




 PP-LiteSeg是一种轻量级的实时语义分割模型,包含FLD解码器、UAFM融合模块和SPPM池化模块。FLD通过减少通道和增加空间大小来平衡计算复杂度,UAFM结合空间和通道注意力增强特征,SPPM以较低成本聚合全局上下文。模型在Cityscapes测试集上表现出良好的准确性和速度平衡。
PP-LiteSeg是一种轻量级的实时语义分割模型,包含FLD解码器、UAFM融合模块和SPPM池化模块。FLD通过减少通道和增加空间大小来平衡计算复杂度,UAFM结合空间和通道注意力增强特征,SPPM以较低成本聚合全局上下文。模型在Cityscapes测试集上表现出良好的准确性和速度平衡。
1、主要参考
(1)论文下载地址
https://arxiv.org/abs/2204.02681
今年的论文还挺新的

(2)github地址
1)paddle的配置地址
PaddleSeg/configs/pp_liteseg at release/2.6 · PaddlePaddle/PaddleSeg · GitHub
2)pytorch的实现地址
GitHub - midasklr/PPLiteSeg.pytorch: pytorch of the SOTA real-time segmentation network ppliteseg
(3)博客参考
PP-LiteSeg_视觉菜鸟Leonardo的博客-优快云博客_liteseg
(4)paddle环境搭建,参考我的另一篇博客
(18)语义分割--paddle--EISeg自动标注软件的使用和自己数据集的测试_chencaw的博客-优快云博客
(5)百度官方的教程blibli视频
超越CVPR冠军模型的图像分割算法详解_哔哩哔哩_bilibili
2、pp-lite-seg原理
2.1论文题目
PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
