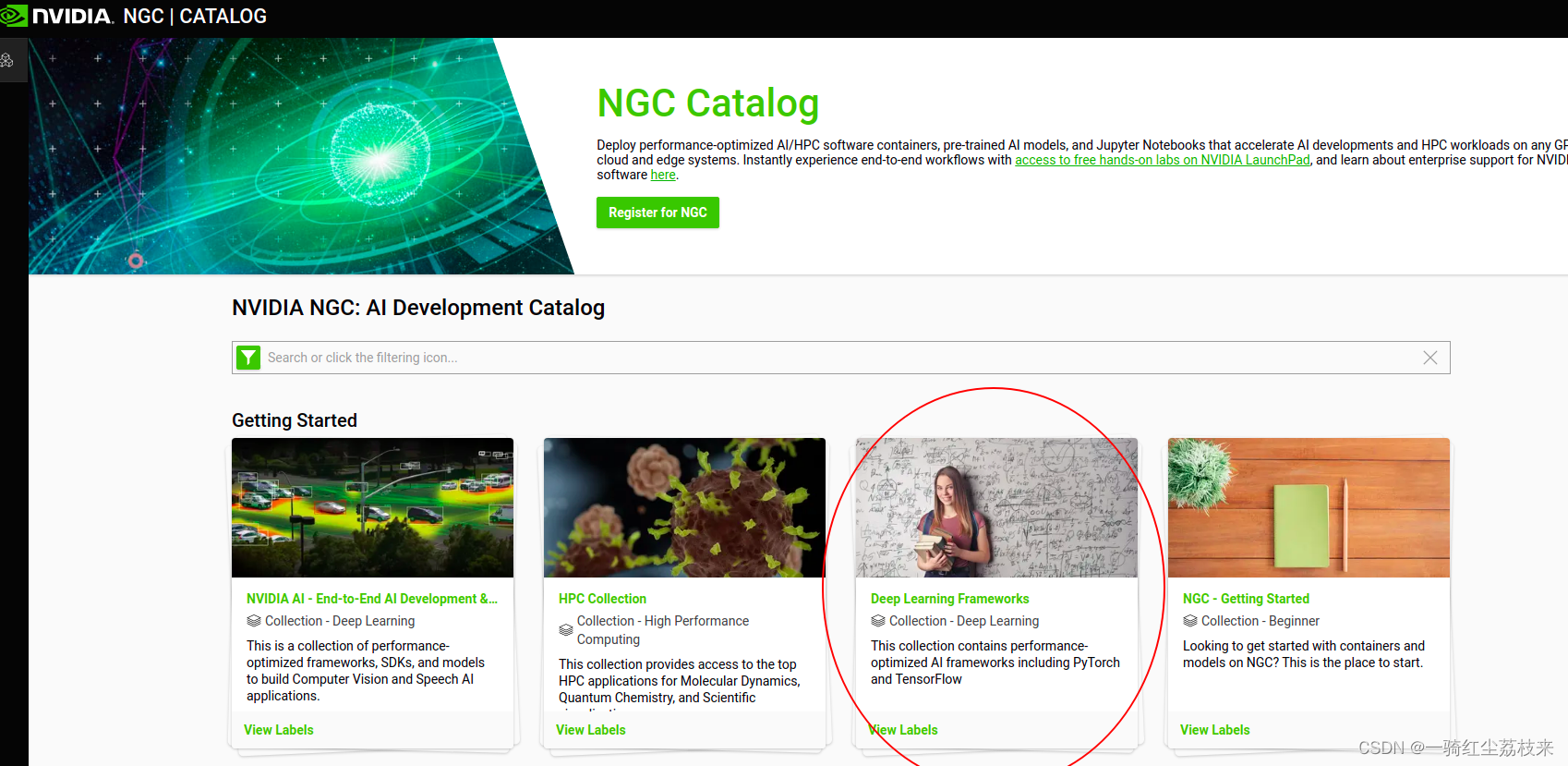
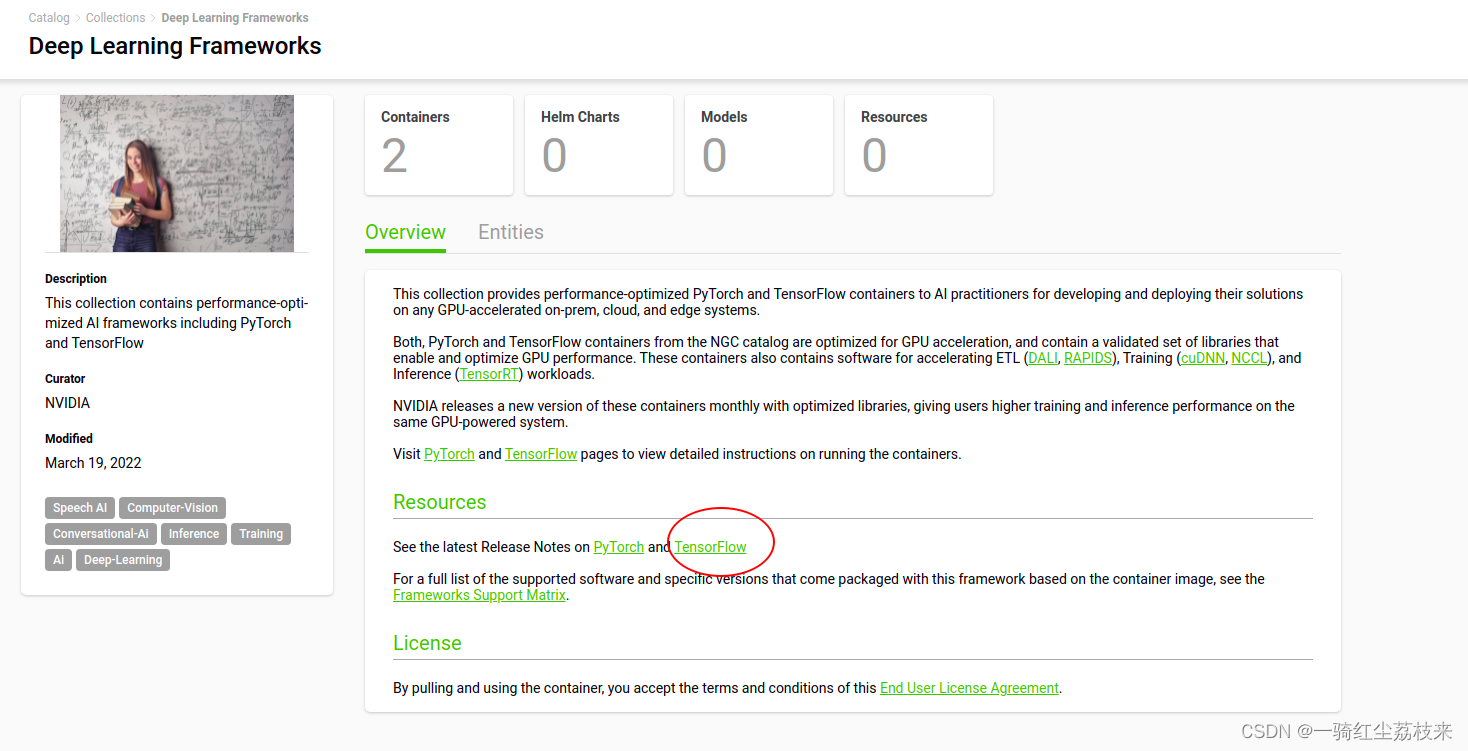
tensorflow主页
容器内具体内容
在下面的 What is In This Container里面可以看到容器的具体内容


pytorch 主页
pytorch版本要求,可以看这个:
