




项目概述
本项目是一个基于大模型的智能文档格式转换系统,专门用于将非结构化的学术论文PDF文档,自动、精准地转换为符合学术出版标准的LaTeX格式。系统集成了PaddleOCR-VL进行文档识别、结构化处理,以及大语言模型进行格式转换,实现了从PDF到LaTeX的端到端转换流程。该系统致力于解决研究人员和学生在论文格式调整上耗时费力的问题,大幅提升学术文档准备的效率与质量。
处理流程详解
- PDF文档输入 - 用户提供待转换的PDF文档
- PaddleOCR-VL识别 - 提取文本、表格、公式、图片等结构化内容
- Markdown生成 - 将识别结果转换为Markdown格式
- 格式分析 - 分析需要的标准LaTeX文档格式,生成转换配置
- 大模型转换 - 基于格式配置将Markdown转换为LaTeX
- PDF编译 - 将LaTeX文档编译为最终PDF
系统架构图
graph TD
A[PDF输入] --> B[PaddleOCR-VL识别]
B --> C[Markdown生成]
C --> D[格式分析]
D --> E[大模型转换]
E --> F[LaTeX生成]
F --> G[PDF编译]
技术亮点
- 多模态文档理解: 基于PaddleOCR-VL的智能文档解析
- 大模型驱动转换: 利用ERNIE-4.5-Turbo进行格式转换
- 端到端流程: 从PDF到LaTeX的完整自动化转换
- 分段处理机制: 支持长文档的智能分段转换
应用场景
- 学术论文格式标准化
- 会议论文格式转换
- 期刊投稿格式调整
- 多语言文档处理
前言
PaddleOCR-VL 模型简介
PaddleOCR-VL 是百度飞桨(PaddlePaddle)于 2025 年 10 月正式发布的新一代多模态文档解析模型,专为复杂文档的智能理解与结构化处理而设计。该模型仅包含 0.9B 参数,却在多个权威文档解析评测中刷新纪录,达到当前业界领先水平(SOTA),同时支持 109 种语言的文档解析能力,覆盖中文、英文、俄语、阿拉伯语、印地语等主流及小语种文字体系。
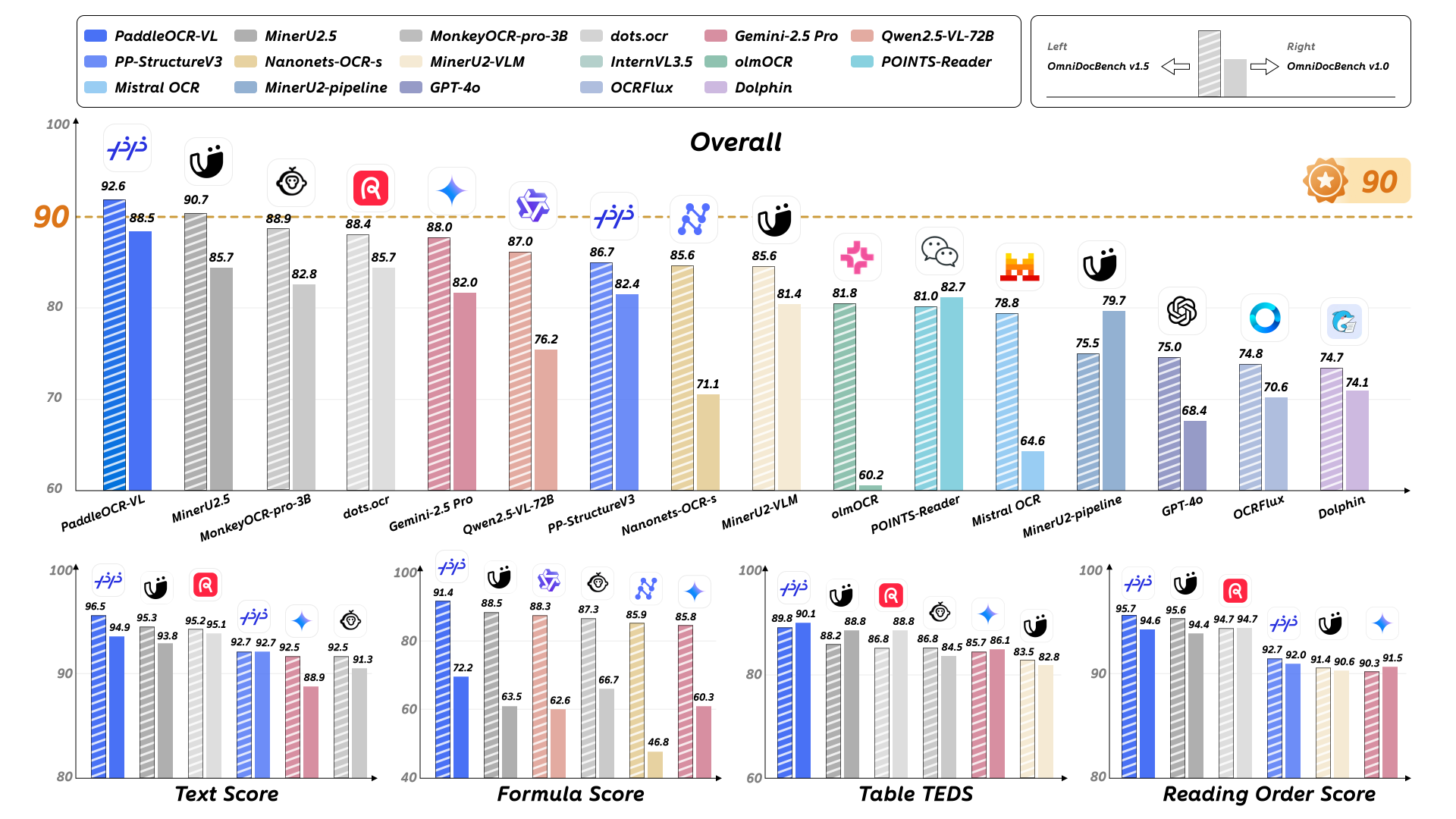
核心特点
-
轻量高效:PaddleOCR-VL-0.9B 采用紧凑而强大的视觉语言模型(VLM)架构,融合了 NaViT 风格的动态高分辨率视觉编码器与轻量级 ERNIE-4.5-0.3B 语言模型,在保持高精度的同时显著降低计算开销,推理速度在 A100 上可达 每秒 1881 个 Token,较同类开源方案提升显著。
-
多元素精准识别:模型可精准识别文档中的文本、手写汉字、表格、数学公式、图表等多种复杂元素,尤其擅长处理历史文档、手写内容等挑战性场景。
-
两阶段解析流程:
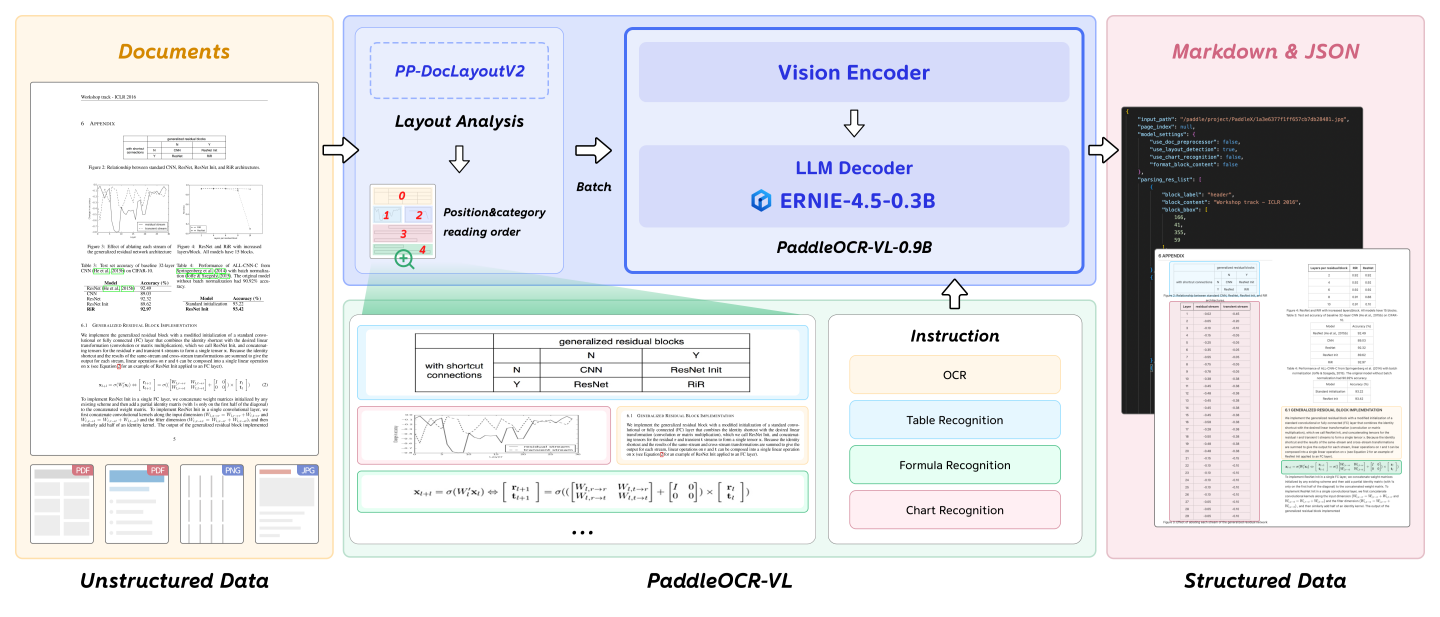
- 版面分析阶段:由 PP-DocLayoutV2 模块完成,负责定位文档中的语义区域并预测阅读顺序;
- 细粒度识别阶段:由 PaddleOCR-VL-0.9B 对各区域内容进行多模态理解与识别。
最终输出结构化的 Markdown 与 JSON 格式,便于下游应用直接使用。
-
全球化语言支持:支持 109 种语言的文字识别,涵盖拉丁文、西里尔文、阿拉伯文、天城文、泰米尔文、泰卢固文等多种书写系统,适用于国际化文档处理场景。
模型架构
应用价值
PaddleOCR-VL 不仅在学术评测中表现卓越,更注重实际部署效率与产业落地能力,可广泛应用于金融票据识别、政务档案数字化、教育资料结构化、跨境多语种文档处理等场景,是大模型时代文档智能处理的关键基础设施。
开源与体验
- 开源地址:https://github.com/PaddlePaddle/PaddleOCR
- 技术报告:PaddleOCR-VL Technical Report
- 在线 Demo:https://aistudio.baidu.com/application/detail/98365
一、快速上手PaddleOCR-VL
1.环境要求
- GPU: 支持CUDA 12.3+的显卡(推荐A100、A800、4090)
- CUDA: >= 12.3
- CUDNN: >= 9.5
- Python: >= 3.10
- 内存: >= 16GB(推荐32GB)
当前仅支持可构建 bfloat16 模型的显卡,例如A100、A800、4090等,在星河社区直接上A800就好了
2.基础环境
# 检查CUDA版本
!nvidia-smi
# 检查Python版本
!python --version
3. 安装依赖
In [1]
%%capture
