




【ERNIE&PaddleOCR】ChatOffice:多模态 RAG 智能文档问答系统
1. 项目介绍与环境配置
1.1 项目背景
本项目是一个基于 多模态 RAG(Retrieval-Augmented Generation) 技术的智能文档问答系统。它能够处理多种格式的文档(PPT、PDF、Word、Excel、图片、文本等),将其转换为可检索的向量表示,并通过ERNIE-4.5-VL-28B-A3B回答用户的问题。
1.2 核心技术栈
- 百度 AI Studio:提供文本嵌入模型(
embedding-v1,bge-large-zh)和视觉大模型(ERNIE-4.5-VL-28B-A3B) - PaddleOCR-VL:本地运行的多模态 OCR 模型,支持文字、表格、图表识别
- LlamaIndex:构建 RAG 应用的框架,提供文档加载、向量存储、检索等功能
- ChromaDB:高性能向量数据库,用于存储和检索文档嵌入
- 纯 Python 文档处理:使用
python-pptx,python-docx,openpyxl,pypdfium2等库实现文档转图片
1.3 应用场景
- 企业知识库问答
- 研究报告分析
- 多文档对比与信息提取
- 智能文档助手
In [ ]
%cd /home/aistudio/chatoffice
# 安装PaddleOCR的相关依赖
!python -m pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whl
# 卸载原有paddleocr
!pip uninstall paddleocr -y
# 安装最新版的PaddleOCR==3.3.0(源码安装)
%cd /home/aistudio/
!unzip PaddleOCR-3.3.0.zip
%cd /home/aistudio/PaddleOCR-3.3.0
!export SETUPTOOLS_SCM_PRETEND_VERSION_FOR_PADDLEOCR=3.3.0 && pip install -e .
%cd /home/aistudio/chatoffice
In [9]
import os
# 设置 AI Studio API Key
os.environ["AI_STUDIO_API_KEY"] = "*********************************"
In [ ]
import os
import sys
from pathlib import Path
print("=" * 60)
print("环境信息检查")
print("=" * 60)
print(f"Python 版本: {sys.version.split()[0]}")
print(f"工作目录: {os.getcwd()}")
print()
required_env_vars = ["AI_STUDIO_API_KEY"]
print("环境变量检查:")
all_ok = True
for var in required_env_vars:
value = os.getenv(var)
if value:
masked_value = value[:8] + "..." if len(value) > 8 else "***"
print(f" ✓ {var}: {masked_value}")
else:
print(f" ✗ {var}: 未设置")
all_ok = False
if not all_ok:
print("\n⚠️ 请设置缺失的环境变量!")
print("在 .env 文件中添加:")
print(" AI_STUDIO_API_KEY=your_key_here")
else:
print("\n✓ 所有必需的环境变量已正确配置")
print("=" * 60)
In [11]
sys.path.insert(0, str(Path.cwd() / "src"))
print("导入项目模块...")
try:
from document_detector import DocumentDetector
from document_converter import DocumentConverter
from paddleocr_parser import PaddleOCRParser
from aistudio_embedding import AIStudioEmbedding
from aistudio_vision_llm import AIStudioVisionLLM
from text_document_parser import TextDocumentParser
from multi_doc_rag_engine import MultiDocRAGEngine
print("✓ 所有模块导入成功!")
print("\n已导入的模块:")
print(" - DocumentDetector: 文档类型检测")
print(" - DocumentConverter: 文档转图片")
print(" - PaddleOCRParser: OCR 解析")
print(" - AIStudioEmbedding: 文本嵌入")
print(" - AIStudioVisionLLM: 视觉大模型")
print(" - TextDocumentParser: 文本解析")
print(" - MultiDocRAGEngine: RAG 引擎")
except ImportError as e:
print(f"✗ 模块导入失败: {e}")
print("请确保已正确安装所有依赖")
导入项目模块...
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm
✓ 所有模块导入成功! 已导入的模块: - DocumentDetector: 文档类型检测 - DocumentConverter: 文档转图片 - PaddleOCRParser: OCR 解析 - AIStudioEmbedding: 文本嵌入 - AIStudioVisionLLM: 视觉大模型 - TextDocumentParser: 文本解析 - MultiDocRAGEngine: RAG 引擎
2. 文档类型检测器 (DocumentDetector)
2.1 技术原理
DocumentDetector 是文档处理流程的第一步,负责自动识别文档的类型。它采用双重检测机制:
- 扩展名检测:首先检查文件扩展名(如
.pptx,.pdf,.docx) - MIME 类型检测:如果扩展名无法识别,则通过 MIME 类型进行二次判断
这种设计确保了即使文件扩展名不标准或缺失,系统仍能正确识别文档类型。
2.2 支持的文档格式
| 类型 | 扩展名 | 说明 |
|---|---|---|
| PPT | .ppt, .pptx | PowerPoint 演示文稿 |