https://docs.nvidia.com/deeplearning/frameworks/install-pytorch-jetson-platform-release-notes/pytorch-jetson-rel.html#pytorch-jetson-rel
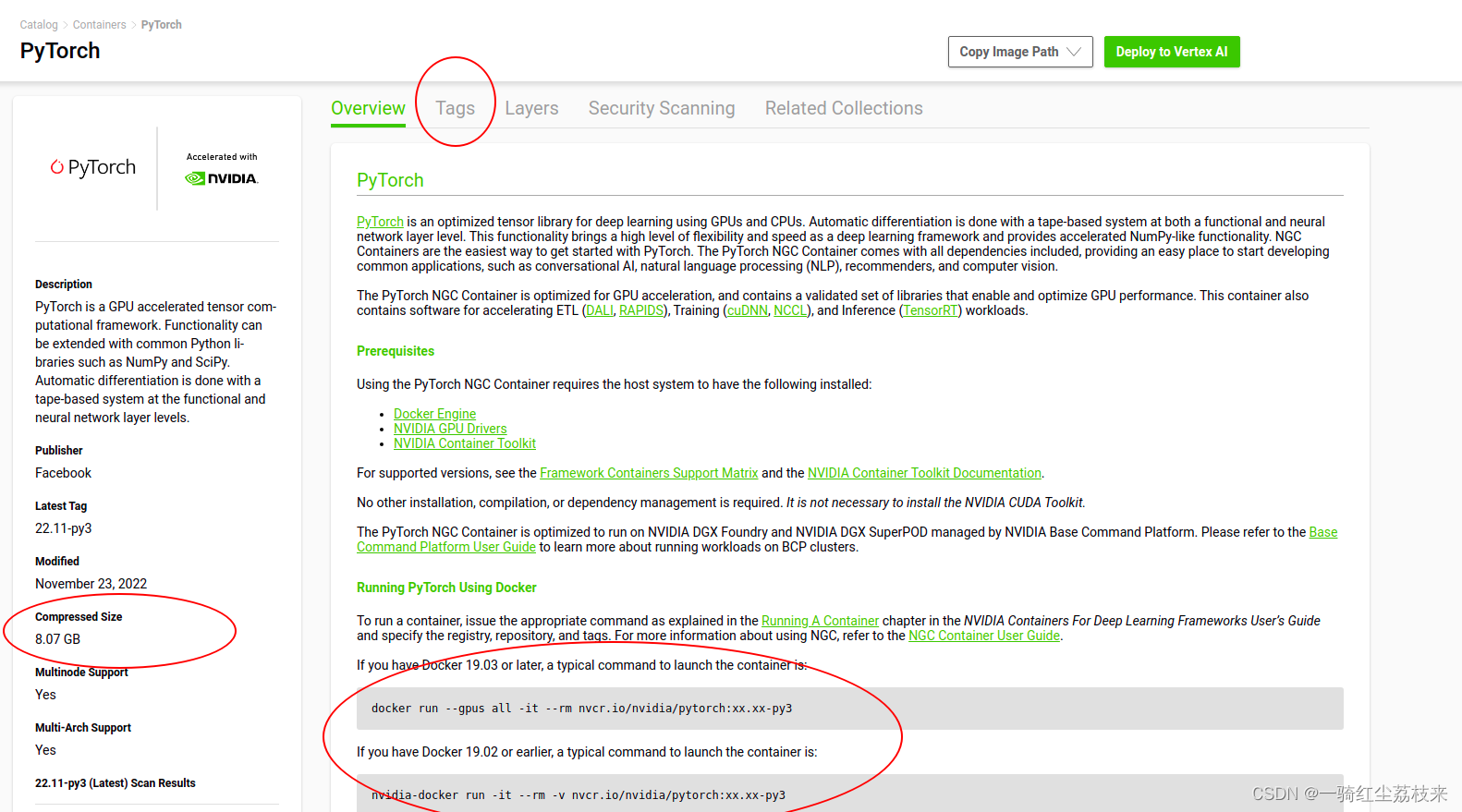
