








 超级会员免费看
超级会员免费看

该文章提出了面向法律推理的大语言模型Unilaw-R1,通过高质量数据集构建、两阶段训练策略和迭代推理机制,在保证轻量化(70亿参数)的同时,解决了法律领域模型的核心痛点,且在权威基准测试中表现优异。
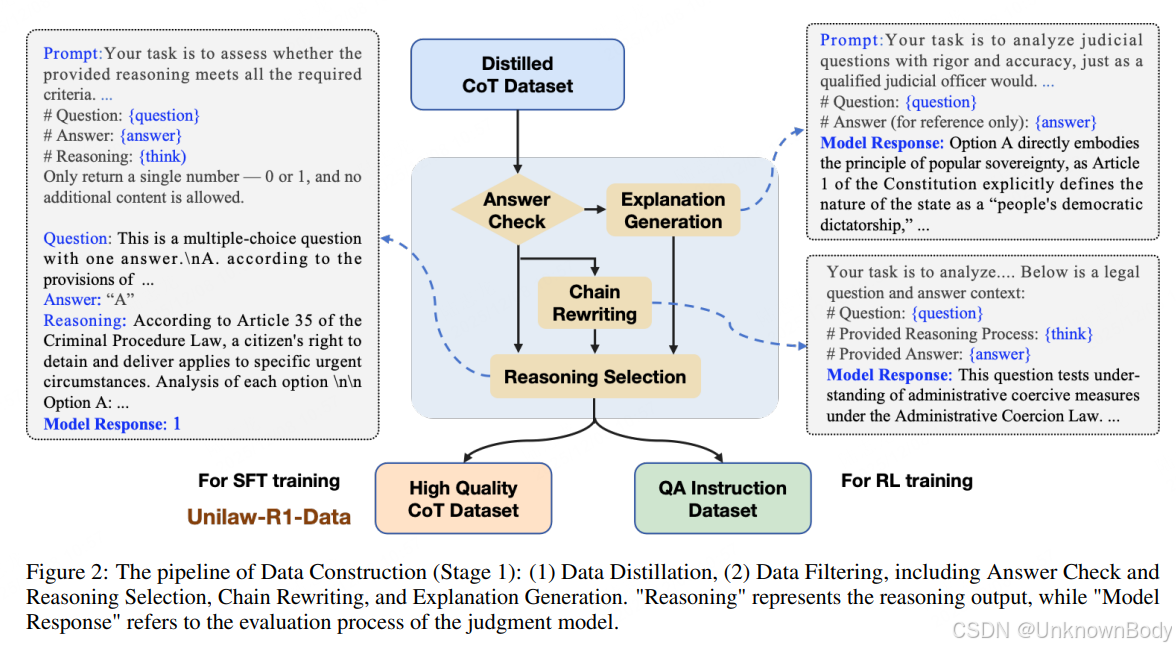
一、文章主要内容总结
- 研究背景:通用推理大语言模型在法律领域应用受限,面临三大核心挑战——法律知识不足、推理逻辑不可靠、业务泛化能力弱,且法律推理需同时满足成文法外部有效性和程序内部一致性。
- 核心解决方案:提出Unilaw-R1模型,以Qwen2.5-7B-Instruct为基础,通过“数据构建-模型训练-迭代推理”三步解决上述挑战。
- 数据构建:打造Unilaw-R1-Data(约1.7K高质量思维链样本)和Unilaw-R1-Eval(法律专用评估基准),数据来源包括开源JEC-QA数据集和2015-2021年中国国家司法考试专有数据,经“答案检查、链条重写、解释生成、推理筛选”四步严格处理。
- 模型训练:采用两阶段策略,先基于Unilaw-R1-Data进行监督微调(SFT),再结合Group Relative Policy Optimization(GRPO)算法进行强化学习(RL),RL阶段设计准确率、格式、法律有效性三重奖励函数。
- 迭代推

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2051
2051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