# 安装PaddlePaddle GPU版本
!python -m pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
# 安装safetensors预编译包
!python -m pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whl
# 安装 PaddleX 的 ocr 可选依赖
!pip install "paddlex[ocr]"In [2]
%%capture
# 卸载环境中原本的 PaddleOCR ,否则会出现找不到 PaddleOCRVL 的问题。
!pip uninstall paddleocr -yIn [3]
# 安装PaddleOCR。第一次推荐直接从GitHub安装
# !git clone https://github.com/PaddlePaddle/PaddleOCR.git PaddleOCR-main
# %cd PaddleOCR-main
# !pip install -e .In [4]
%%capture
# 如果下载太慢,可以先下载到本地,再上传到服务器上安装
%cd PaddleOCR-main
!export SETUPTOOLS_SCM_PRETEND_VERSION_FOR_PADDLEOCR=3.3.0 && pip install -e .In [5]
%cd ../home/aistudio
4.基本用法
In [6]
!export LD_LIBRARY_PATH=/usr/local/cuda-12.6/compat:$LD_LIBRARY_PATHIn [2]
# PaddleOCR-VL基础使用
import logging
logging.getLogger("ppocr").setLevel(logging.ERROR)
logging.getLogger("paddlex").setLevel(logging.ERROR)
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL()
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png")
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")Connecting to https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png ... Downloading paddleocr_vl_demo.png ... [==================================================] 100.00%
二、项目核心功能详解
1. 智能文档解析系统
📄 OCR文档识别引擎
# 核心功能:多元素精准识别
- 文本内容提取:识别中英文混合文本,保持段落结构
- 表格识别:自动转换表格为结构化数据
- 公式检测:识别数学公式区域并生成图片容器
- 图片提取:优化图片质量并自动调整尺寸
- 版面分析:智能分析文档布局和阅读顺序
🔧 处理流程详解
1.1:PDF文档输入
- 支持本地PDF文件处理
- 自动分页处理,支持多页文档
- 文件存在性验证和错误处理
1.2:PaddleOCR-VL智能识别
# 初始化识别管道
pipeline = PaddleOCRVL()
output = pipeline.predict("your_document.pdf")
# 输出包含:
# - 文本内容(带格式标记)
# - 表格数据(结构化)
# - 公式位置信息
# - 图片区域数据
1.3:Markdown格式生成与后处理
# 多页面内容合并
markdown_texts = self.pipeline.concatenate_markdown_pages(markdown_list)
# 公式后处理 - 生成结构化容器
formula_placeholder = """
<div class="formula-container">
<div class="formula-label">公式 {formula_id}</div>
<div class="formula-image">

</div>
<div class="formula-latex">
<code>\[公式识别中...\]</code>
</div>
</div>
"""
1.4:图片优化与输出
# 图片质量优化处理
- 自动RGB模式转换
- 智能尺寸缩放(最大1200×1600像素)
- 对比度自动增强
- 锐化滤镜处理