PP-LiteSeg:一种高效的实时语义分割模型
2.2摘要
偷懒一下,感觉有道的翻译比某du靠谱
摘要:现实应用对语义分割方法有很高的要求。尽管语义分割随着深度学习的发展取得了长足的进步,但实时性方法的性能并不令人满意。在这项工作中,我们提出了一个全新的轻量级模型PP-LiteSeg,用于实时语义分割任务。具体地说,我们提出了一种灵活的轻量级解码器(FLD),以减少以往解码器的计算开销。为了加强特征表示,我们提出了一种利用空间和注意力通道优势的统一注意融合模块(UAFM)生成一个权重,然后将输入特征与权重融合。此外,提出了一种简单金字塔池化模块(SPPM),以较低的计算成本聚合全局上下文。大量的测试评估表明,与其他方法相比,PP-LiteSeg在准确性和速度之间实现了更好的折衷。在cityscape测试集上,PP-LiteSeg在NVIDIA GTX 1080Ti上实现了72.0% mIoU/273.6 FPS和77.5% mIoU/102.6 FPS
2.3整体网络结构
(1)看起来是使用了编码解码的结构,整体结构如下图所示
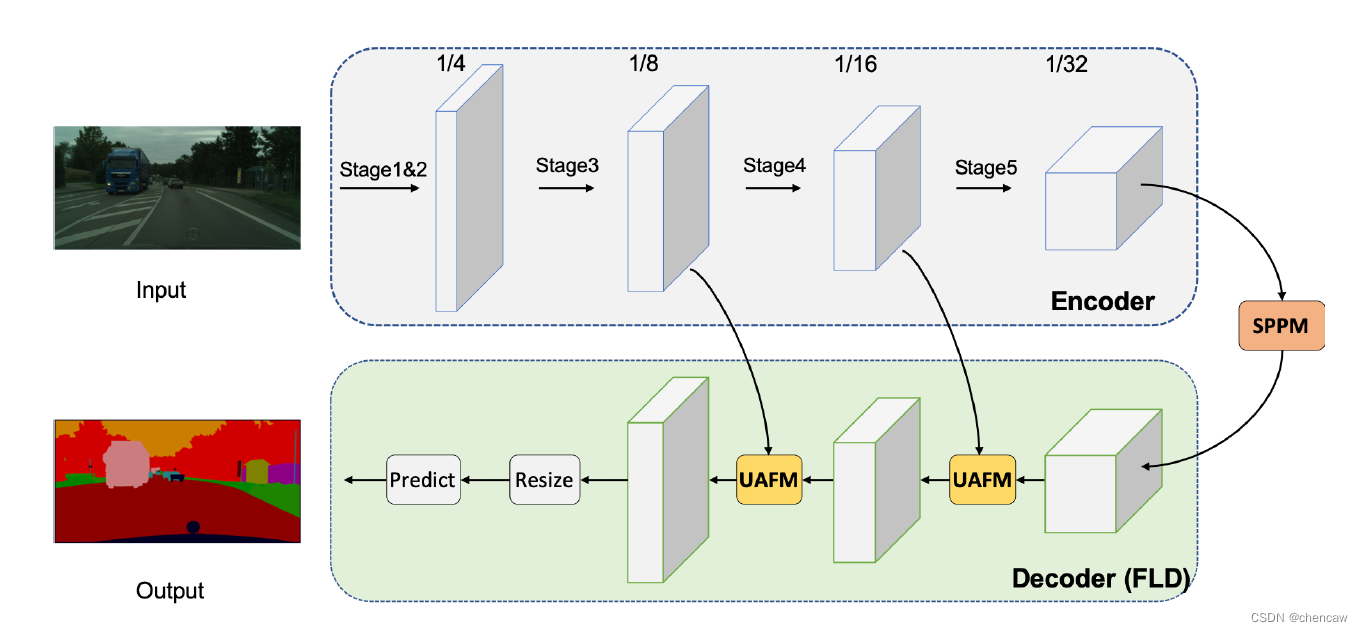
(2)三个主要的模块
- 灵活轻便的解码器(FLD)
- 统一注意融合模块(UAFM)
- 简单金字塔池池模块(SPPM)
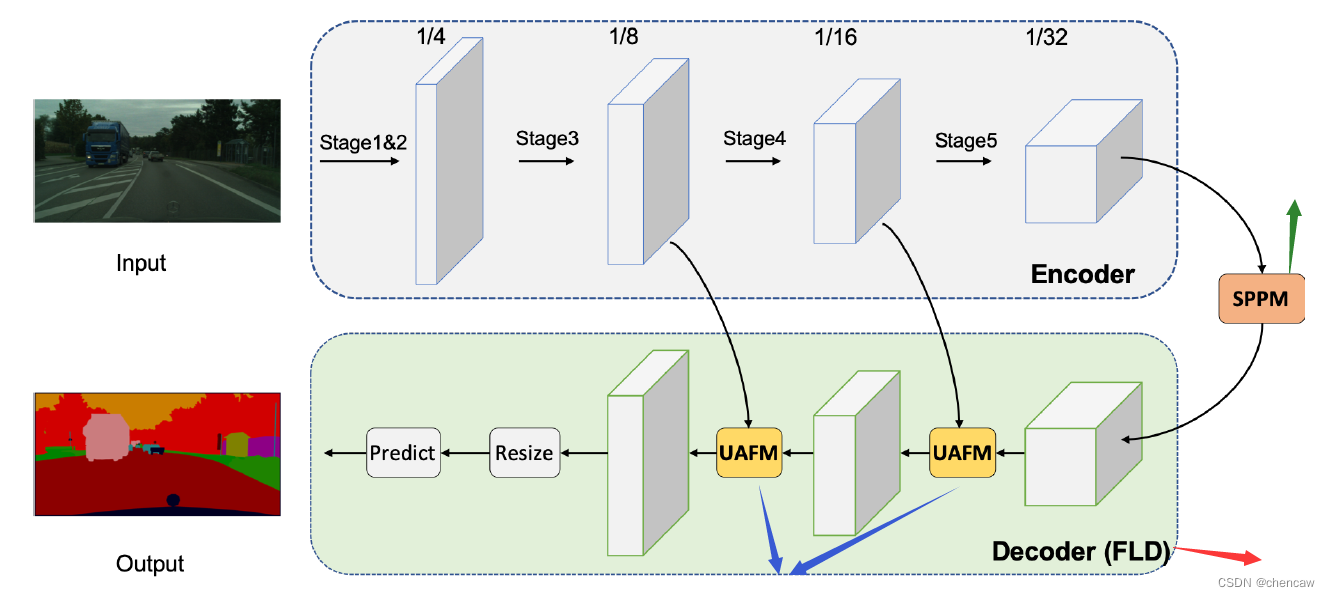
- 我们提出了一种灵活和轻量级的解码器(FLD),它逐渐减少通道和增加特征的空间大小。此外,所提出的解码器的容量可以很容易地根据编码器调整。灵活的设计平衡了编码器和解码器的计算复杂度,提高了整个模型的效率。
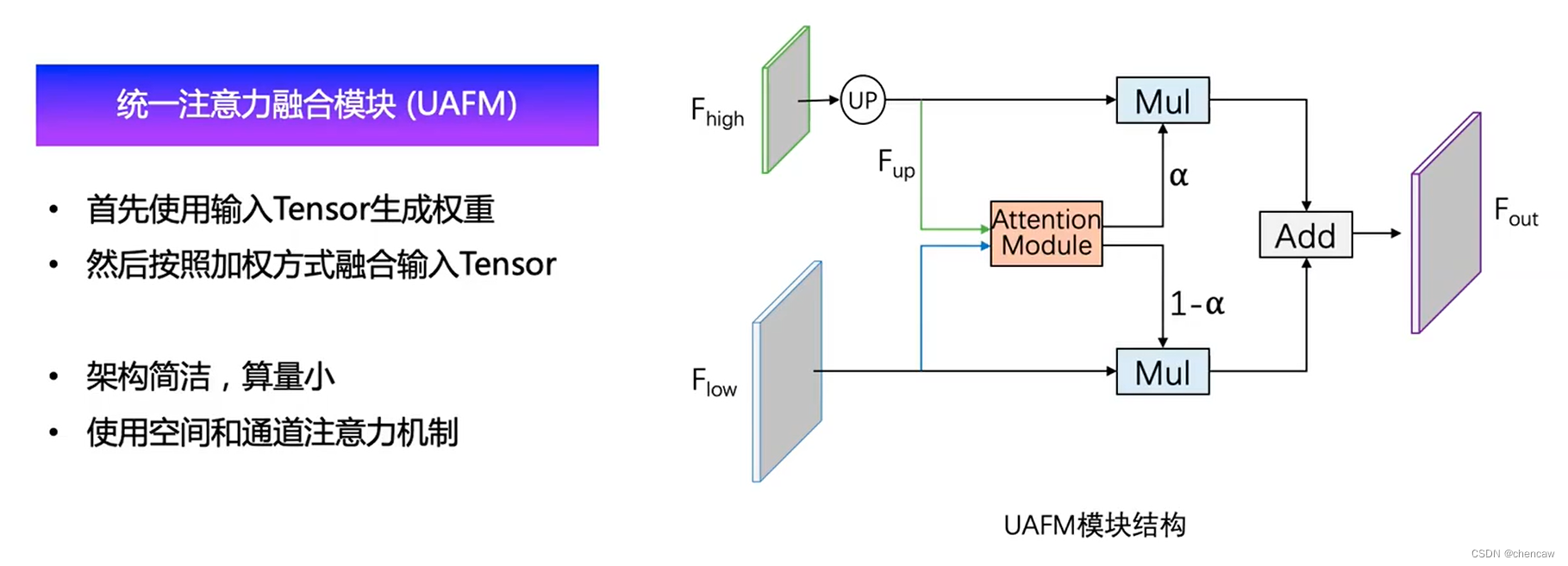
- UAFM首先利用注意模块产生权重a,然后将输入特征与a融合。在UAFM中,有两种注意模块,即空间注意模块和通道注意模块,它们利用了输入特征的空间间和通道间关系。
