



 本文详细解释了LSTM中的遗忘门、输入门和输出门的功能,以及它们如何控制细胞状态和隐藏层之间的信息流动,以实现学习过程中的内容选择和保留。作者还讨论了这些门在训练中的作用和背后的原理。
本文详细解释了LSTM中的遗忘门、输入门和输出门的功能,以及它们如何控制细胞状态和隐藏层之间的信息流动,以实现学习过程中的内容选择和保留。作者还讨论了这些门在训练中的作用和背后的原理。
我们都知道LSTM有三个门结构:遗忘门,输入门,输出门:
遗忘门如图1所示:
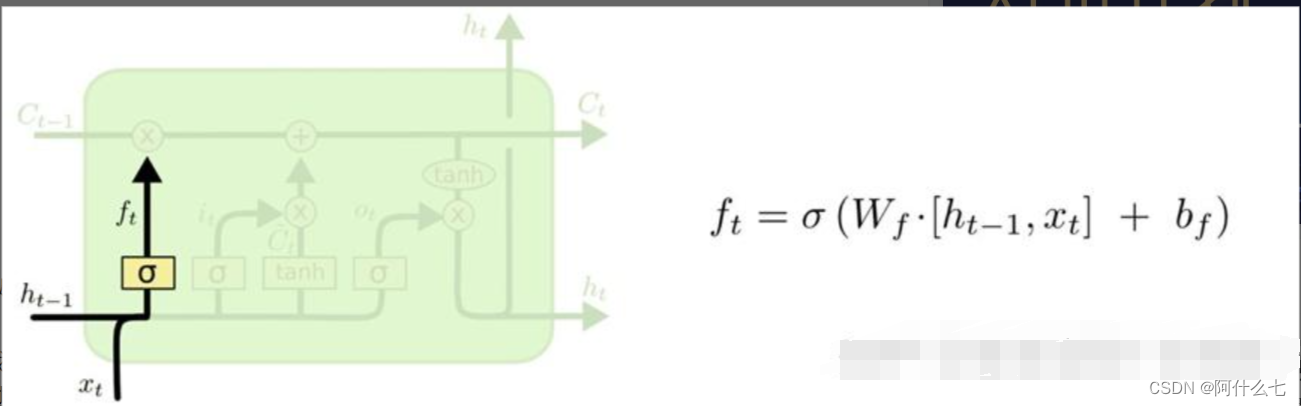 图1
图1
遗忘门是针对对上一时刻,它的作用对象是Ct-1,即上一时刻的细胞状态,ht-1上一时刻的隐藏层,与Xt结合后,通过激活函数,那么ht-1和Xt的权重是针对事实的情况变化的,例如Xt时刻我们想充分学习高数,但是ht-1是线代的学习状态,此时Xt权重应该要大,才能满足要求,最后与上一时刻的细胞状态Ct-1相乘后,我们遗忘的是线代的大部分内容,留下的是高数的内容。
而输入门是针对此时刻的,结构如图2所示,很明显,若要达到学习高数的目的,我们必须使得高数的知识尽可能的留下来,同时线性代数中非高数的去掉,ht-1和X结合后通过激活函数很好理解,不仅归一化,同时,也可以把他们当做经过tanh的结果的系数,即激活函数后的结果是作用于tanh上的,为什么要经过tanh呢,我的理解是tanh是(-1,1)的范围,-1可以使纯线代剔除,目的就是为了输入高数的内容,与遗忘门对比来看,就比较好理解。