- JPEG高质量压缩(quality=95)
1.5:完整文档生成
- 分页Markdown文件保存
- JSON格式识别结果导出
- 完整文档合并输出
- 图片资源统一管理
In [3]
# 运行完整的OCR处理流程
print("🔄 开始完整文档处理...")
!python ./work/ocr.py🔄 开始完整文档处理... 🚀 初始化OCR处理器... 开始处理文档: ./work/竞赛论文的辅助自动评阅.pdf OCR识别完成,共处理 11 页 处理第 1 页... 处理第 2 页... 处理第 3 页... 处理第 4 页... 处理第 5 页... 处理第 6 页... 处理第 7 页... 处理第 8 页... 处理第 9 页... 处理第 10 页... 处理第 11 页... ✅ 已保存优化图片: imgs/img_in_image_box_286_691_934_1173.jpg ✅ 已保存优化图片: imgs/img_in_image_box_262_610_998_1065.jpg ✅ 已保存优化图片: imgs/img_in_image_box_229_646_1030_690.jpg ✅ 已保存优化图片: imgs/img_in_image_box_218_149_1053_570.jpg ✅ 已保存优化图片: imgs/img_in_image_box_196_885_992_1469.jpg ✅ 已保存优化图片: imgs/img_in_image_box_190_156_1002_661.jpg ✅ 已保存优化图片: imgs/img_in_image_box_197_786_991_1309.jpg ✅ 处理完成! 📄 完整Markdown文档已保存到: output/完整文档.md 🎉 文档处理成功! 📄 主文件: output/完整文档.md
1.6:LaTeX格式分析
# 分析目标LaTeX模板格式
analyzer = LaTeXFormatAnalyzer(api_key, base_url)
format_config = analyzer.analyze_file("template.tex")
# 分析内容包括:
# - 文档类设置
# - 包依赖分析
# - 字体和页面设置
# - 标题格式规范
# - 图表处理规则
输出示例
{
"source_file": "./work/data.tex",
"content_length": 15317,
"analysis_timestamp": "2025-10-22 20:19:57.299612",
"format_analysis": {
"document_class": {
"class": "IEEEtran",
"options": [
"conference"
],
"description": "专为IEEE会议论文设计的文档类,采用双栏布局,符合IEEE出版规范。"
},
"packages": [
{
"name": "cite",
"purpose": "增强引用功能,支持压缩和排序参考文献编号(如 [1]–[3])。"
},
{
"name": "amsmath, amssymb, amsfonts",
"purpose": "提供高级数学公式排版支持,包括多行公式、特殊符号和字体。"
},
{
"name": "algorithmic",
"purpose": "用于编写伪代码或算法描述。"
},
{
"name": "graphicx",
"purpose": "插入和管理图像文件(如PNG、PDF等),支持缩放、旋转等操作。"
},
{
"name": "textcomp",
"purpose": "提供额外的文本符号,如度数符号(°)、版权符号(©)等。"
},
{
"name": "xcolor",
"purpose": "支持彩色文本与背景,示例中用于红色警告信息。"
}
],
"font_settings": {
"font_family": "默认使用TeX字体(Computer Modern)",
"font_size": "根据IEEEtran标准自动设置:正文通常为10pt",
"figure_labels": {
"size": "8 point",
"font": "Times New Roman",
"note": "建议在图形标签中使用完整单词而非符号"
}
},
"line_spacing_and_paragraphs": {
"line_spacing": "单倍行距(由IEEEtran类固定)",
"paragraph_indent": "标准段落缩进(约5–10pt)",
