




这章没有代码是youTube的视频,英听后,内容如下:
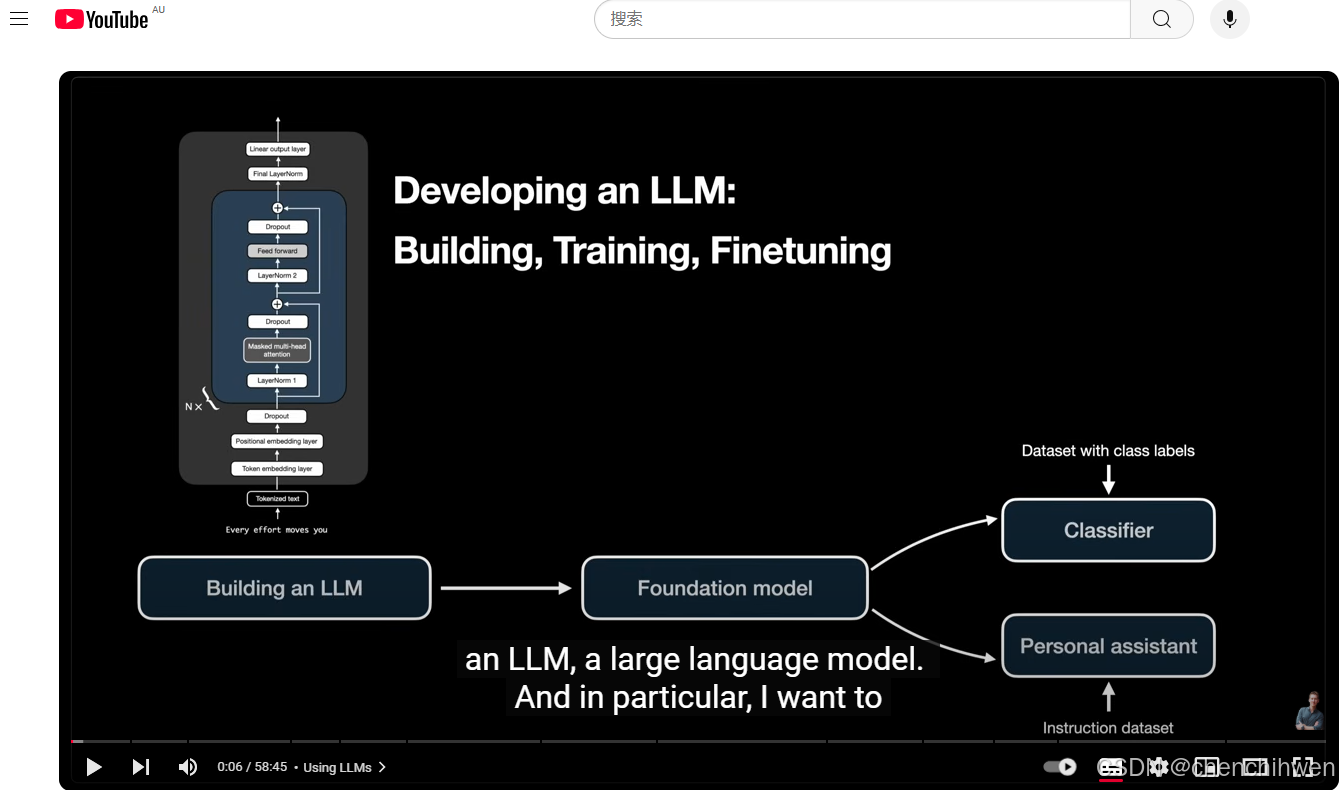
开发大型语言模型(LLM)的流程幻灯片,主要分为三个部分:构建、训练和微调。
-
构建大型语言模型(Building an LLM)
- 从左下角的 “Tokenized text”(标记化文本)开始。
- 依次经过 “Token embedding layer”(标记嵌入层)和 “Positional embedding layer”(位置嵌入层)。
- 然后经过多次 “Dropout”(随机失活)、“Masked multi - head attention”(掩码多头注意力)、“LayerNorm”(层归一化)和 “Feed - forward”(前馈神经网络)操作。
- 最后通过 “Linear output layer”(线性输出层)得到结果。
-
基础模型(Foundation model)
- 构建好的大型语言模型成为基础模型。
-
微调(Finetuning)
- 基础模型可以通过两种方式进行微调:
- 使用 “Dataset with class labels”(带类别标签的数据集)微调成 “Classifier”(分类器)。
- 使用 “Instruction dataset”(指令数据集)微调成 “Personal assistant”(个人助手)。
- 基础模型可以通过两种方式进行微调:
演讲原文如下,先看中文意思
https://www.youtube.com/watch?v=kPGTx4wcm_w![]() https://www.youtube.com/watch?v=kPGTx4wcm_w
https://www.youtube.com/watch?v=kPGTx4wcm_w
大型语言模型(LLM)开发的详细综述,涵盖了从数据集准备到模型训练、微调,再到评估和实际应用的各个方面,以下是详细内容:
一、LLM 开发概述
- 开发阶段
- 构建(Building):准备数据集,实现注意力机制和模型架构相关的编码。
- 预训练(Pre - training):在大型数据集上训练模型,形成基础模型,并评估和保存模型权重。
- 微调(Fine - tuning):根据特定任务(如分类、问答、创建聊天机器人)对模型进行调整,利用特定的指令数据集。
- 当前应用场景
- 公共或专有服务:如通过公共 API 访问 ChatGPT 和 Gemini 等。
- 本地运行自定义模型:利用开源模型(如 Llama 3)在本地与模型交互。
- 在外部服务器上部署自定义模型:用于产品开发和集成到应用程序中。
二、数据集准备
- 重要性
- 数据集准备是开发 LLM 的重要初始步骤,需要进行采样以确保数据对训练具有代表性和有效性。
- 数据输入过程对模型学习效果至关重要。
- 训练方法
- LLM 通常采用下一个标记预测(next token prediction)方法,在包含数十亿单词的大型数据集上训练。
- 实际训练中,为提高效率会对输入数据进行批处理(batching),每个批次包含相同长度的输入(通常为张量形式),预训练的输入长度通常在 256 到 1024 个标记或更多。
三、语言模型中的词预测
- 过程
- 语言模型每次迭代进行一个单词预测任务,逐词生成文本。
- 从给定输入文本开始,模型基于输入上下文预测下一个单词,生成的单词再反馈回模型作为新的上下文用于后续预测,直到生成 “文本结束” 标记或达到特定的标记数量限制。
- 标记化机制
- 语言模型处理的是标记(tokens)而非单词,标记可以包括单词的部分或标点符号。
- 输入文本经过标记化处理后,每个标记转换为标记 ID 用于模型计算,标记化通常依赖于从训练数据构建的词汇表。
四、训练数据集规模趋势
- 增长趋势
- 用于训练语言模型的数据集规模在不断增大,例如 GPT - 3 使用约 5000 亿个标记训练,而更近期的模型使用超过万亿个标记的数据集。
