




AI模型的微调和训练是人工智能领域中非常重要的技术手段,尤其是在大模型时代,这些技术的应用范围和重要性日益增加.
一、什么是AI模型微调?
微调(Fine-tuning)是指在已经预训练好的大规模模型基础上,通过进一步训练来适应特定任务或数据集的过程。这一过程体现了迁移学习的思想,即利用预训练模型在通用数据上学习到的知识,通过微调使其更好地服务于特定的应用场景.
微调的主要步骤:
-
选择预训练模型:从现有的大型预训练模型(如BERT、GPT、T5等)中挑选适合任务需求的模型作为基础。
-
准备数据集:为特定任务准备高质量的训练和验证数据集,确保数据与目标任务紧密相关。
-
调整模型结构(可选) :根据任务需求,可能需要对模型结构进行微调,如增减层数、调整激活函数等。
-
设置训练参数:包括学习率、批处理大小、训练轮次等,这些参数将直接影响微调效果。
-
开始训练:在选定数据集上迭代训练模型,并观察验证集上的表现,适时调整训练策略。
-
评估与部署:使用测试集评估微调后的模型性能,满足要求后即可部署到实际应用中。
以上就是AI模型微调步骤,不管是模型微调和模型训练都少不了模型微调和模型训练需要的数据集。我们知道要想微调和训练模型数据集非常重要。早期数据集都是靠人工标注或者是通过程序来实现,对非技术人员不太友好,换句话说微调数据集制作门槛就非常高,普通小白是很难上手的。那么有没有什么好的办法快速实现数据集的制作呢?答案是有的今天给大家带来使用dify 实现一个微调(Fine-tuning)语料构造工作流,话不多说,下面带大家实际操作一下。
二、微调(Fine-tuning)语料构造工作流
我们首先给大家先展现一下制作好的工作流,工作流如下界面
这里主要是分为5个部分。分别是:开始、文档提取器、代码执行、LLM大语言模型、结束 5个部分。
开始
我们打开dify,创建一个空白页面-选择工作流,我们给应用起个名字。
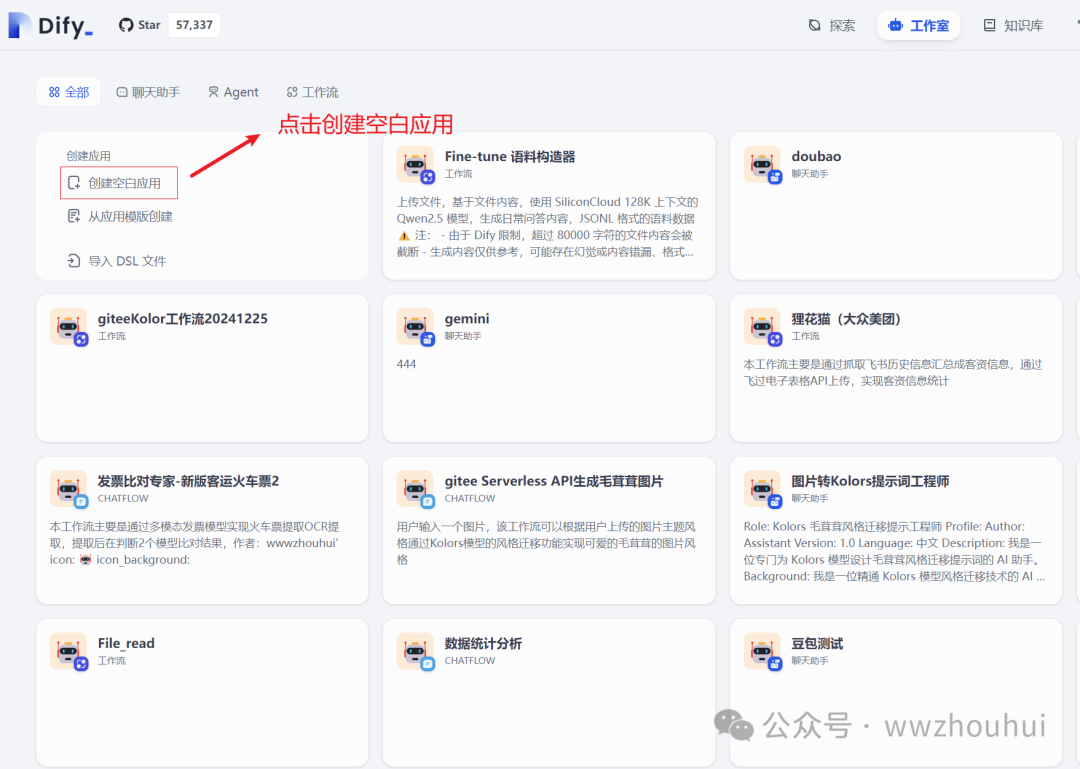