"paragraph_spacing": "段间无额外空行,通过缩进区分段落",
"justification": "两端对齐(justified)"
},
"title_and_author_formatting": {
"title_style": {
"alignment": "居中",
"font_weight": "粗体",
"size": "较大字号(约14–16pt)",
"subtitle_note": "副标题用脚注小字标注,且注明不被Xplore收录"
},
"author_block": {
"layout": "横向排列作者,换行继续;最多支持六位作者",
"format": "\\IEEEauthorblockN 和 \\IEEEauthorblockA 宏包命令组织姓名与单位",
"affiliation": "单位信息分行列出,包含部门、机构、城市、国家和邮箱/ORCID"
},
"thanks_footnote": "第一作者脚注用于资助声明,可删除若无资金支持"
},
"page_layout": {
"columns": "双栏(two-column)",
"paper_size": "标准美式信纸(8.5×11英寸)或A4(取决于打印机设置)",
"margins": "由IEEEtran严格定义,顶部边距较大以适应整本会议录的装订",
"column_width": "约3.39英寸(86mm)",
"gutter": "栏间距适中,确保可读性",
"override_lockout": "\\IEEEoverridecommandlockouts 允许修改某些受限命令(如脚注样式)"
},
"section_headings": {
"level_1": {
"style": "大写罗马数字(I, II, III...)+ 标题文本",
"font": "粗体",
"size": "12–14pt",
"alignment": "左对齐"
},
"level_2": {
"style": "大写字母后加句点(A., B.)",
"font": "粗体",
"size": "稍小于一级标题"
},
"level_3": {
"style": "阿拉伯数字加括号(1), 2))或斜体首字母大写",
"font": "斜体或粗体斜体"
},
"unnumbered_sections": {
"examples": [
"Acknowledgment",
"References"
],
"command": "\\section*{}",
"note": "这些部分不会出现在目录中(如果生成的话)"
}
},
"abstract_and_keywords": {
"abstract": {
"position": "位于标题下方,双栏之上",
"style": "单栏宽度,无缩进,紧跟标题",
"content_warning": "不得包含数学、符号、脚注或特殊字符"
},
"keywords": {
"environment": "IEEEkeywords",
"position": "紧接摘要之后",
"format": "逗号分隔的关键词列表"
}
},
"figures_and_tables": {
"placement": {
"preferred": "置于栏顶或栏底([htbp]选项)",
"avoid": "避免中间插入(mid-page)",
"wide": "跨栏图表使用\\begin{figure*}或\\begin{table*}"
},
"captions": {
"figure": "位于图下方,格式:Fig.~\\ref{}",
"table": "位于表上方,使用\\caption{}命令"
},
"labeling_rules": {
"axis_labels": "使用全称而非缩写(如'Magnetization'而非'M')",
"units": "放在括号内,如'Temperature (K)'",
"prohibited": "禁止仅用单位或比值作为标签(如'Temperature/K')"
},
"footnotes_in_tables": {
"marker_type": "上标字母(a, b, c)",
"placement": "表格底部说明"
}
},
"mathematical_equations": {
"numbering": "连续编号,右对齐",
"environments_used": [
"equation",
"align",
"IEEEeqnarray"
],
"discouraged": "eqnarray(因间距问题)",