.pdf | PDF 文档 | |
| Word | .doc, .docx | Word 文档 |
| Excel | .xls, .xlsx | Excel 表格 |
| 图片 | .png, .jpg, .jpeg, .gif, .bmp | 图片文件 |
| Markdown | .md, .markdown | Markdown 文档 |
| 文本 | .txt | 纯文本文件 |
2.3 核心方法
detect(file_path): 检测文件类型,返回类型字符串is_supported(file_path): 判断文件是否被支持get_supported_formats(): 获取所有支持的格式字典
In [12]
detector = DocumentDetector()
print("=" * 60)
print("文档类型检测器示例")
print("=" * 60)
supported_formats = detector.get_supported_formats()
print("\n支持的文档格式:")
for doc_type, extensions in supported_formats.items():
print(f" {doc_type:10s}: {', '.join(extensions)}")
print("\n" + "=" * 60)
============================================================ 文档类型检测器示例 ============================================================ 支持的文档格式: ppt : .ppt, .pptx pdf : .pdf word : .doc, .docx excel : .xls, .xlsx image : .png, .jpg, .jpeg, .gif, .bmp markdown : .md, .markdown text : .txt ============================================================
In [13]
test_files = [
"data/PaddleOCR-VL_Technical_Report.pdf",
"data/中文大模型基准测评2025年3月报告.pptx",
"README.md",
"pyproject.toml"
]
print("批量检测文档类型:\n")
for file_path in test_files:
if Path(file_path).exists():
doc_type = detector.detect(file_path)
is_supported = detector.is_supported(file_path)
status = "✓ 支持" if is_supported else "✗ 不支持"
print(f"文件: {Path(file_path).name:40s}")
print(f" 类型: {doc_type:10s} 状态: {status}\n")
else:
print(f"文件: {Path(file_path).name:40s}")
print(f" 状态: 文件不存在\n")
Unknown format: .toml, treating as text Unknown format: .toml, treating as text
批量检测文档类型: 文件: PaddleOCR-VL_Technical_Report.pdf 类型: pdf 状态: ✓ 支持 文件: 中文大模型基准测评2025年3月报告.pptx 类型: ppt 状态: ✓ 支持 文件: README.md 类型: markdown 状态: ✓ 支持 文件: pyproject.toml 类型: text 状态: ✓ 支持
3. 文档转换器 (DocumentConverter)
3.1 技术原理
DocumentConverter 负责将各种格式的文档转换为图片,这是整个系统的关键步骤。本项目采用纯 Python 实现,无需依赖 LibreOffice 等外部工具,提高了部署的灵活性和可移植性。
3.2 转换流程
不同文档类型采用不同的转换策略:
| 文档类型 | 转换库 | 转换流程 |
|---|---|---|
| PPT/PPTX | python-pptx | 解析幻灯片结构 → 提取文本和图片 → 使用 PIL 渲染为图片 |
| Word | python-docx | 解析段落和表格 → 文本排版 → PIL 渲染多页图片 |
| Excel | openpyxl | 读取单元格数据 → 绘制表格网格 → PIL 渲染为图片 |
pypdfium2 | 直接将 PDF 页面渲染为图片 | |
| 文本/MD | 内置 | 读取文本内容 → 自动换行排版 → PIL 渲染为图片 |
3.3 缓存机制
系统使用基于文件哈希的智能缓存:
- 计算文件内容的 MD5 哈希值
- 检查缓存目录中是否存在对应哈希的转换结果
- 如果存在则直接返回,否则执行转换并缓存结果
这大大提高了重复处理同一文档的效率。
In [ ]
import time
converter = DocumentConverter()
print("=" * 60)
print("文档转换器示例 - PPT 转图片")
print("=" * 60)
ppt_file = "data/中文大模型基准测评2025年3月报告.pptx"
if Path(ppt_file).exists():
print(f"\n正在转换: {Path(ppt_file).name}")
print("第一次转换(无缓存)...")
start_time = time.time()
images = converter.to_images(ppt_file, "ppt")
elapsed = time.time() - start_time
print(f" 转换完成!")
print(f" 生成图片数: {len(images)}")
print(f" 耗时: {elapsed:.2f} 秒")
if images:
print(f"\n转换后的图片路径示例:")
for i, img_path in enumerate(images[:3], 1):
print(f" {i}. {img_path}")
if len(images) > 3:
print(f" ... 还有 {len(images) - 3} 张图片")
print("\n第二次转换(使用缓存)...")
start_time = time.time()
images_cached = converter.to_images(ppt_file, "ppt")
elapsed_cached = time.time() - start_time
print(f" 转换完成!")