最后,遗忘门中留下来的高数和输入门的高数相加,相加过程如图3,使得细胞之间具有连贯性,相加的结果即为此时刻的细胞状态Ct(我们学习高数的状态)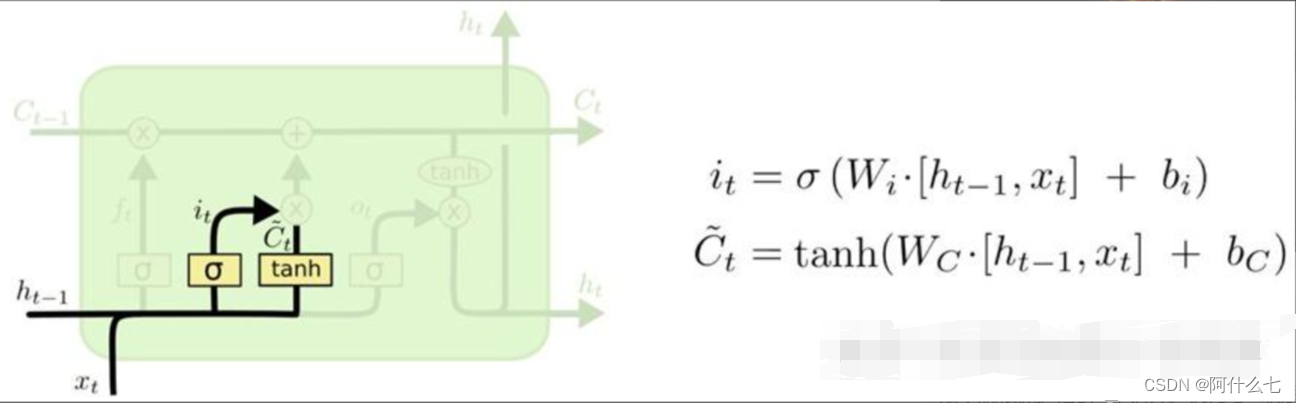 图2
图2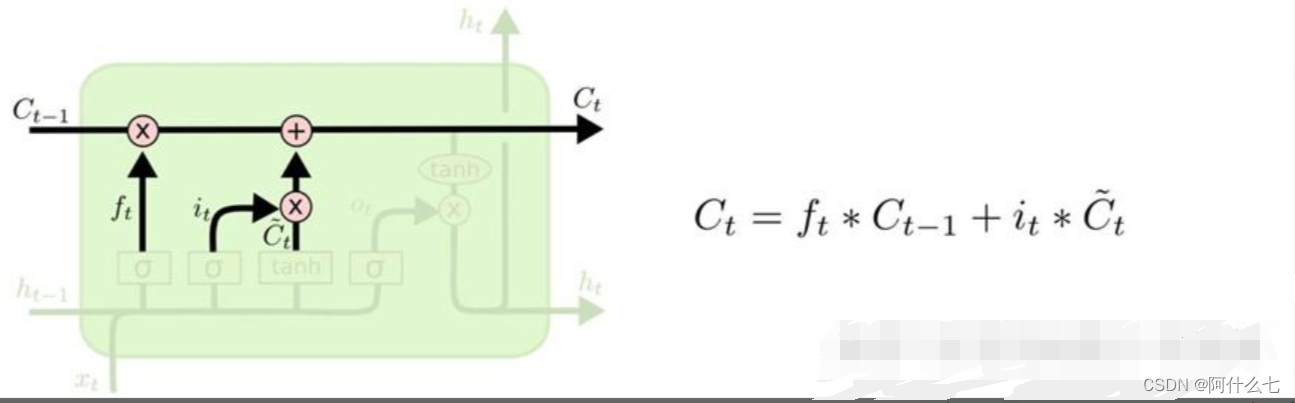 图3
图3
最后还有一个输出门,我把他理解为学习的一个效果,前面得到的Ct可以理解为我们要学习的所有高数内容,但是掌握的好坏区别很大,如图4所示,Ct经过tanh可以理解为区分掌握的好坏情况,因为范围(-1,1)比较大,容易区分。当然,此时的学习高数的状态Xt也是对此时刻的隐藏状态ht有影响的,我们直接用ht-1和X经过激活函数后的结果作用于Ct经过tanh的结果,虽然Ct也有Xt(学习的高数影响)的影子,但是效果可能没有直接作用在Ct经过tanh的结果上好。
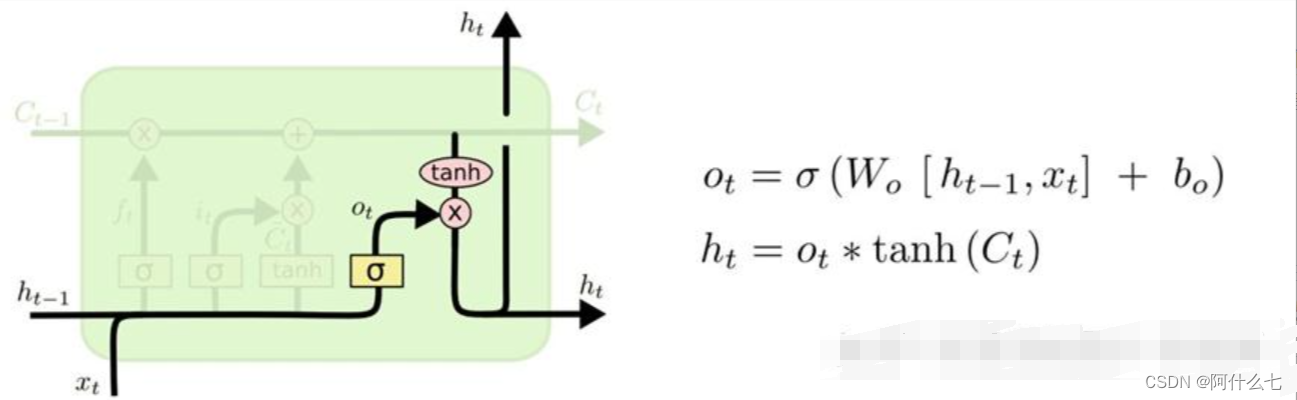 图4
图4
上面是我对LSTM一些简单的理解,不足之处欢迎各位批评指正。最后,遗忘门可以遗忘掉我们不想要的信息,输入门可以提纯信息,输出门是我们学习的效果,为什么可以达到这样的目的是在训练所需要完成的,当然,仍然有很多技术细节,例如激活函数的选择上为什么是这样,结构上又要为什么要这样设计,需要翻阅大量的文献资料和视频资料去补充。

















 4146
4146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