- 但在数据集透明度方面有所变化,早期模型会详细说明数据来源,而新模型往往只提到标记总数,不具体说明来源。
- 数据与模型性能的平衡
- 较小的数据集可能使语言模型保留更多用于重要推理和理解的能力,一些模型(如 Microsoft's F)认为不包含所有数据(如琐碎的游戏结果)可以使模型专注于更重要的信息,有助于有效推理。
五、理解 LLM 架构
- 核心架构
- 开发大型语言模型(如 GPT - 2 和 GPT - 3)的核心架构包括掩码多头注意力模块、前馈层、位置嵌入层等,通常有一个 Transformer 块会重复多次(12 到 64 次不等,取决于模型大小)。
- 小型和大型模型的差异主要在于 Transformer 块的重复次数和多头注意力机制中的头数(类似于卷积神经网络中的通道)。
- 模型大小差异
- 以 GPT - 2 模型为例,不同大小的模型架构差异主要在 Transformer 块的重复次数上,模型参数可以从 1.24 亿到 15 亿不等,较小模型的嵌入维度约为 768,较大模型可达 4000。
- 层归一化和训练技术进展
- 现代架构(如 LLaMA 2)使用均方根(RMS)归一化代替传统层归一化,有利于多 GPU 训练。
- 训练技术改进包括使用相对位置嵌入,使模型能够处理更多的标记输入(从 1024 增加到 4000 个标记),模型通常训练 1 到 2 个轮次,训练方法常涉及从大型数据集中随机采样。
六、控制语言模型的随机性
- 重要性
- 控制语言模型训练中的随机性对于实现预期结果至关重要,通过管理随机性可以防止模型仅仅复制训练数据而不是生成新的连贯文本。
- 处理大数据集时,较长的训练通常能产生更熟练的文本生成,但对于小数据集,过长训练可能导致过拟合,需要密切监控模型。
- 训练中的挑战
- 训练语言模型时,需要了解哪些记忆是可取的,例如历史日期等事实应该被记住,但要避免不必要的训练集记忆以保持模型的通用性。
七、预训练语言模型
- 预训练的成本和替代方案
- 预训练大型语言模型需要大量计算资源和时间,通常需要在强大的 GPU 上训练数周,因此对于许多任务来说,利用各机构共享的预训练权重进行模型调整更为实际。
- 了解语言模型架构的变化很重要,因为不同架构会影响特定任务的性能,支持多种模型权重的工具和库有助于探索这些差异。
八、微调语言模型用于分类
- 输出层调整
- 对语言模型进行分类任务的微调时,需要调整输出层,减小其大小以匹配特定的类别数量(例如,垃圾邮件检测的两类),这不仅提高效率,还能增强模型性能。
- 微调过程中通常会监控损失和分类准确率,损失用于优化,准确率用于评估模型在目标分类任务上的性能。
- 更新层数
- 微调不需要更新模型的所有层,在许多情况下,仅更新最后几层就能获得良好结果,例如仅更新最后一个输出层和两个额外的 Transformer 块就能获得与更新所有层相当的性能,且速度更快、资源更高效。
九、指令数据集概述
- 数据集规模和示例
- 指令数据集用于让大型语言模型根据特定指令生成响应,其规模通常在 50,000 到 100,000 个示例之间。
- 例如,Paka 数据集约有 51,000 个示例,是最早公开可用的指令数据集之一;Lima 数据集只有 1000 个示例,但取得了不错的结果,表明输入数据的质量可能比数量更重要。
十、偏好微调(Preference Tuning)
- 目的和作用
- 偏好微调用于优化 LLM 生成的响应,使模型朝着期望的行为方向发展,通常在指令查找之后进行。
- 这一过程旨在根据特定特征优化输出,使模型的响应更符合技术或用户友好的要求,引导模型在响应中关注优化有用性或安全性的元素。
十一、语言模型的评估
- MMU 分数
- 定义:MMU 分数通常在 0 到 100 之间,用于根据语言模型(LLMs)回答多项选择题的表现对其进行排名。
- 局限性:该分数仅能衡量模型在多项选择题场景下的表现,无法全面评估 LLMs 的更广泛能力。
- 其他评估工具
-
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