"referencing": "使用\\eqref{eq}生成带圆括号的引用(如(1))",
"symbol_formatting": {
"roman_symbols": "斜体(表示变量)",
"greek_symbols": "正体(除非是变量)",
"constants": "正体(如π应为\\pi)"
},
"punctuation": "公式作为句子一部分时需加逗号或句号",
"best_practices": [
"减号使用长破折号(--)",
"避免\\nonumber滥用",
"\\label应放在\\caption之后"
]
},
"citations_and_references": {
"citation_style": "数字方括号格式,如[1], [2]–[4]",
"punctuation_rule": "标点位于引用之后,如“as shown in [1].”",
"cross_reference": "推荐使用\\cite{key}软引用,便于重组内容",
"reference_list": {
"environment": "thebibliography",
"numbering": "按出现顺序编号,前导零预留空间({00})",
"author_display": "少于六位作者全部列出,超过则可用et al.",
"unpublished_papers": "标注为'unpublished'或'in press'",
"translated_journals": "先英文后原文引用",
"title_capitalization": "仅首词及专有名词大写"
},
"footnotes": {
"numbering": "独立于引用的上标数字",
"placement": "所在栏底部",
"restriction": "不得出现在摘要或参考文献中"
}
},
"special_notes_and_warnings": {
"template_text_removal": {
"warning_color": "红色文字提醒删除模板指导语",
"consequence": "未删除可能导致论文不予发表"
},
"language_consistency": "建议使用美式英语拼写(如acknowledgment)",
"common_errors": [
"data为复数",
"μ₀下标为数字0非字母o",
"et al.无句点在et后",
"i.e.与e.g.正确使用",
"affect/effect等同音异义词区分"
]
},
"overall_document_structure": {
"required_elements": [
"\\maketitle",
"abstract",
"IEEEkeywords",
"sections with hierarchical headings",
"references"
],
"recommended_workflow": "先撰写内容,再进行格式化;图文分离处理"
}
}
}
In [4]
# 分析LaTeX格式要求,需要在latex_format_analyzer.py的第172行填入自己的令牌
print("📊 分析LaTeX格式要求...")
!python ./work/latex_format_analyzer.py📊 分析LaTeX格式要求...
=== LaTeX格式分析器 ===
开始分析LaTeX文件: ./work/data.tex
LaTeX文件读取成功,文档长度: 15317 字符
将使用单次分析处理
格式分析完成,正在解析结果...
分析结果已保存到: output/latex_format_analysis_data.json
=== LaTeX格式分析完成 ===
源文件: ./work/data.tex
文档长度: 15317 字符
分析时间: 2025-10-29 15:52:31.146536
格式分析结果:
{
"文档类和基本设置": {
"文档类": "\\documentclass[conference]{IEEEtran}",
"说明": "使用IEEEtran文档类,conference选项用于会议论文格式。"
},
"使用的包及其作用": [
{
"包名": "cite",
"作用": "用于管理参考文献的引用。"
},
{
"包名": "amsmath, amssymb, amsfonts",
"作用": "提供数学公式、符号和字体的扩展支持。"
},
{
"包名": "algorithmic",
"作用": "用于排版算法伪代码。"
},
{
"包名": "graphicx",
"作用": "提供对图形插入和处理的支持。"