print(f" 生成图片数: {len(images_cached)}")
print(f" 耗时: {elapsed_cached:.2f} 秒")
print(f" 加速比: {elapsed / max(elapsed_cached, 0.001):.1f}x")
else:
print(f"\n文件不存在: {ppt_file}")
print("\n" + "=" * 60)
4. PaddleOCR-VL 文档解析器
4.1 技术原理
PaddleOCRParser 封装了 PaddleOCR-VL,PaddleOCR-VL: 是一款先进、高效的文档解析模型,专为文档中的元素识别设计。其核心组件为 PaddleOCR-VL-0.9B,这是一种紧凑而强大的视觉语言模型(VLM),它由 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型组成,能够实现精准的元素识别。该模型支持 109 种语言,并在识别复杂元素(如文本、表格、公式和图表)方面表现出色,同时保持极低的资源消耗。通过在广泛使用的公开基准与内部基准上的全面评测,PaddleOCR-VL 在页级级文档解析与元素级识别均达到 SOTA 表现。它显著优于现有的基于Pipeline方案和文档解析多模态方案以及先进的通用多模态大模型,并具备更快的推理速度。这些优势使其非常适合在真实场景中落地部署。
4.2 功能特性
1.紧凑而强大的 VLM 架构: 我们提出了一种新型的视觉语言模型(Vision-Language Model),专为资源高效的推理而设计,在文档元素解析识别方面表现卓越。通过将 NaViT 风格的动态高分辨率视觉编码器与轻量级的 ERNIE-4.5-0.3B 语言模型相结合,我们显著提升了模型的识别能力和解码效率。这种组合在保持高精度的同时,降低了计算需求,使其非常适合高效且实用的文档处理应用。
2.文档解析的 SOTA 性能: PaddleOCR-VL 在页面级文档解析和元素级识别任务中均达到了SOTA的性能。它显著优于现有的基于多模型组合Pipeline的解决方案,并在文档解析任务中展现出相比于主流视觉-语言模型(VLMs)的极强的竞争力。此外,它在识别复杂文档元素(如文本、表格、公式和图表)方面表现出色,能够适应包括手写文本和历史文档在内的多种复杂内容类型。这使其具有极高的通用性,适用于多种文档类型和使用场景。
3.多语言支持: PaddleOCR-VL 支持 109 种语言,涵盖主要的全球语言,包括但不限于中文、英文、日文、拉丁语和韩语,同时也支持使用不同文字体系和结构的语言,如俄语(西里尔字母)、阿拉伯语、印地语(天城文)以及泰语。这种广泛的语言覆盖极大地提升了我们的整个系统在多语言和全球化文档处理场景中的适用性。
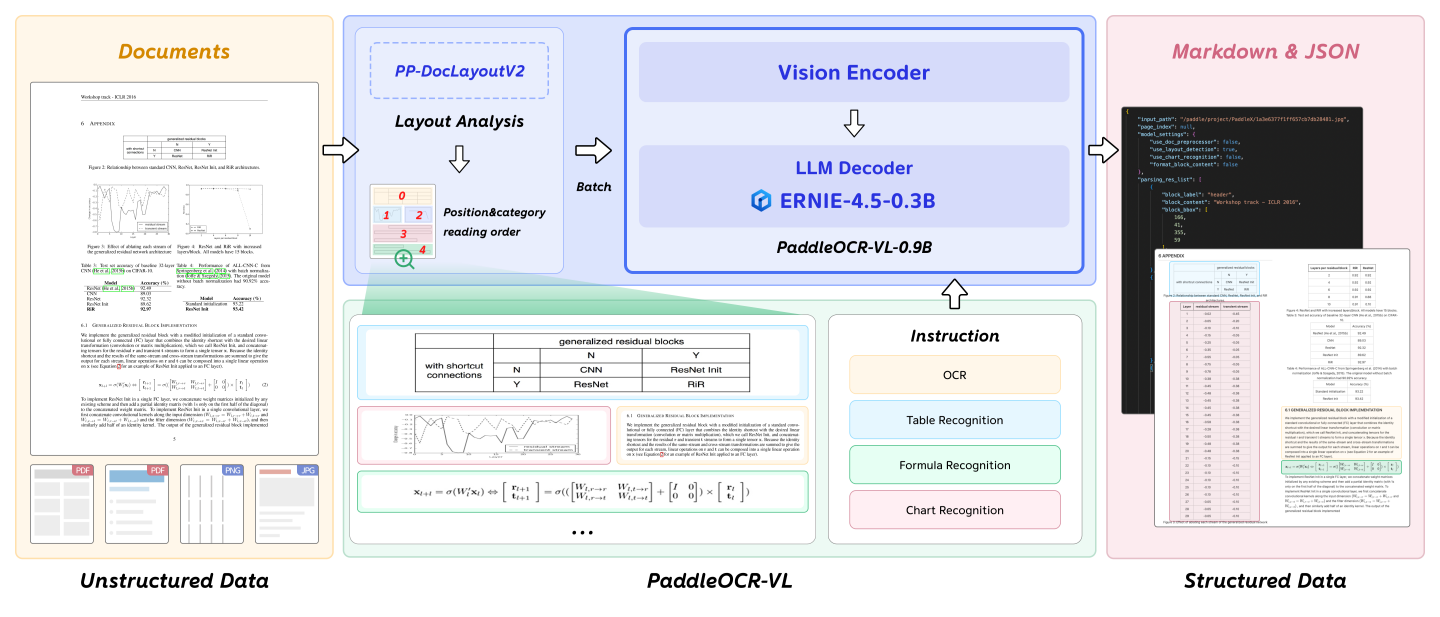
4.3 工作流程
图片输入 → PaddleOCR-VL 分析 → 生成结构化数据 → 保存为 Markdown → 读取并返回
4.4 核心方法
parse_image(image_path): 解析单张图片,返回 Markdown 文本parse_images(image_paths): 批量解析多张图片,返回 Markdown 文本列表
In [ ]
# PaddleOCR-VL实例测试
import logging
logging.getLogger("ppocr").setLevel(logging.ERROR)
logging.getLogger("paddlex").setLevel(logging.ERROR)
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL()
output = pipeline.predict("/home/aistudio/chatoffice/interactive_test_cache/images/PaddleOCR-VL_Technical_Report_ea6a3153527c234a6390a2dbf484cfaf_page_001.jpg")
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")
In [19]
print("=" * 60)
print("PaddleOCR-VL 文档解析器示例")
print("=" * 60)
print("\n初始化 PaddleOCR-VL(首次运行会下载模型)...")
try:
ocr_parser = PaddleOCRParser()
print("✓ PaddleOCR-VL 初始化成功")
if 'images' in locals() and images:
test_image = images[0]
print(f"\n正在解析图片: {Path(test_image).name}")
markdown_result = ocr_parser.parse_image(test_image)
print(f"\n解析结果(前 500 字符):")
print("-" * 60)
print(markdown_result[:500])
if len(markdown_result) > 500:
print(f"\n... 还有 {len(markdown_result) - 500} 字符")
print("-" * 60)
print(f"\n总字符数: {len(markdown_result)}")
else:
print("\n⚠️ 没有可用的图片进行解析")
print("请先运行上一个单元格转换文档")
except Exception as e:
print(f"✗ 初始化或解析失败: {e}")
print("请确保已正确安装 PaddleOCR")
print("\n" + "=" * 60)
Creating model: ('PP-DocLayoutV2', None)
Model files already exist. Using cached files. To redownload, please delete the directory manually: `/home/aistudio/.paddlex/official_models/PP-DocLayoutV2`.
