







【图书推荐】《深入探索Mamba模型架构与应用》-优快云博客
在经典的Mamba模型上进行训练固然可以,但是对于普通用户而言,在有限的数据集上进行全新的Mamba生成模型训练确实颇具挑战。这不仅需要深厚的专业知识,还需要大量的时间和计算资源,这些因素都增加了训练的难度。
尽管从头开始训练一个Mamba生成模型是一项艰巨的任务,但作为深度学习的实践者,我们有一个实用且可靠的方法:在已有一定基础的模型上继续训练我们的生成模型。这种被称为迁移学习或微调的方法,在深度学习领域被广泛应用。通过这种方法,我们可以利用预先训练的模型作为基础,通过在其上继续进行训练,以适应特定任务和数据集。这不仅可以节省大量的时间和计算资源,还能提高模型的性能和准确性。
采用这种训练方法,即使是普通用户也能在有限的数据集上训练出高效的Mamba生成模型,从而更好地满足实际应用需求。因此,对于希望在深度学习领域取得成果的用户来说,掌握并应用这种方法至关重要。
8.2.1 什么是微调
微调(Fine-tuning)是深度学习领域的一个重要概念,主要针对预训练模型进行进一步的调整,以适应新的特定任务,如图8-5所示。
下面将详细讲解微调的概念、应用及其实现过程。
1. 微调的概念
预训练模型:预先在大规模无标注数据上通过自监督学习得到的模型,这些模型通常具有对一般自然语言结构良好的理解能力。
微调:在预训练模型的基础上,针对具体下游任务(如文本分类、问答系统、命名实体识别等),使用相对规模较小但有标签的目标数据集对该模型的部分或全部参数进行进一步的训练。
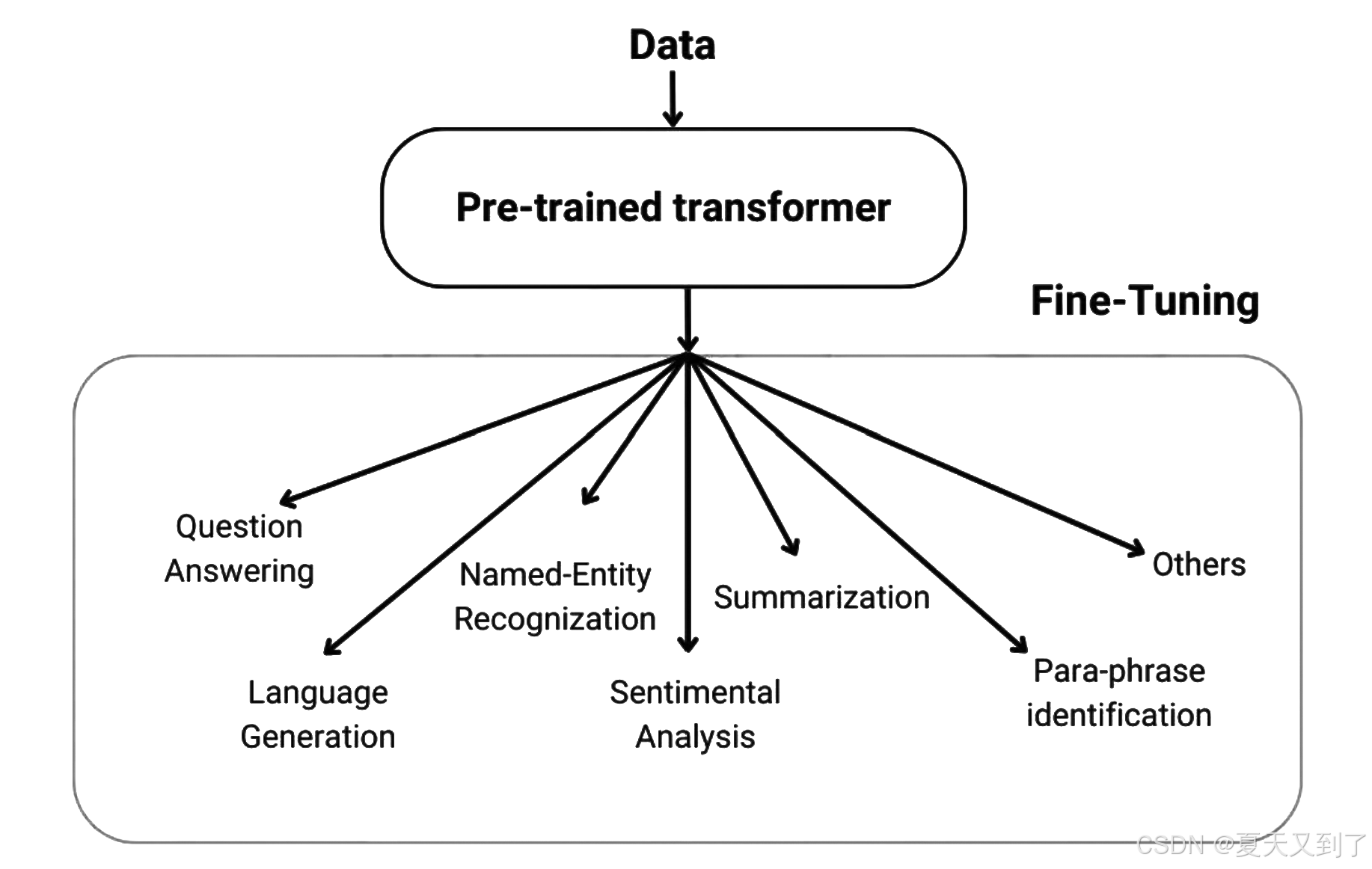 图8-5 微调
图8-5 微调
2. 微调的应用
领域适配:通用预训练模型通常在跨领域的大规模数据上训练,但当应用到金融、医疗、法律等特定行业领域时,性能可能会下降。这是因为这些专业领域有自己独特的语言风格、专业术语和语义关系。通过微调可以使模型更好地捕捉该领域的语言特点,从而提升性能。
任务定制:即使在同一行业领域,不同的任务也可能有差异化的需求。通过针对特定任务进行微调,可以优化模型在该任务上的关键性能指标,如准确率、召回率、F1值等,以满足实际应用需求,如图8-6所示。
图8-6 微调的应用实现
3. 微调的实现过程
具体来看,微调的实现通常包括以下几个步骤。
- 选择预训练模型:根据任务需求选择一个合适的预训练模型作为基础。
- 准备目标数据集:收集并标注针对特定任务的数据集。
- 微调模型:使用目标数据集对预训练模型进行进一步的训练,调整模型的参数以适应新任务。
- 评估与调优:在验证集上评估微调后的模型性能,并根据评估结果进行必要的调优。
- 部署与应用:将微调后的模型部署到实际应用场景中,进行预测和服务。
总的来说,微调是一种高效的模型定制化方法,可以最大限度地发挥预训练模型的潜力,使其在特定任务中展现出卓越的性能。
8.2.2 预训练的Mamba生成模型
首先我们回忆一下在第2章使用的Mamba生成模型,代码如下:
import model
from model import Mamba
from modelscope import snapshot_download,AutoTokenizer
model_dir = snapshot_download('AI-ModelScope/mamba-130m',cache_dir="./mamba/")
mamba_model = Mamba.from_pretrained("./mamba/AI-ModelScope/mamba-130m")
tokenizer = AutoTokenizer.from_pretrained('./mamba/tokenizer')
print(model.generate(mamba_model, tokenizer, '酒店'))
print(tokenizer.vocab)
此时我们以“酒店”开头,并希望输出后续的文本内容,如下所示:
酒店&*……and many others.
可以看到,当前的输出显得杂乱无章,缺乏实质性的意义。但是,我们的目标是利用手头的数据集生成具有实际含义和价值的文本内容。为了实现这一目标,我们计划在原有的Mamba模型的基础上进行重新训练。
在接下来的工作中,我们将专注于调整模型的参数,优化训练过程,并确保我们的数据集得到有效利用。通过重新训练,我们期望Mamba模型能够更准确地捕捉到数据中的内在规律和特征,进而生成更加有意义、连贯的文本。
8.2.3 对预训练模型进行微调
下面我们将使用预训练模型在数据集上进行微调开发,具体来看,一个非常简单的思路就是查看预训练模型的结构并按要求进行修正,作者提供的预训练模型Mamba的基本结构如下:
class Mamba(nn.Module):