},
{
"包名": "textcomp",
"作用": "提供额外的文本符号支持。"
},
{
"包名": "xcolor",
"作用": "提供颜色支持。"
}
],
"页面设置": {
"页边距": "未明确设置,使用IEEEtran文档类的默认设置。",
"纸张大小": "未明确设置,使用IEEEtran文档类的默认设置。"
},
"字体设置": {
"字体族": "未明确设置,使用IEEEtran文档类的默认字体。",
"字号": "未明确设置,使用IEEEtran文档类的默认字号。"
},
"行间距设置": {
"说明": "未明确设置,使用IEEEtran文档类的默认行间距。"
},
"标题格式": {
"一级标题": {
"命令": "\\section",
"样式": "使用IEEEtran文档类的默认一级标题样式。"
},
"二级标题": {
"命令": "\\subsection",
"样式": "使用IEEEtran文档类的默认二级标题样式。"
}
},
"段落格式": {
"缩进": "未明确设置,使用IEEEtran文档类的默认段落缩进。",
"间距": "未明确设置,使用IEEEtran文档类的默认段落间距。"
},
"图表格式设置": {
"表格": {
"环境": "table",
"示例": "\\begin{table}[htbp] ... \\end{table}",
"说明": "表格环境,支持表格标题和脚注。"
},
"图形": {
"环境": "figure",
"示例": "\\begin{figure}[htbp] ... \\end{figure}",
"说明": "图形环境,支持图形插入和标题。"
}
},
"数学公式格式": {
"行内公式": "使用 $...$ 或 \\(...\\)",
"行间公式": "使用 equation 环境,示例:\\begin{equation} ... \\end{equation}",
"说明": "支持amsmath包提供的扩展数学公式环境。"
},
"参考文献格式": {
"环境": "thebibliography",
"示例": "\\begin{thebibliography}{00} ... \\end{thebibliography}",
"说明": "使用数字编号的参考文献格式,支持方括号引用。"
},
"其他重要的格式设置": {
"作者和单位": {
"命令": "\\IEEEauthorblockN, \\IEEEauthorblockA",
"说明": "用于排版作者姓名和单位信息。"
},
"关键词": {
"环境": "IEEEkeywords",
"示例": "\\begin{IEEEkeywords} ... \\end{IEEEkeywords}",
"说明": "用于排版论文关键词。"
},
"摘要": {
"环境": "abstract",
"示例": "\\begin{abstract} ... \\end{abstract}",
"说明": "用于排版论文摘要。"
},
"致谢": {
"命令": "\\section*{Acknowledgment}",
"说明": "用于排版致谢部分,不编号。"
}
}
}
1.7:大模型智能转换
def segment_markdown_content(markdown_content, max_chars=MAX_CHARS_PER_SEGMENT, overlap=SEGMENT_OVERLAP):
"""
将Markdown内容分段处理
Args:
markdown_content: Markdown文档内容
max_chars: 每个分段的最大字符数
overlap: 分段之间的重叠字符数
Returns:
list: 分段后的Markdown内容列表
"""
content_length = len(markdown_content)
# 如果内容长度小于等于最大分段长度,直接返回
if content_length <= max_chars:
print(f"文档长度 {content_length} 字符,无需分段")
return [markdown_content]
print(f"文档长度 {content_length} 字符,超过 {max_chars} 字符限制,开始分段处理...")
segments = []
start_pos = 0
while start_pos < content_length:
# 计算当前分段的结束位置
end_pos = min(start_pos + max_chars, content_length)