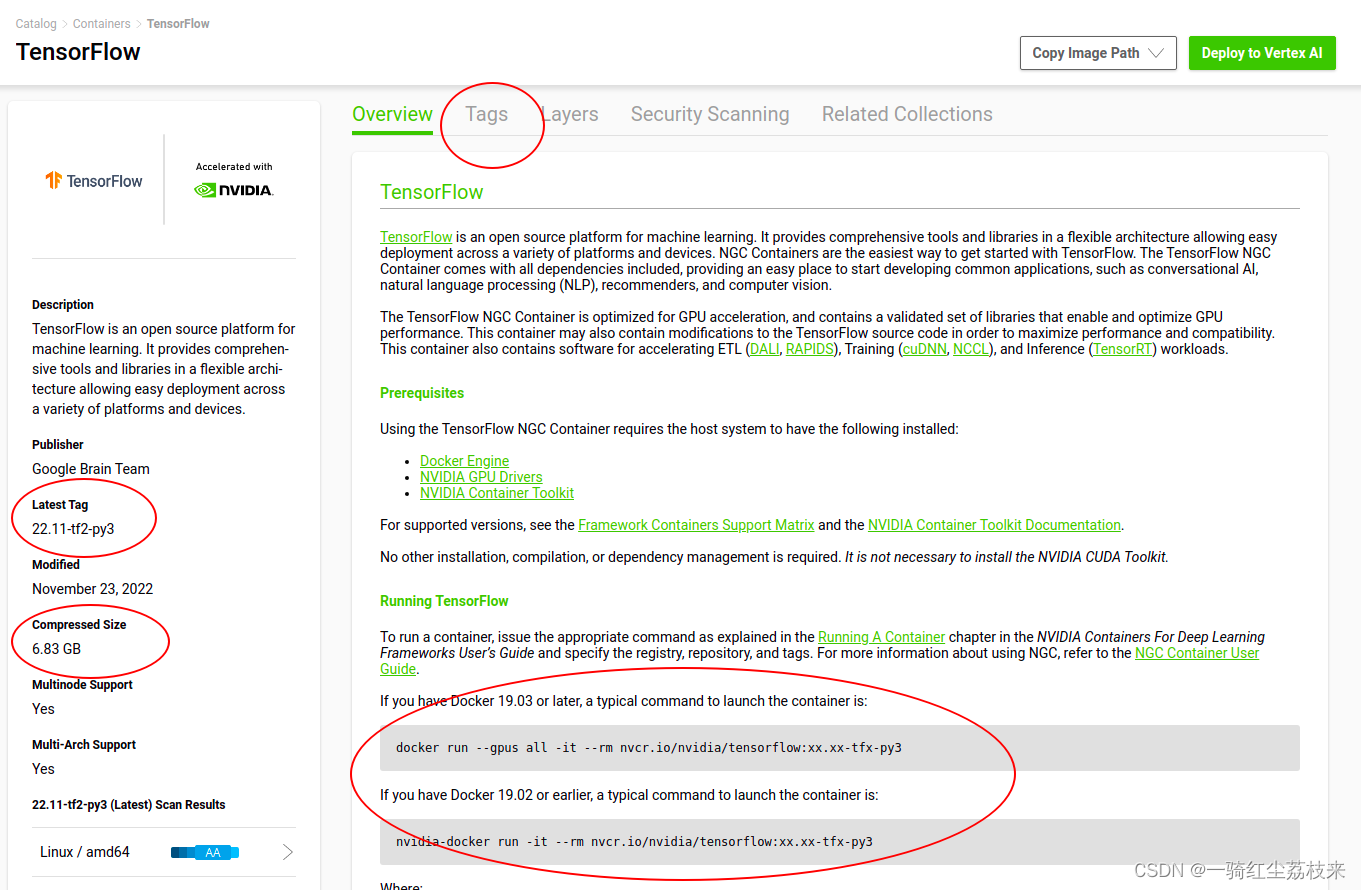
打开主页后,需要留意的几个点:
(1)左边的镜像大小:安装前需要注意你的机器上的存储空间够不够.实际上在上面页面里提到的大小都远远小于真实的镜像的大小,实际的一个镜像文件的大小是13-14GB,所以对设备存储容量有比较高的要求。
(2)上方的Tags标签:从这里选择需要拉取的镜像的版本
(3)下方的Running Pytorch Using Docker or Running Tensorflow :给出了我们想要的镜像的终端启动命令.



















 1925
1925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