============================================================ PaddleOCR-VL 文档解析器示例 ============================================================ 初始化 PaddleOCR-VL(首次运行会下载模型)...
Creating model: ('PaddleOCR-VL-0.9B', None)
Model files already exist. Using cached files. To redownload, please delete the directory manually: `/home/aistudio/.paddlex/official_models/PaddleOCR-VL`.
Loading configuration file /home/aistudio/.paddlex/official_models/PaddleOCR-VL/config.json
Loading weights file /home/aistudio/.paddlex/official_models/PaddleOCR-VL/model.safetensors
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
use GQA - num_heads: 16- num_key_value_heads: 2
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/utils/decorator_utils.py:420: Warning:
Non compatible API. Please refer to https://www.paddlepaddle.org.cn/documentation/docs/en/develop/guides/model_convert/convert_from_pytorch/api_difference/torch/torch.split.html first.
warnings.warn(
Loaded weights file from disk, setting weights to model.
All model checkpoint weights were used when initializing PaddleOCRVLForConditionalGeneration.
All the weights of PaddleOCRVLForConditionalGeneration were initialized from the model checkpoint at /home/aistudio/.paddlex/official_models/PaddleOCR-VL.
If your task is similar to the task the model of the checkpoint was trained on, you can already use PaddleOCRVLForConditionalGeneration for predictions without further training.
Loading configuration file /home/aistudio/.paddlex/official_models/PaddleOCR-VL/generation_config.json
Currently, the PaddleOCR-VL-0.9B local model only supports batch size of 1. The batch size will be updated to 1.
✓ PaddleOCR-VL 初始化成功 正在解析图片: 中文大模型基准测评2025年3月报告_7b6e53aaffda87f94aef030175fcf7db_slide_001.jpg
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/tensor/creation.py:1088: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach(), rather than paddle.to_tensor(sourceTensor). return tensor( Setting `pad_token_id` to `eos_token_id`:2 for open-end generation. /opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/utils/decorator_utils.py:420: Warning: Non compatible API. Please refer to https://www.paddlepaddle.org.cn/documentation/docs/en/develop/guides/model_convert/convert_from_pytorch/api_difference/torch/torch.max.html first. warnings.warn( Setting `pad_token_id` to `eos_token_id`:2 for open-end generation. Setting `pad_token_id` to `eos_token_id`:2 for open-end generation. Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
解析结果(前 500 字符): ------------------------------------------------------------ ## SuperCLUE 中文大模型综合性测评基准 2025年3月 — 2025 SuperCLUE□□ 2025.03.18 ------------------------------------------------------------ 总字符数: 67 ============================================================
5. AI Studio 文本嵌入 (AIStudioEmbedding)
5.1 技术原理
AIStudioEmbedding 实现了 LlamaIndex 的 BaseEmbedding 接口,集成了百度 AI Studio 提供的文本嵌入模型。文本嵌入是将文本转换为高维向量的过程,相似的文本在向量空间中距离更近。
5.2 支持的模型
| 模型名称 | 特点 | 输入限制 | 批处理 |
|---|---|---|---|
| embedding-v1 | 轻量级,快速 | 384 tokens | 单次处理 |
| bge-large-zh | 高精度,适合中文 | 512 tokens | 批量处理(batch 16) |
5.3 LlamaIndex 集成
通过实现 BaseEmbedding 接口,可以无缝集成到 LlamaIndex 的 RAG 流程中:
_get_query_embedding(query): 为查询生成向量_get_text_embedding(text): 为单个文本生成向量_get_text_embeddings(texts): 批量生成向量(自动分批)
5.4 应用场景
- 文档检索:将文档转换为向量存储,快速检索相关内容
- 语义搜索:基于语义相似度而非关键词匹配
- 聚类分析:将相似文档聚类
In [24]
import numpy as np
print("=" * 60)
print("AI Studio 文本嵌入示例")
print("=" * 60)
try:
embedding_model = AIStudioEmbedding(model="bge-large-zh")
print(f"✓ 嵌入模型初始化成功: {embedding_model.model_name}")
test_query = "什么是人工智能?"
print(f"\n生成查询向量: '{test_query}'")
query_embedding = embedding_model.get_query_embedding(test_query)
print(f" 向量维度: {len(query_embedding)}")
print(f" 向量示例(前 10 维): {query_embedding[:10]}")
test_texts = [
"人工智能是计算机科学的一个分支",
"机器学习是实现人工智能的方法",
"今天天气很好"
]
print(f"\n批量生成文本向量({len(test_texts)} 个文本):")
text_embeddings = []
for text in test_texts:
emb = embedding_model.get_text_embedding(text)
text_embeddings.append(emb)
for i, (text, emb) in enumerate(zip(test_texts, text_embeddings), 1):
print(f" {i}. '{text}'")
print(f" 向量维度: {len(emb)}")
print(f"\n计算语义相似度(余弦相似度):")
query_vec = np.array(query_embedding)
for i, (text, emb) in enumerate(zip(test_texts, text_embeddings), 1):
text_vec = np.array(emb)
similarity = np.dot(query_vec, text_vec) / (np.linalg.norm(query_vec) * np.linalg.norm(text_vec))
print(f" 查询 vs 文本{i}: {similarity:.4f}")
except Exception as e:
print(f"✗ 嵌入模型初始化或使用失败: {e}")
import traceback
traceback.print_exc()
print("请检查 AI_STUDIO_API_KEY 是否正确配置")
print("\n" + "=" * 60)
============================================================
AI Studio 文本嵌入示例
============================================================
✓ 嵌入模型初始化成功: bge-large-zh
生成查询向量: '什么是人工智能?'