# 如果不是最后一个分段,尝试在合适的位置断开
if end_pos < content_length:
# 寻找合适的分段点(段落结束、章节结束等)
segment_content = markdown_content[start_pos:end_pos]
# 定义分段点优先级(从高到低)
break_points = [
(r'\n## ', 1.0), # 二级标题 - 最高优先级
(r'\n### ', 0.9), # 三级标题
(r'\n#### ', 0.8), # 四级标题
(r'\n\n', 0.7), # 段落分隔
(r'\n', 0.6), # 行分隔
]
best_break_pos = end_pos
best_priority = 0.0
# 寻找最佳分段点
for pattern, priority in break_points:
matches = list(re.finditer(pattern, segment_content))
if matches:
# 从后往前找,优先选择靠后的分段点
for match in reversed(matches):
break_pos = start_pos + match.end()
# 确保分段不会太小(至少是最大长度的60%)
min_size = max_chars * 0.6
if break_pos > start_pos + min_size:
# 如果优先级更高,或者优先级相同但位置更靠后,则更新
if priority > best_priority or (priority == best_priority and break_pos > best_break_pos):
best_break_pos = break_pos
best_priority = priority
end_pos = best_break_pos
# 提取当前分段
current_segment = markdown_content[start_pos:end_pos]
segments.append(current_segment)
print(f"分段 {len(segments)}: 位置 {start_pos}-{end_pos} ({end_pos - start_pos} 字符)")
# 计算下一个分段的开始位置
# 动态计算重叠,确保不遗漏内容
if len(segments) > 1:
# 计算实际重叠长度
actual_overlap = min(overlap, end_pos - start_pos)
# 下一个分段的开始位置 = 当前结束位置 - 重叠长度
next_start = end_pos - actual_overlap
else:
# 第一个分段后,使用固定步长
next_start = start_pos + max_chars - overlap
# 确保下一个开始位置不会倒退,但也不能超过当前结束位置
start_pos = max(next_start, start_pos + 1)
# 如果下一个开始位置已经达到或超过当前结束位置,说明没有遗漏
if start_pos >= end_pos:
start_pos = end_pos
# 防止无限循环的安全检查
if start_pos >= content_length:
break
# 防止分段过小
remaining_chars = content_length - start_pos
if remaining_chars < max_chars * 0.3:
# 如果剩余内容太少,直接作为最后一个分段
if remaining_chars > 0:
final_segment = markdown_content[start_pos:]
segments.append(final_segment)
print(f"分段 {len(segments)}: 位置 {start_pos}-{content_length} ({remaining_chars} 字符) [最后分段]")
break
print(f"分段完成,共生成 {len(segments)} 个分段")
return segments
1.8:LaTeX编译输出(目前最后一部分输出pdf需要依赖本地latex环境,有兴趣的大佬可以在本地运行试试)
- 生成完整的.tex源文件
- 自动编译为PDF格式
- 支持中文排版和数学公式
In [5]
# 执行Markdown到LaTeX的转换,需要在improved_latex_converter.py的第10行填入自己的令牌
print("🤖 执行大模型转换...")