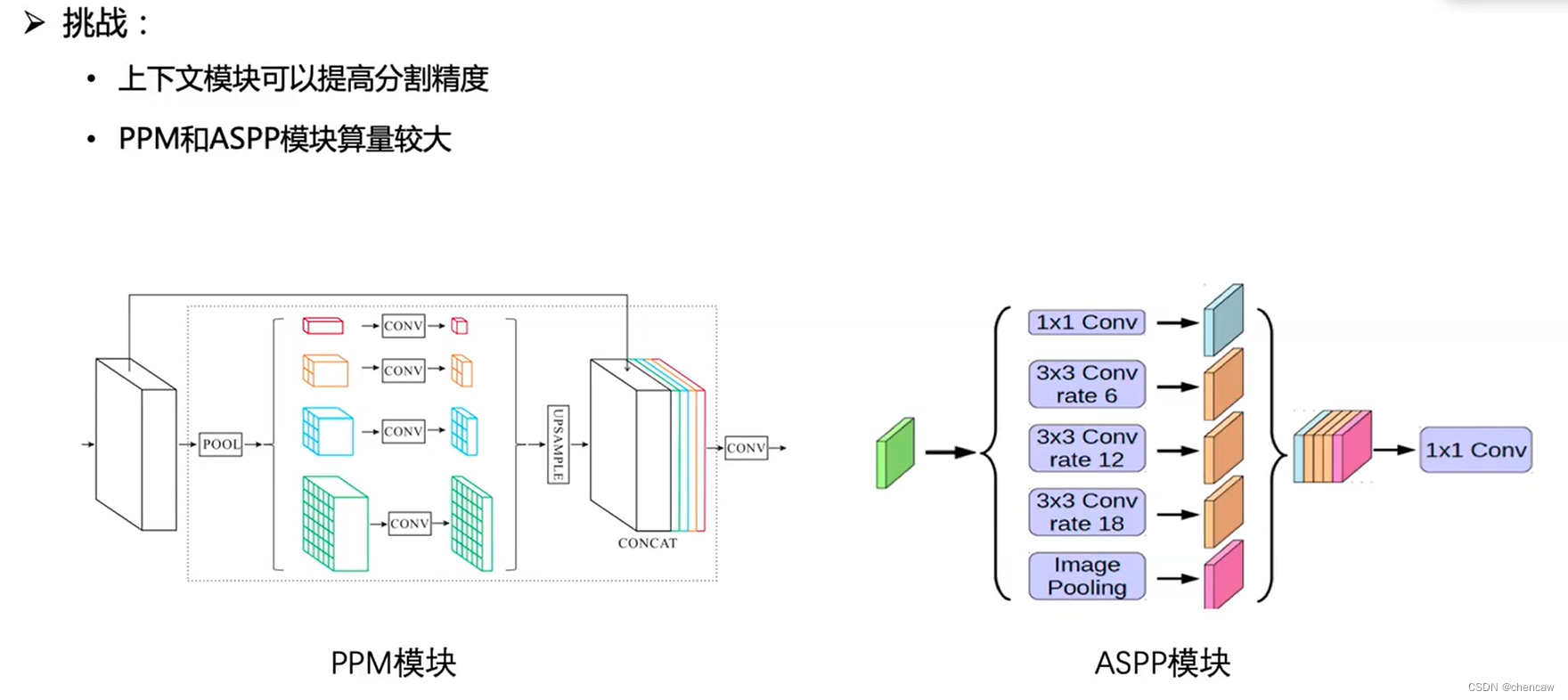
- 基于PPM[29]框架,设计了一个简单金字塔池化模块(SPPM),该模块减少了中间和输出通道,去掉了捷径,用加法(add)操作代替了堆叠连接(concat)操作。实验结果表明,SPPM算法具有较低的计算成本和较高的分割精度。
(3)主要贡献,再来一遍
- 我们提出了一种灵活的轻量解码器(FLD),该解码器减少了解码器的冗余,平衡了编码器和解码器的计算成本。
- 我们提出了一个统一注意融合模块(UAFM),利用通道和空间注意来加强特征表示。
- 我们提出了一个简单的金字塔池模块(SPPM)来聚合全局上下文。SPPM算法提高了分割精度,但增加的推理时间较少。
- 在此基础上,提出了实时语义分割模型PP-LiteSeg。大量的实验证明了我们在准确性和速度方面的SOTA性能。
(4)早期的语义分割网络研究
