




Chapter 2: Working with Text Data
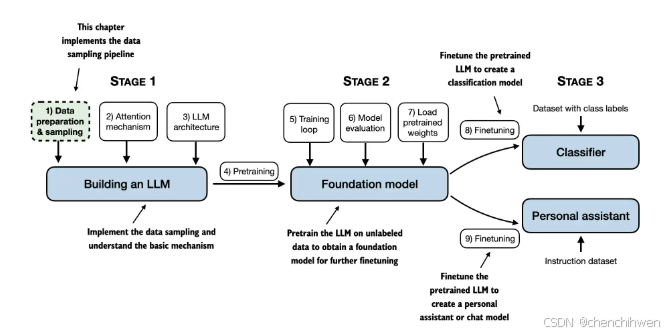
Main Chapter Code
- ch02.ipynb contains all the code as it appears in the chapter
ch02.ipynb 内容如下
主要是对文本数据进行处理,为大型语言模型(LLM)的训练做准备,涵盖了文本预处理、标记化、ID 转换、添加特殊标记、数据采样、创建标记嵌入以及编码单词位置等多个方面。以下是对代码的详细解释:
1. 书籍补充代码信息
Supplementary code for the <a href="http://mng.bz/orYv">Build a Large Language Model From Scratch</a> book by <a href="https://sebastianraschka.com">Sebastian Raschka</a><br>
<br>Code repository: <a href="https://github.com/rasbt/LLMs-from-scratch">https://github.com/rasbt/LLMs-from-scratch</a>
这部分是书籍补充代码的说明,提供了书籍的链接以及代码仓库的链接。
2. 导入和安装必要的包
收起
python
!pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install tiktoken -i https://pypi.tuna.tsinghua.edu.cn/simple
from importlib.metadata import version
print("torch version:", version("torch"))
print("tiktoken version:", version("tiktoken"))
importlib.metadata模块获取并打印torch和tiktoken的版本号。
torch version: 2.5.1
tiktoken version: 0.8.0
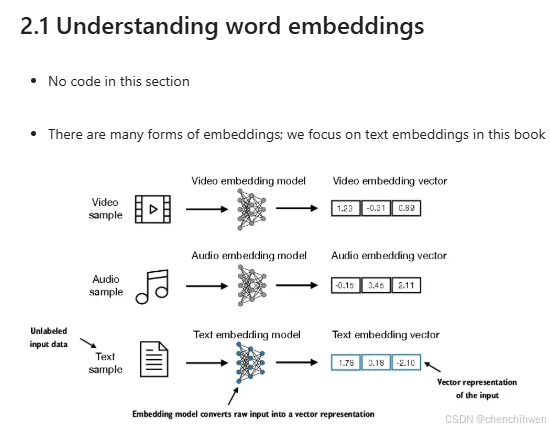

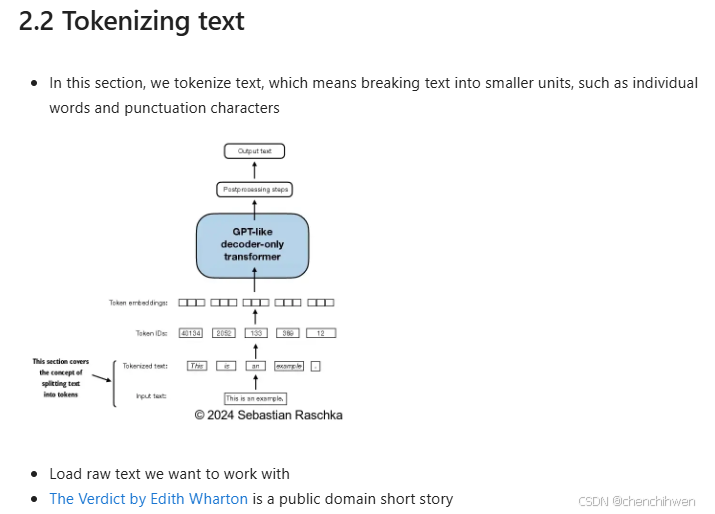
3. 文本数据准备
import os
import urllib.request
if not os.path.exists("the-verdict.txt"):
url = ("https://raw.githubusercontent.com/rasbt/"
"LLMs-from-scratch/main/ch02/01_main-chapter-code/"
"the-verdict.txt")
file_path = "the-verdict.txt"
urllib.request.urlretrieve(url, file_path)
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character:", len(raw_text))
print(raw_text[:99])
Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no
这段代码的作用是下载并读取名为the-verdict.txt的文本文件。如果该文件不存在,就从指定的 URL 下载。然后读取文件内容,打印文件的总字符数和前 99 个字符。
4. 标记化文本
- The goal is to tokenize and embed this text for an LLM
- Let's develop a simple tokenizer based on some simple sample text that we can then later apply to the text above
- The following regular expression will split on whitespaces
import re
text = "Hello, world. This, is a test."
result = re.split(r'(\s)', text)
print(result)
['Hello,', ' ', 'world.', ' ', 'This,', ' ', 'is', ' ', 'a', ' ', 'test.']
- We don't only want to split on whitespaces but also commas and periods, so let's modify the regular expression to do that as well
result = re.split(r'([,.]|\s)', text)
print(result)
['Hello', ',', '', ' ', 'world', '.', '', ' ', 'This', ',', '', ' ', 'is', ' ', 'a', ' ', 'test', '.', '']
- As we can see, this creates empty strings, let's remove them
result = [item for item in result if item.strip()]
print(result)
['Hello', ',', 'world', '.', 'This', ',', 'is', 'a', 'test', '.']
text = "Hello, world. Is this-- a test?"
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]
print(result)
['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(preprocessed[:30])
print(len(preprocessed))
通过正则表达式对文本进行逐步复杂的标记化处理。首先按空白字符分割,然后加入逗号和句号,再去除空字符串,最后处理包含更多标点符号的情况。对读取的原始文本raw_text应用最终的标记化规则,打印前 30 个标记和标记总数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