向量维度: 1024
向量示例(前 10 维): [0.02191328816115856, -0.025731287896633148, -0.030843475833535194, -0.027107585221529007, 0.005002214573323727, 0.04101301357150078, -0.002339485567063093, -0.02015017159283161, 0.025746241211891174, 0.005108825862407684]
批量生成文本向量(3 个文本):
1. '人工智能是计算机科学的一个分支'
向量维度: 1024
2. '机器学习是实现人工智能的方法'
向量维度: 1024
3. '今天天气很好'
向量维度: 1024
计算语义相似度(余弦相似度):
查询 vs 文本1: 0.8120
查询 vs 文本2: 0.8015
查询 vs 文本3: 0.6538
============================================================
6. AI Studio 视觉 LLM (AIStudioVisionLLM)
6.1 技术原理
AIStudioVisionLLM 封装了百度 AI Studio 的 ERNIE-4.5-VL-28B-A3B 视觉大模型。这是一个多模态大语言模型,能够同时理解图片和文本,实现图文联合推理。
6.2 模型特点
1. 多模态异构 MoE 预训练: 模型在文本和视觉模态上联合训练,以更好地捕捉多模态信息的细微差别,并提高涉及文本理解与生成、图像理解和跨模态推理的任务性能。为了实现这一点而不让一个模态阻碍另一个模态的学习,设计了一种异构 MoE 结构,引入了模态隔离路由,并采用了路由正交损失和多模态标记平衡损失。这些架构选择确保了两种模态都得到有效表示,允许在训练过程中相互强化。
2. 扩展高效基础设施: 提出了一种新颖的同构混合并行和分层负载均衡策略,以高效训练 ERNIE 4.5 模型。通过使用节点内专家并行、内存高效管道调度、FP8 混合精度训练和细粒度重计算方法,实现了显著的预训练吞吐量。对于推理,提出了多专家并行协作方法和卷积码量化算法,以实现 4 位/2 位无损量化。此外,我们引入了 PD 解耦和动态角色切换,以有效利用资源,增强 ERNIE 4.5 MoE 模型的推理性能。基于 PaddlePaddle,ERNIE 4.5 在广泛的硬件平台上实现了高性能推理。
3. 模态特定后训练: 为了满足现实应用的各种需求,对预训练模型的变体进行了特定模态的微调。LLMs 针对通用语言理解和生成进行了优化。VLMs 专注于视觉语言理解,并支持思考和非思考模式。每个模型在后训练中采用了监督微调(SFT)、直接偏好优化(DPO)或名为统一偏好优化(UPO)的改进强化学习方法。
在视觉-语言模型的微调阶段,视觉与语言的深度融合在模型在理解、推理和生成等复杂任务中的性能中起着决定性作用。为了提高模型在多模态任务上的泛化能力和适应性,专注于三个核心能力——图像理解、特定任务微调和多模态思维链推理——并进行了系统性的数据构建和训练策略优化。此外,我们使用 RLVR(可验证奖励的强化学习)来进一步改善对齐和性能。经过 SFT 和 RL 阶段后,获得了 ERNIE-4.5-VL-28B-A3B。
6.3 API 接口
使用 OpenAI 兼容的 API 格式,图片通过 Base64 编码传输:
{
"role": "user",
"content": [
{"type": "text", "text": "请描述这张图片"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,..."}}
]
}
6.4 应用场景
- 文档内容理解:理解 PPT、报告中的图表和图片
- 图片问答:回答关于图片内容的问题
- 多图对比:对比不同图片的异同
In [25]
print("=" * 60)
print("AI Studio 视觉 LLM 示例")
print("=" * 60)
try:
vision_llm = AIStudioVisionLLM()
print(f"✓ 视觉 LLM 初始化成功: {vision_llm.model_name}")
if 'images' in locals() and images:
test_image = images[0]
print(f"\n正在分析图片: {Path(test_image).name}")
prompt = "请简要描述这张图片的主要内容,包括标题、关键文字和视觉元素。"
print(f"提问: {prompt}")
print("\n模型回答:")
print("-" * 60)
response = vision_llm.generate_response(
prompt=prompt,
image_paths=[test_image]
)
print(response)
print("-" * 60)
if len(images) >= 2:
print(f"\n多图对比示例:")
print(f" 图片 1: {Path(images[0]).name}")
print(f" 图片 2: {Path(images[1]).name}")
compare_prompt = "这两张图片有什么相同点和不同点?"