早前的实时语义分割提出了许多方法:轻量级模块设计(EfficientNet)、双分支架构(BiSeNet)、早期下采样(ENet)、多尺度图像级联网络(ICNet) 。
STDC基于BiSeNet,但舍弃了双分支网络,使用详细的group-truth来引导特征,提高效率
2.4 FLD模块
(1)
编码器-解码器结构已被证明是有效的语义分割。
一般来说,编码器利用分为几个阶段的一系列结构层(PS:卷积层)来提取层次特征。从低层次到高层次,通道数量逐渐增加,特征的空间大小逐渐减小。本文平衡了各阶段的计算成本,保证了编码器的效率。
解码器也有几个阶段,负责融合和上采样特性。尽管特征的空间大小由高到低递增,但最近的轻量化模型的解码器在所有级别上都保持了相同的特征通道。因此,浅阶段的计算成本远远大于深阶段,导致浅阶段的计算冗余。
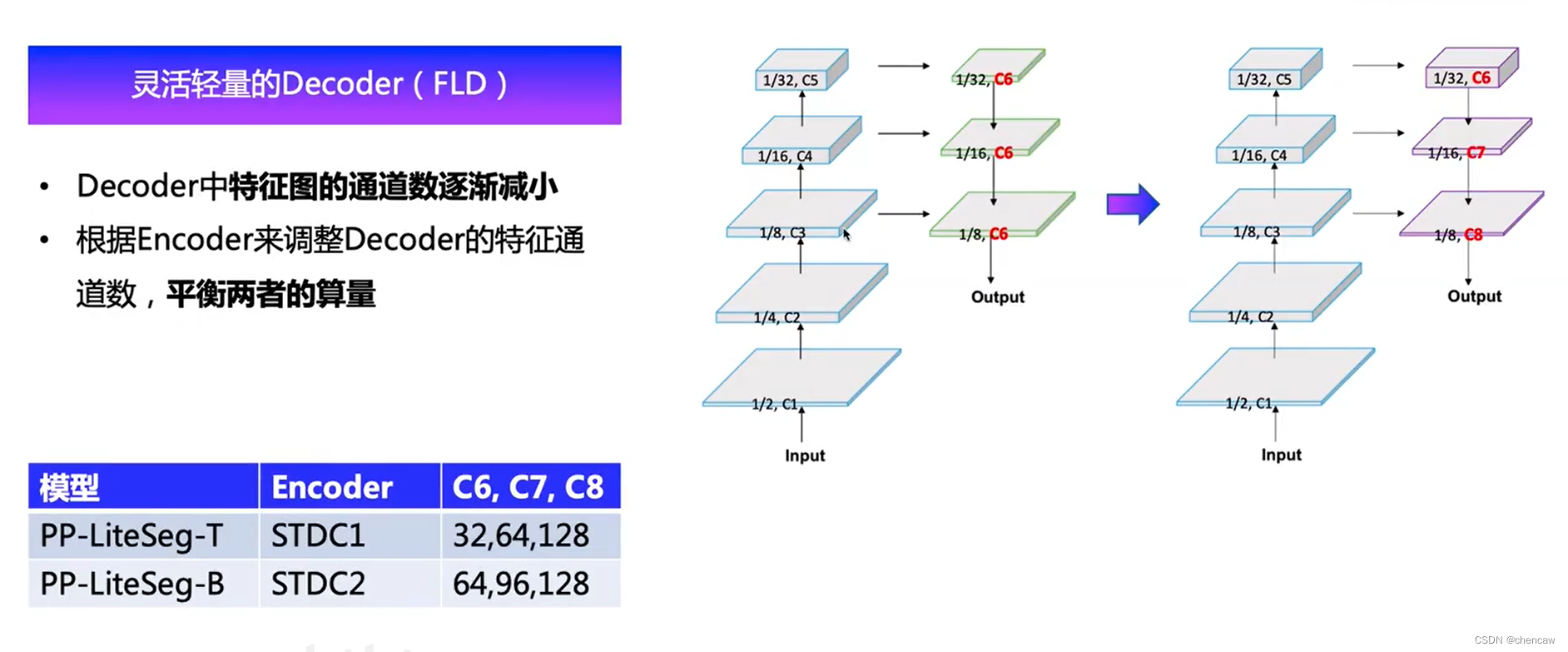
