








 超级会员免费看
超级会员免费看

多模态理解与生成的统一奖励模型
摘要
近年来,人类偏好对齐技术的进步显著提升了多模态生成与理解能力。关键方法是训练奖励模型来指导偏好优化。然而,现有模型通常针对特定任务设计,限制了其在多样化视觉应用中的适应性。我们认为,联合学习评估多个任务可能产生协同效应,即增强的图像理解可提升图像生成评估能力,而改进的图像评估又能通过更优的帧分析惠及视频评估。为此,本文提出了UNIFIEDREWARD,首个用于多模态理解与生成评估的统一奖励模型,支持成对排序和逐点评分,可用于视觉模型的偏好对齐。具体而言:(1)我们首先在自建的大规模人类偏好数据集上开发了UNIFIEDREWARD,涵盖图像和视频的生成/理解任务;(2)利用该模型自动构建高质量偏好对数据,通过成对排序和逐点筛选对视觉模型的输出进行精细过滤;(3)最终将这些数据用于直接偏好优化(DPO)以实现模型的偏好对齐。实验结果表明,联合学习评估多样化视觉任务可带来显著的互惠效益。我们将该方法应用于图像和视频的理解/生成任务,均显著提升了各领域的性能。
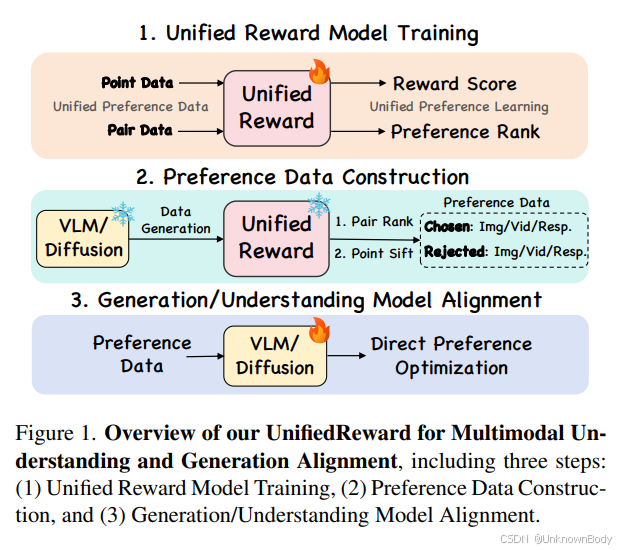
引言
近年来,人类偏好对齐技术的重大进展极大推动了多模态生成与理解任务的发展。一种直接的技术路线是收集人类反馈以构建偏好数据集,用于模型优化[29, 38, 52]。尽管有效,但收集大规模人类反馈耗时且资源密集。因此,另一种流行方法是从有限的偏好数据中学习奖励模型[18, 24, 28, 40, 44, 47, 50]

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