print(f"\n提问: {compare_prompt}")
print("\n模型回答:")
print("-" * 60)
compare_response = vision_llm.generate_response(
prompt=compare_prompt,
image_paths=[images[0], images[1]]
)
print(compare_response)
print("-" * 60)
else:
print("\n⚠️ 没有可用的图片进行分析")
print("请先运行文档转换单元格")
except Exception as e:
print(f"✗ 视觉 LLM 初始化或使用失败: {e}")
print("请检查 AI_STUDIO_API_KEY 是否正确配置")
print("\n" + "=" * 60)
============================================================ AI Studio 视觉 LLM 示例 ============================================================ ✓ 视觉 LLM 初始化成功: ernie-4.5-vl-28b-a3b 正在分析图片: 中文大模型基准测评2025年3月报告_7b6e53aaffda87f94aef030175fcf7db_slide_001.jpg 提问: 请简要描述这张图片的主要内容,包括标题、关键文字和视觉元素。 模型回答: ------------------------------------------------------------ 这张图片是文档的首页,整体设计简洁现代。 **标题**:图片顶部居中位置有标题“SuperCLUE”,其右侧有中文说明“中文大模型综合性测评基准”。 **关键文字**:左上角和中间偏下位置有一些被模糊处理的文字,中间偏下位置清晰可见的文字有“SuperCLUE团队”以及版本号“2025.0.3.18”。 **视觉元素**:背景主要由蓝色和白色构成,蓝色部分占据图片中间大部分区域,带有一些浅蓝色的几何形状装饰,增加了视觉层次感。顶部有一条黑色横条,与蓝色背景形成鲜明对比。 ------------------------------------------------------------ 多图对比示例: 图片 1: 中文大模型基准测评2025年3月报告_7b6e53aaffda87f94aef030175fcf7db_slide_001.jpg 图片 2: 中文大模型基准测评2025年3月报告_7b6e53aaffda87f94aef030175fcf7db_slide_002.jpg 提问: 这两张图片有什么相同点和不同点? 模型回答: ------------------------------------------------------------ ### 相同点 1. **品牌标识**:两张图片右上角均展示了 “SuperCLUE” 的标志及 “中文大模型综合性测评基准” 的文字说明,表明它们都与 “SuperCLUE” 这个项目相关。 2. **版本信息**:在图片底部均标注了 “SuperCLUE” 字样以及版本号 “2025.0.3.18”。 ### 不同点 1. **背景设计**:第一张图片背景主要为蓝色,带有一些浅蓝色的几何图形装饰;第二张图片背景为纯白色,右上角有蓝色的 “SuperCLUE” 标志,整体设计更为简洁。 2. **文本内容**:第一张图片左侧有两行被模糊处理的文本;第二张图片左侧有两行同样被模糊处理的中文文本以及一行英文文本,内容分别为 “准确量化AGI的进展,定义人类迈向AGI的路线图” 。 3. **额外标识**:第二张图片右上角除了 “SuperCLUE” 标志外,还有 “独立第三方AGI测评机构” 的黑色条纹文字标识。 ------------------------------------------------------------ ============================================================
7. 文本文档解析器 (TextDocumentParser)
7.1 技术原理
TextDocumentParser 专门处理纯文本和 Markdown 文件。与图片文档不同,文本文档可以直接读取内容,无需 OCR。
7.2 编码支持
自动处理多种文本编码:
- 优先尝试 UTF-8:现代标准编码
- 降级到 GBK:处理中文 Windows 环境的文件
- 错误处理:如果两种编码都失败,抛出明确的错误信息
7.3 分块策略
为了适应嵌入模型的 token 限制和提高检索精度,需要将长文本分块:
- 默认块大小:2000 字符(可通过
MAX_TEXT_CHUNK_SIZE环境变量配置) - 分块方法:简单的固定大小分块
- 保持连贯性:每个块是完整的文本片段
7.4 核心方法
parse(file_path): 读取文件内容,自动处理编码parse_and_chunk(file_path): 读取并分块,返回块列表
In [ ]
print("=" * 60)
print("文本文档解析器示例")
print("=" * 60)
text_parser = TextDocumentParser(max_chunk_size=500)
print(f"✓ 文本解析器初始化成功(块大小: {text_parser.max_chunk_size} 字符)")
sample_text_content = """# 人工智能技术概览
## 1. 机器学习
机器学习是人工智能的核心技术之一,它使计算机能够从数据中学习模式,而无需明确编程。
主要类型:
- 监督学习:从标注数据中学习
- 无监督学习:发现数据中的隐藏模式
- 强化学习:通过试错学习最优策略
## 2. 深度学习
深度学习是机器学习的一个子领域,使用多层神经网络处理复杂问题。
应用领域:
- 计算机视觉:图像识别、目标检测
- 自然语言处理:文本生成、机器翻译
- 语音识别:语音转文字、语音合成
## 3. 大语言模型
大语言模型(LLM)是近年来 AI 领域的重大突破,能够理解和生成自然语言。
代表模型:
- GPT 系列:OpenAI 开发的生成式预训练模型
- BERT:Google 开发的双向编码器
- ERNIE:百度开发的增强型语言模型
这些技术正在深刻改变我们的生活和工作方式。
"""
sample_file = Path("test_document.md")
sample_file.write_text(sample_text_content, encoding='utf-8')
print(f"\n创建示例文本文件: {sample_file}")
content = text_parser.parse(str(sample_file))
print(f"\n解析结果:")
print(f" 文件大小: {len(content)} 字符")
print(f" 内容预览(前 200 字符):")
print(f" {content[:200]}...")
chunks = text_parser.parse_and_chunk(str(sample_file))
print(f"\n分块结果:")
print(f" 总块数: {len(chunks)}")
for i, chunk in enumerate(chunks, 1):
print(f"\n 块 {i} ({len(chunk)} 字符):")
print(f" {chunk[:100]}...")