为了提高解码器的效率,我们提出了一种灵活的轻量解码器(FLD)。如图3所示,FLD逐渐减少了特征从高层次到低层次的通道。FLD可以很容易地调整计算成本,以达到编码器和解码器之间更好的平衡。尽管FLD的特征通道在减少,实验表明,与其他方法相比,PP-LiteSeg获得了具有竞争力的准确性。
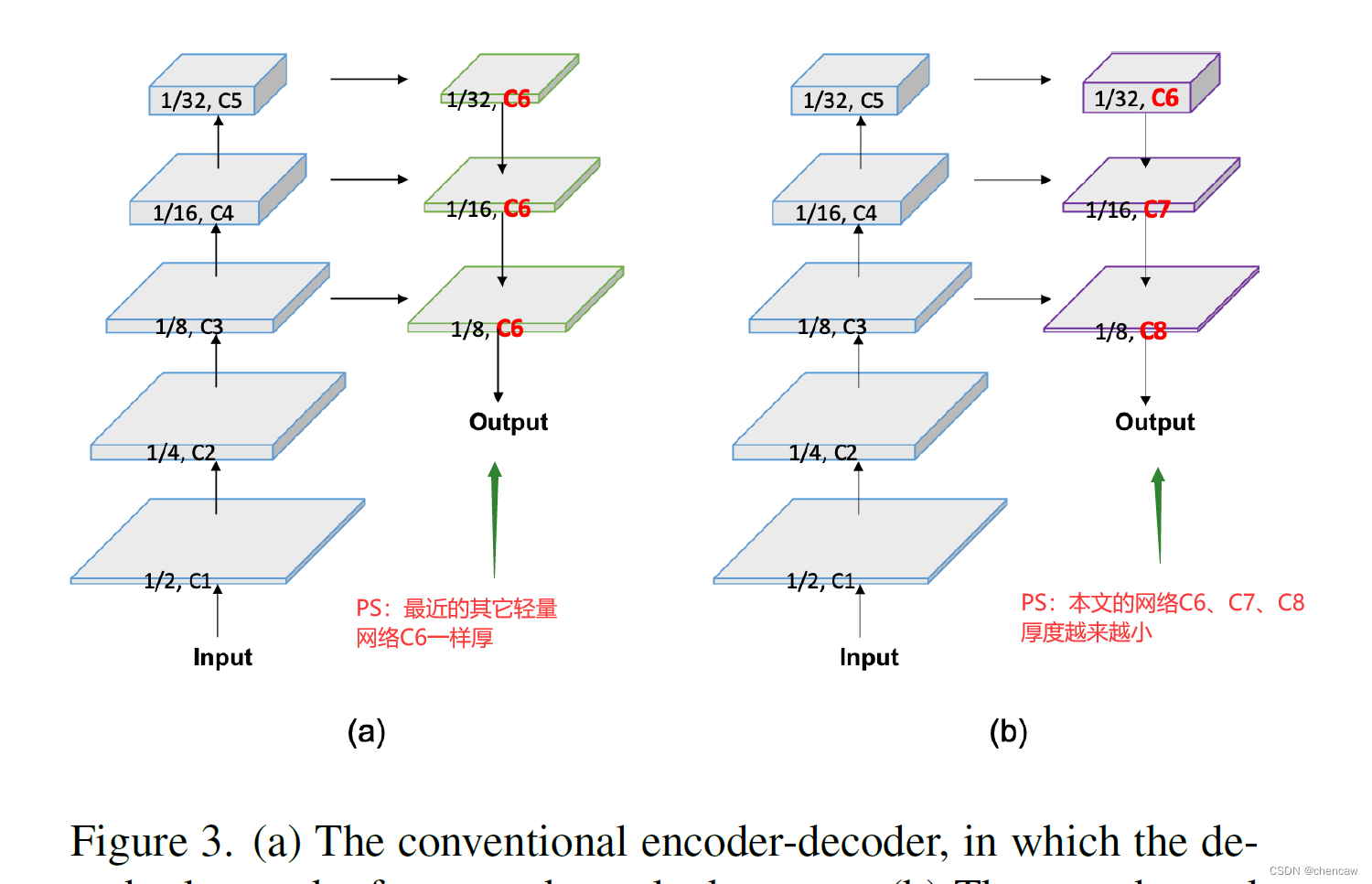
(2)对应的尺寸变换
2.5 UAFM模块
(1)PS:感觉像bisenet和stdc网络中的ARM和FFM模块结构
(2)下图值班截图了官方的视频
(3)最常见的语义分割浅层信息(边缘等细节信息)和深层语义信息(分类)的融合方法为add和contact,如下托所示。
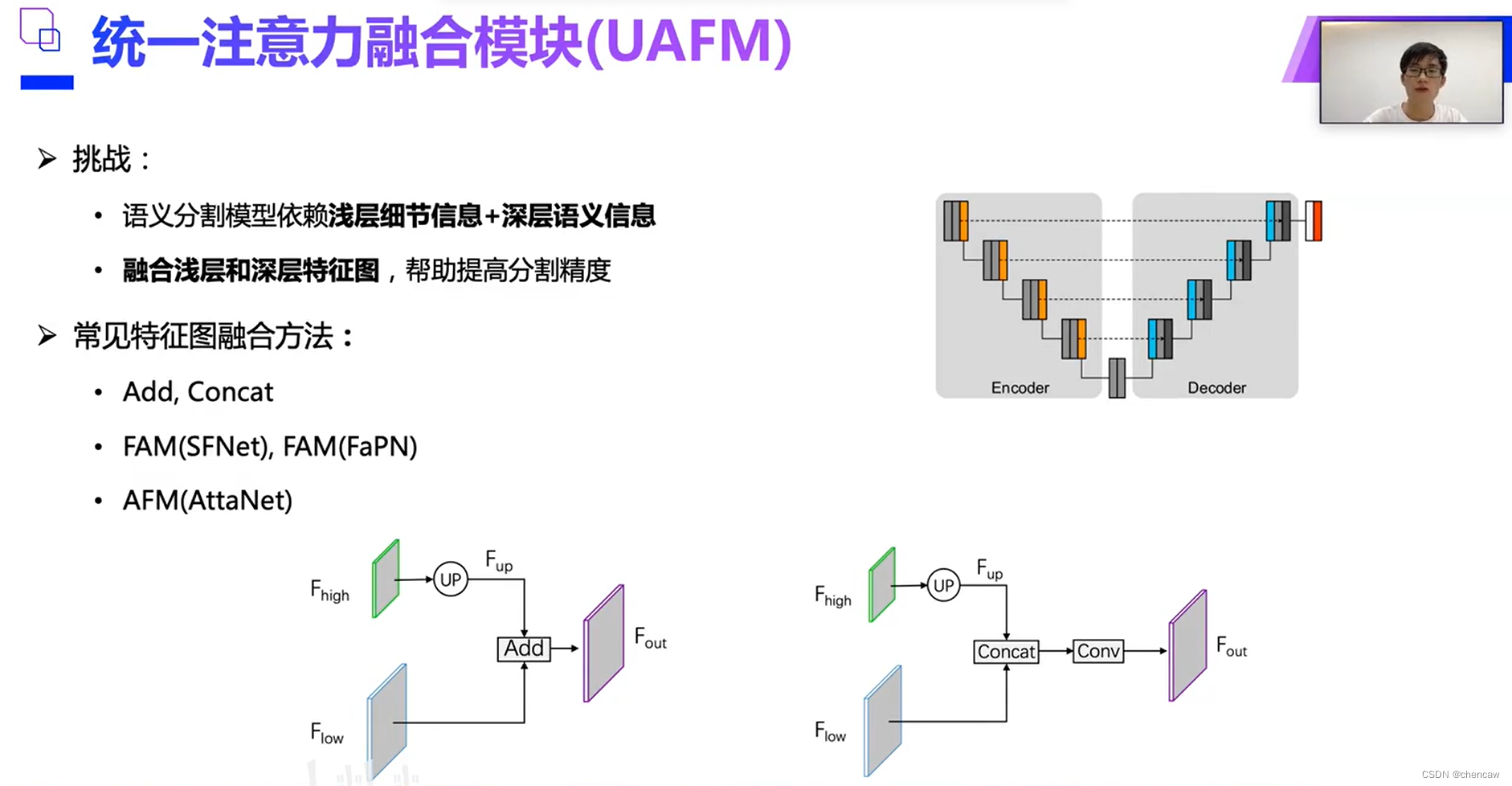
(4)本文提出的UAFM模块结构
2.5.1空间注意力机制的实现
(1)果然下面的伪代码写得很明确了,下面对应的是空间注意力机制,表示空间维度每个像素在融合过程中的重要性。
