







 超级会员免费看
超级会员免费看
摘要
在复杂场景中结合多种感知输入并进行组合推理是人类一项复杂的认知功能。随着多模态大语言模型的发展,近期的基准测试倾向于评估跨多图像的视觉理解能力。然而,它们常常忽略了跨多种感知信息进行组合推理的必要性。为了探究先进模型在复杂场景中整合多种感知输入以进行组合推理的能力,我们引入了两个基准测试:线索视觉问答(CVQA)和密码线索视觉问答(CPVQA)。CVQA包含三种任务类型,用于评估视觉理解和合成能力;CPVQA包含两种任务类型,专注于对视觉数据的准确解释和应用。针对这些基准测试,我们提出了三种即插即用的方法:利用模型输入进行推理、通过带有随机性生成的最小裕度解码来增强推理,以及检索语义相关的视觉信息以实现有效的数据整合。综合结果显示,当前模型在组合推理基准测试中的表现较差,即使是最先进的闭源模型在CVQA上的准确率也仅为33.04%,在CPVQA上更是降至7.38%。值得注意的是,我们的方法提高了模型在组合推理方面的性能,与最先进的闭源模型相比,在CVQA上提升了22.17%,在CPVQA上提升了9.40%,证明了其在复杂场景中增强多感知输入组合推理的有效性。代码将公开。
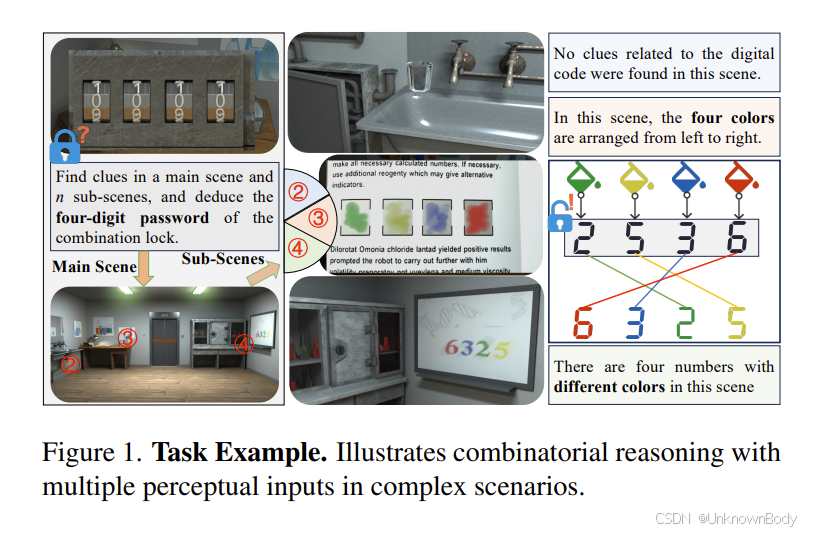
引言
在复杂场景中,人类能够整合多种感知信息进行组合推理。如图1所示,在复杂场景中,颜色序列可用于对彩色数字进行重新排序。近年来,多模态大语言模型(MLLMs)通过将视觉编码器集成到预训练的语言模型(LLMs)中,赋予模型视觉处理能力,推动了视觉语言任务的发展。越来越多的研究关注复

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