sample_file.unlink()
print(f"\n✓ 清理示例文件")
print("\n" + "=" * 60)
8. 多文档 RAG 引擎 (MultiDocRAGEngine)
8.1 技术原理
MultiDocRAGEngine 是整个系统的核心,将前面所有组件整合在一起,实现完整的文档问答流程。RAG(Retrieval-Augmented Generation) 是一种将信息检索和文本生成结合的技术,能够基于外部知识库回答问题。
8.2 核心流程
1. 文档输入
↓
2. 类型检测 (DocumentDetector)
↓
3. 内容提取
├─ 图片类文档 → 转换为图片 (DocumentConverter) → OCR 解析 (PaddleOCR-VL)
└─ 文本类文档 → 直接读取 (TextDocumentParser) → 文本分块
↓
4. 向量嵌入 (AIStudioEmbedding)
↓
5. 存储到向量数据库 (ChromaDB)
↓
6. 用户查询
↓
7. 检索相关文档片段(语义搜索)
↓
8. 生成答案 (LLM)
8.3 缓存优化
系统实现了多层缓存机制:
- 节点缓存:缓存已处理的文档节点
- 图片缓存:缓存文档转图片的结果
- Markdown 缓存:缓存 OCR 解析结果
基于文件哈希值,相同内容的文档只需处理一次。
8.4 核心方法
add_document(file_path, force_reprocess): 添加文档到知识库query(question, similarity_top_k): 查询问题,返回答案和来源remove_document(file_path): 从知识库中删除文档list_documents(): 列出已添加的所有文档
In [ ]
import asyncio
print("=" * 60)
print("多文档 RAG 引擎示例")
print("=" * 60)
embedding_model_name = os.getenv("EMBEDDING_MODEL", "bge-large-zh")
vision_model_name = os.getenv("VISION_LLM_MODEL", "ernie-4.5-vl-28b-a3b")
print(f"\n初始化 RAG 引擎...")
print(f" 嵌入模型: {embedding_model_name}")
print(f" 视觉模型: {vision_model_name}")
try:
rag_engine = MultiDocRAGEngine(
embedding_model=embedding_model_name,
vision_model=vision_model_name
)
print("✓ RAG 引擎初始化成功")
except Exception as e:
print(f"✗ RAG 引擎初始化失败: {e}")
print("请检查环境配置")
print("\n" + "=" * 60)
In [ ]
print("添加文档到知识库...\n")
doc_file = "data/PaddleOCR-VL_Technical_Report.pdf"
if Path(doc_file).exists():
print(f"正在添加: {Path(doc_file).name}")
async def add_doc():
result = await rag_engine.add_document(doc_file)
return result
result = await add_doc()
print(f"\n添加结果:")
print(f" 状态: {result['status']}")
print(f" 消息: {result.get('message', 'N/A')}")
if 'doc_id' in result:
print(f" 文档 ID: {result['doc_id']}")
if 'nodes_added' in result:
print(f" 节点数: {result['nodes_added']}")
else:
print(f"文件不存在: {doc_file}")
print("\n" + "=" * 60)
In [30]
print("查询知识库...\n")
test_question = "这份报告的主题是什么?"
print(f"问题: {test_question}")
async def query_engine():
response = await rag_engine.query(test_question)
return response
response = await query_engine()
print(f"\n回答:")
print("-" * 60)
print(response['answer'])
print("-" * 60)
if 'source_nodes' in response and response['source_nodes']:
print(f"\n参考来源(共 {len(response['source_nodes'])} 条):")
for i, source in enumerate(response['source_nodes'][:2], 1):
print(f"\n 来源 {i}:")
print(f" 文档: {source.get('file_name', 'N/A')}")
print(f" 相似度: {source.get('score', 0):.4f}")
content_preview = source.get('text', '')[:150]
print(f" 内容预览: {content_preview}...")
print("\n" + "=" * 60)
查询知识库... 问题: 这份报告的主题是什么? 回答: ------------------------------------------------------------ 这份报告的主题是关于PaddleOCR-VL的技术报告。 支持这一结论的信息包括: 1. 文档名称明确为“PaddleOCR-VL_Technical_Report.pdf”。 2. 在第68页,有关于手势操作顺序、手势目的及图示的内容,涉及PaddleOCR-VL相关。 3. 在第39页和第37页的图A11和图A39中,展示了各种类型文档的布局检测结果,其中可能包含PaddleOCR-VL的应用或相关实验数据。 4. 文档整体围绕文档分析,特别是布局检测(Layout Detection)技术展开,如图A9所示,对不同类型文档的布局检测结果进行了展示。 ------------------------------------------------------------ ============================================================
9. 完整端到端示例
场景一:PPT 文档深度问答
在这个场景中,我们将演示如何使用 RAG 系统分析一份完整的 PPT 报告,并回答多个不同类型的问题。
In [32]
print("=" * 60)
print("场景一:PPT 文档深度问答")
print("=" * 60)
questions = [
"报告中提到了哪些关键的 AIGC 应用领域?",
"报告对 AIGC 技术的发展趋势有什么预测?",
"有哪些具体的数据或统计信息?"