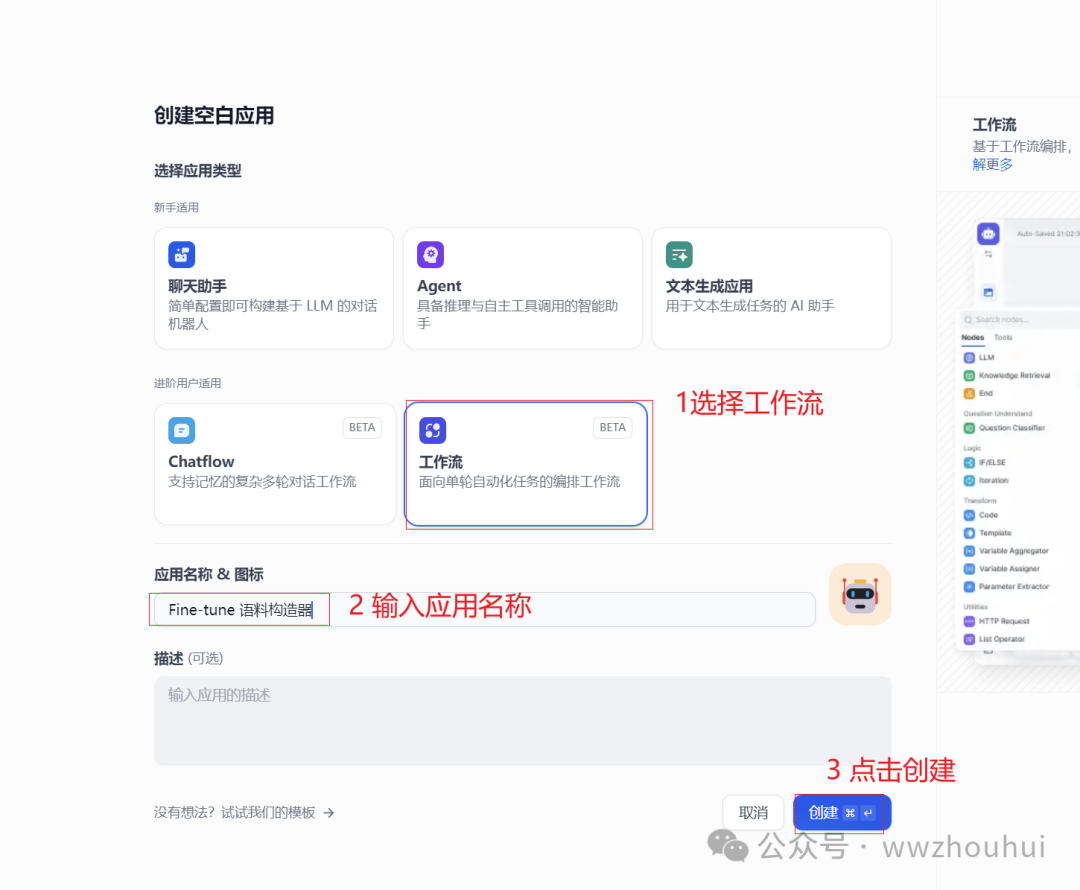
创建完成后我们进入工作流画布界面
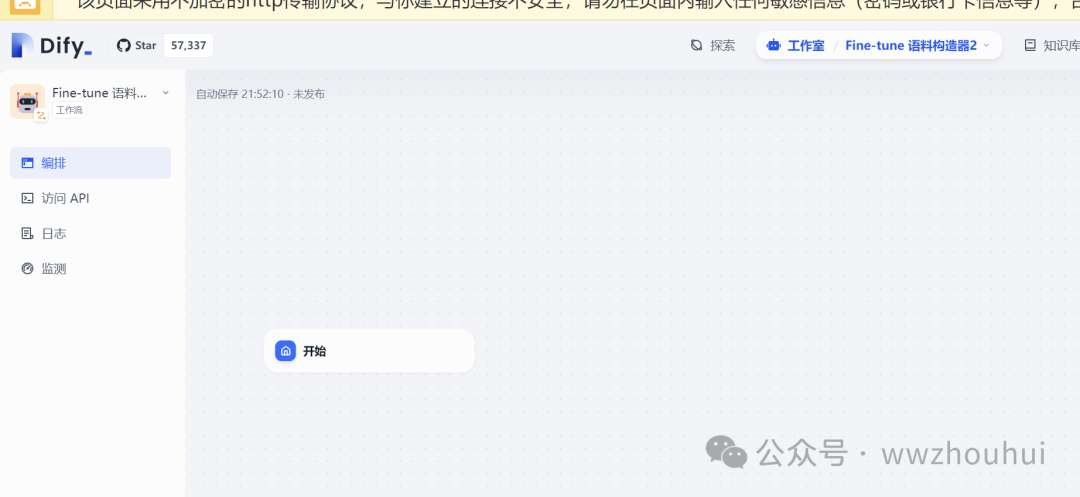
我们在开始节点中新建2个输入参数。1个是用户上传的文件,1个是触发词(训练中的 system prompt)
下面我们先看第一个参数attachments,
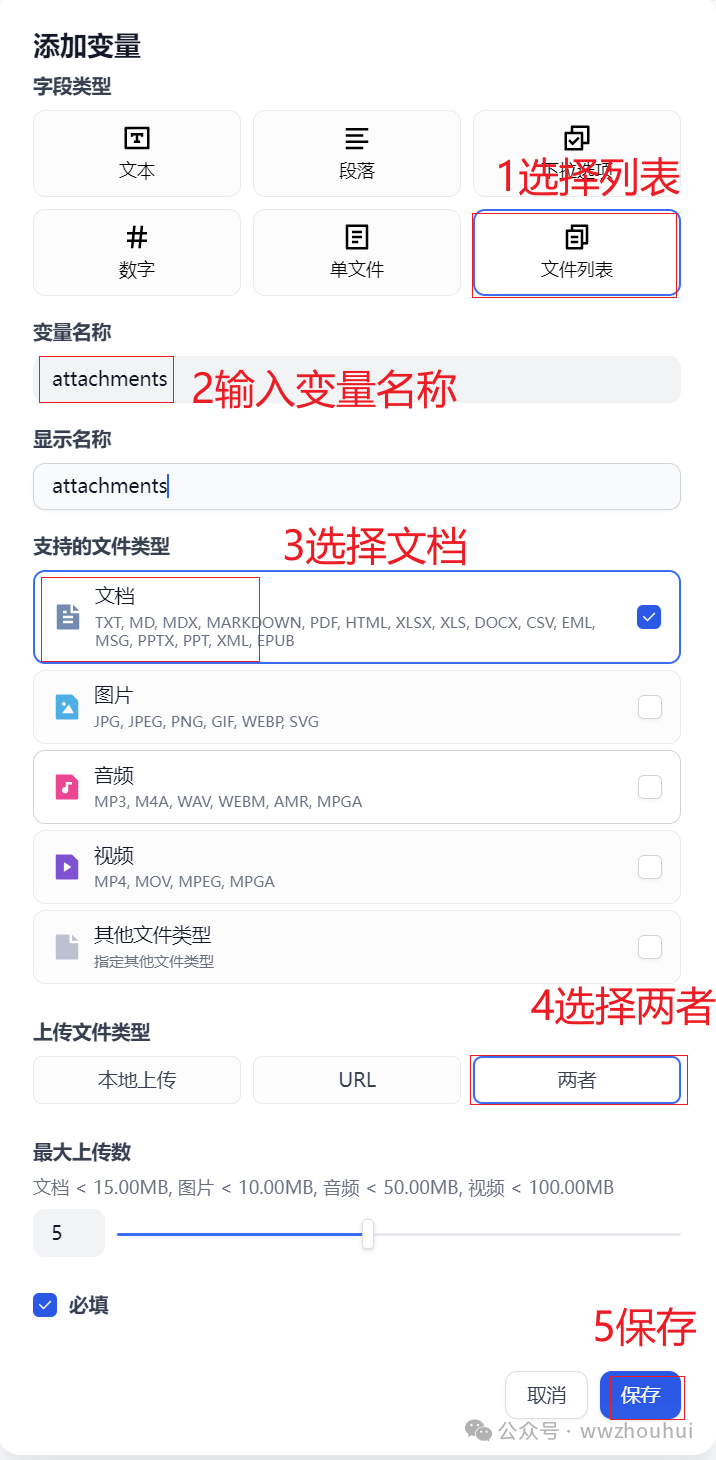
我们参考上图完成第一个参数的设置。接下来我们在设置第二个参数触发词
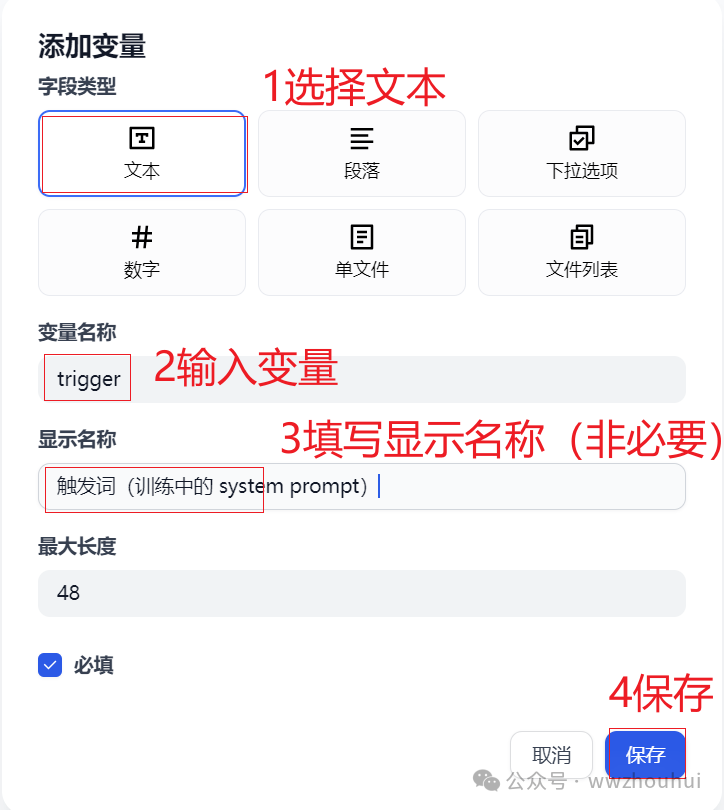
&nb
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1242
1242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