!python ./work/improved_latex_converter.py🤖 执行大模型转换... [步骤1] 加载 LaTeX 结构配置... [步骤2] 加载 Markdown 文档... [步骤3] 检查文档长度并决定处理方式... 文档长度: 9233 字符 文档超过 5000 字符,将使用分段处理 开始分段转换Markdown文档... 文档长度 9233 字符,超过 5000 字符限制,开始分段处理... 分段 1: 位置 0-3802 (3802 字符) 分段 2: 位置 3802-8460 (4658 字符) 分段 3: 位置 8260-9233 (973 字符) [最后分段] 分段完成,共生成 3 个分段 正在转换第 1/3 个分段... 第 1 段转换成功 正在转换第 2/3 个分段... 第 2 段转换成功 正在转换第 3/3 个分段... 第 3 段转换成功 正在合并分段转换结果... [步骤4] 保存为 .tex 文件... [完成] 已保存到 output/output.tex [步骤5] 编译LaTeX为PDF... [编译] 正在编译 output/output.tex 为PDF... [错误] 未找到pdflatex命令,请确保已安装LaTeX 建议安装: MiKTeX (Windows) 或 TeX Live (Linux/Mac) [⚠️ 部分完成] LaTeX文件已生成,但PDF编译失败 请手动编译: pdflatex output/output.tex
2. 实际应用案例
🎓 学术论文格式化
场景:将草稿论文转换为会议格式
# 输入:自由格式的PDF论文
# 输出:符合IEEE会议标准的LaTeX
input_file = "draft_paper.pdf"
target_format = "IEEE_conference"
formatter = PaperFormatter()
result = formatter.convert_to_format(input_file, target_format)
# 生成:
# - IEEEtran格式的.tex文件
# - 编译后的PDF
# - 格式检查报告
📝 期刊投稿准备
场景:调整论文格式满足期刊要求
# 支持多种期刊格式
journal_formats = {
"IEEE": "ieee_journal_format",
"Springer": "springer_lncs"
}
selected_format = journal_formats["Nature"]
result = formatter.convert_to_format("my_research.pdf", selected_format)
三、 结果展示
为验证系统在复杂学术文档处理上的能力,我们选取了一篇包含数学公式、表格、插图等多种元素的 PDF 论文作为原始输入,并展示了从原始文档到最终 LaTeX 输出的完整处理流程:
-
原始 PDF 文档
包含复杂的排版结构,如多栏布局、嵌入式图表和 数学公式。
-
大模型结构分析模板(标准示例)
大模型对论文逻辑结构(如标题、摘要、章节、参考文献等)的自动识别与解析效果。
-
最终生成的 LaTeX 文档
输出结果严格遵循 IEEE 会议论文格式规范,可直接用于投稿,无需手动调整格式或修改内容。
总结
本项目为学术工作者提供了一个端到端的智能论文格式化解决方案,从原始 PDF 文档到符合出版标准的 LaTeX 格式,全程自动化处理。
PaddleOCR-VL 凭借其轻量高效(仅 0.9B 参数)却性能卓越的架构,不仅能精准识别复杂版面中的文本、公式、表格与图表,还支持 109 种语言,在学术文档解析任务中展现出远超同类模型的泛化能力。正是得益于 PaddleOCR-VL 强大的识别能力,本项目才能实现高保真、高效率的格式转换,真正让技术服务于科研。
无论您是:
- 🎓 研究生:准备学位论文
- 👨🔬 研究人员:投稿学术期刊
- 📚 学生:完成课程论文
- 🏆 竞赛参与者:提交规范格式作品
都能通过这个系统大幅提升文档准备效率,告别繁琐的手动排版,专注于内容创作本身。


















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