注意,cancat前的输出维度是n*1*h*w,concat后的输出维度是n*4*h*w

2.5.2通道注意力机制
(1)下面对应的是通道注意力机制,表示通道维度每个像素在融合过程中的重要性。
注意,cancat前的输出维度是n*c*1*1,concat后的输出维度是n*4c*1*1

2.6 简易的金字塔池化模块
(1)传统方法存在的问题
(2)本文所设计的简易SPPM模块
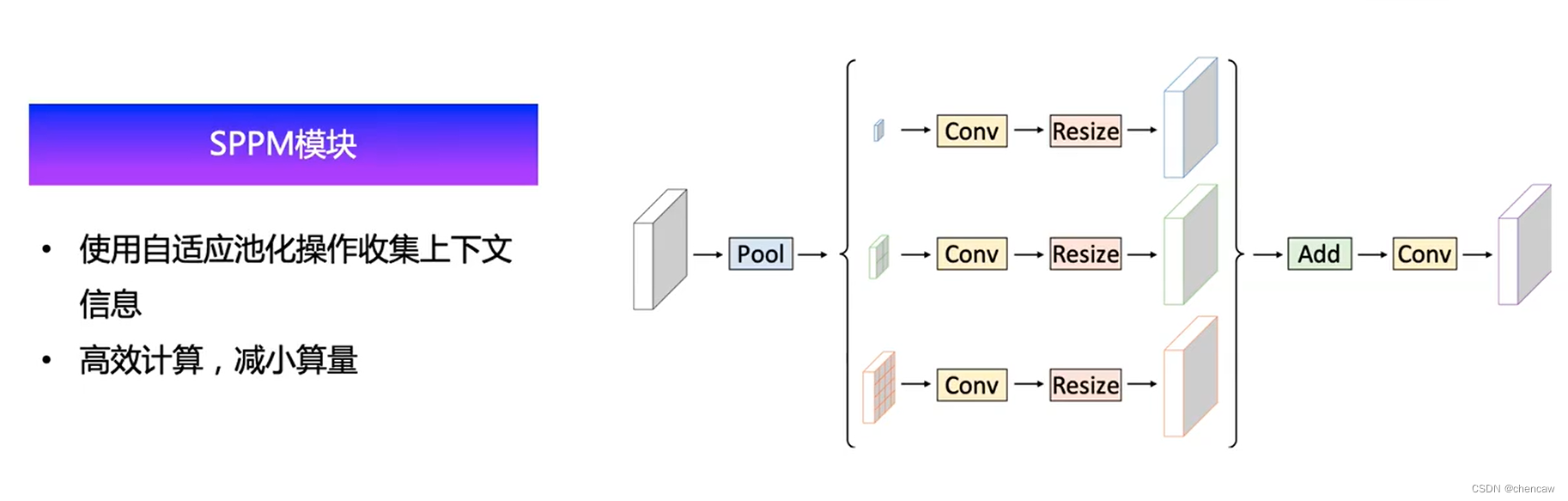
相比于传统的PPM模块方式的改变
- 移除了最上面的跳线连接(跳跃连接)
- 中间的tensor通道数比较小(128?),比较适合于轻量化的模型
- 用Add替换了Contact的操作,减少了通道数,使得最后那个conv卷积层的算量减少
???

















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