]
print("\n执行多轮问答...\n")
for i, question in enumerate(questions, 1):
print(f"问题 {i}: {question}")
async def ask_question():
return await rag_engine.query(question)
answer_result = await ask_question()
print(f"回答: {answer_result['answer'][:200]}...")
print()
print("=" * 60)
============================================================ 场景一:PPT 文档深度问答 ============================================================ 执行多轮问答... 问题 1: 报告中提到了哪些关键的 AIGC 应用领域? 回答: 图中报告没有直接提到关键的AIGC应用领域,但是Figure A5展示了Book、Textbook和Academic Paper的布局和Markdown输出,Figure A11展示了各种类型文档的布局检测结果。 从这些图中,可以推断出AIGC(人工智能生成内容)在文档解析和布局检测中的应用领域可能包括: 1. **书籍和教科书**:AIGC可以用于生成教材内容,帮助作者创建结构良好、内容丰富的书... 问题 2: 报告对 AIGC 技术的发展趋势有什么预测? 回答: 图中展示的PDF文档的第33页和第34页中并未出现有关报告对AIGC技术的发展趋势有什么预测的相关内容。 而文档第39页的Figure A11展示了各种类型文档的布局检测结果,包括学术论文、报纸、合同、杂志等,但同样没有提及报告对AIGC技术的发展趋势的预测。 若要了解报告对AIGC技术的发展趋势的预测,建议查看报告的其他页面或相关文档。... 问题 3: 有哪些具体的数据或统计信息? 回答: 图中展示的是PDF文档“PaddleOCR-VL_Technical_Report”的第42页、第33页和第43页内容,这三页均包含图表,没有具体的数据或统计信息,但展示了不同语言(法语、印地语、克罗地亚语、西班牙语)文档的Markdown输出以及书籍、教科书、学术论文的布局和Markdown输出。以下是各页的详细描述: ### 第42页 - **标题**:D.4. Text Recogniti... ============================================================
场景二:多文档对比分析
添加多个文档,然后进行跨文档的信息对比和综合分析。
In [ ]
print("=" * 60)
print("场景二:多文档对比分析")
print("=" * 60)
second_doc = "data/中文大模型基准测评2025年3月报告.pptx"
if Path(second_doc).exists():
print(f"\n添加第二份文档: {Path(second_doc).name}")
async def add_second_doc():
return await rag_engine.add_document(second_doc)
result2 = await add_second_doc()
print(f" 状态: {result2['status']}")
print("\n查看已添加的文档:")
docs = rag_engine.list_documents()
for i, doc in enumerate(docs, 1):
print(f" {i}. {doc}")
compare_question = "比较这两份报告的主题和关注点有什么不同?"
print(f"\n跨文档对比问题: {compare_question}")
async def compare_docs():
return await rag_engine.query(compare_question, similarity_top_k=4)
compare_result = await compare_docs()
print(f"\n回答:")
print("-" * 60)
print(compare_result['answer'])
print("-" * 60)
else:
print(f"\n文件不存在: {second_doc}")
print("\n" + "=" * 60)
场景三:混合格式文档处理
演示系统处理不同格式文档(PPT、Markdown、文本)的能力。
In [ ]
print("=" * 60)
print("场景三:混合格式文档处理")
print("=" * 60)
text_doc_content = """# RAG 系统技术说明
RAG(Retrieval-Augmented Generation)是一种结合检索和生成的技术架构。
## 核心优势
1. **知识时效性**:可以实时更新知识库,无需重新训练模型
2. **可解释性**:每个回答都有明确的来源引用
3. **成本效益**:相比完全微调大模型,成本更低
## 应用场景
- 企业内部知识库问答
- 技术文档助手
- 客服机器人
这是一种非常实用的 AI 应用架构。
"""
text_doc_path = Path("rag_intro.txt")
text_doc_path.write_text(text_doc_content, encoding='utf-8')
print(f"\n创建文本文档: {text_doc_path}")
async def add_text_doc():
return await rag_engine.add_document(str(text_doc_path))
text_result = await add_text_doc()
print(f" 添加状态: {text_result['status']}")
print("\n所有文档类型:")
all_docs = rag_engine.list_documents()
for i, doc in enumerate(all_docs, 1):
doc_type = detector.detect(doc)
print(f" {i}. {Path(doc).name} ({doc_type})")
mixed_question = "RAG 系统有什么优势?"
print(f"\n混合检索问题: {mixed_question}")
async def mixed_query():
return await rag_engine.query(mixed_question, similarity_top_k=3)
mixed_result = await mixed_query()
print(f"\n回答:")
print("-" * 60)
print(mixed_result['answer'])
print("-" * 60)
if 'source_nodes' in mixed_result:
print(f"\n来源文档类型分布:")
source_types = {}
for source in mixed_result['source_nodes']:
file_name = source.get('file_name', 'unknown')
doc_type = detector.detect(file_name) if Path(file_name).exists() else 'unknown'
source_types[doc_type] = source_types.get(doc_type, 0) + 1
for doc_type, count in source_types.items():
print(f" {doc_type}: {count} 条")
text_doc_path.unlink()
print(f"\n✓ 清理临时文件")
print("\n" + "=" * 60)
10.ChatOffice使用
ChatOffice 是一个基于百度 AI Studio 生态的多模态多格式文档 RAG (检索增强生成) 引擎,支持 7 种文档格式的智能问答。
核心特性
✅ 多格式支持: PPT/PDF/Word/Excel/图片/TXT/Markdown
🔍 智能检索: 向量相似度检索 + 多模态理解
🤖 本地解析: PaddleOCR-VL 本地 OCR,无额外 API 成本
🌐 MCP 协议: 通过 Model Context Protocol 提供服务
📊 交互测试: 命令行交互式测试工具
处理流程
- 添加文档
file → 检测类型 → 转换为图片 → OCR解析 → 创建节点 → 向量化 → 存储
- 查询
query → 向量化 → 检索topK节点 → 构建上下文 → 视觉LLM → 返回答案
In [ ]
%cd /home/aistudio/chatoffice
# 安装chatoffice
!pip install -e .
# RAG测试模式
!python rag_interactive_test.py
# 在终端中测试下述功能
# !python src/mcp_ppt_server.py --transport sse --port 5053
# !python mcp_interactive_test.py



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