def _ _init_ _(self, args: ModelArgs):
"""Full Mamba model."""
super()._ _init_ _()
self.args = args
self.embedding = nn.Embedding(args.vocab_size, args.d_model)
self.layers = nn.ModuleList([ResidualBlock(args) for _ in range(args.n_layer)])
self.norm_f = RMSNorm(args.d_model)
self.lm_head = nn.Linear(args.d_model, args.vocab_size, bias=False)
self.lm_head.weight = self.embedding.weight # Tie output projection to embedding weights.
def forward(self, input_ids):
"""
Args:
input_ids (long tensor): shape (b, l) (See Glossary at top for definitions of b, l, d_in, n...)
Returns:
logits: shape (b, l, vocab_size)
"""
x = self.embedding(input_ids)
for layer in self.layers:
x = layer(x)
x = self.norm_f(x)
logits = self.lm_head(x)
return logits
可以看到,此时的输出结构和我们自定义的Mamba模型基本一致,即将输入层进行Embedding变换后,经过多个SSM的block,最终到head层进行输出。
因此,在具体使用时,我们可以在8.1.3节的模型训练代码上,仅仅对提供的模型进行修改即可,部分代码如下:
...
from model import Mamba
from modelscope import snapshot_download,AutoTokenizer
model_dir = snapshot_download('AI-ModelScope/mamba-130m',cache_dir="./mamba/")
mamba_model = Mamba.from_pretrained("./mamba/AI-ModelScope/mamba-130m")
...
model = mamba_model
...
for epoch in range(3):
pbar = tqdm(train_loader,total=len(train_loader))
for token_inp,token_tgt in pbar:
token_inp = token_inp.to(device)
token_tgt = token_tgt.to(device)
logits = model(token_inp)
torch.save(model.state_dict(), save_path)
另外,读者要注意,我们需要对训练的权重进行保存。
8.2.4 使用微调的预训练模型进行预测
最后,使用微调的模型进行训练,这里最为重要的内容是载入我们训练的权重参数,对其使用如下:
import model
from model import Mamba
#from transformers import AutoTokenizer
import torch
from modelscope import snapshot_download,AutoTokenizer
model_dir = snapshot_download('AI-ModelScope/mamba-130m',cache_dir="./mamba/")
mamba_model = Mamba.from_pretrained("./mamba/AI-ModelScope/mamba-130m")
save_path = "./saver/glm_text_generator.pth"
mamba_model.load_state_dict(torch.load(save_path))
tokenizer = AutoTokenizer.from_pretrained('./mamba/tokenizer')
for _ in range(10):
print(model.generate(mamba_model, tokenizer, '酒店'))
print(model.generate(mamba_model, tokenizer, '位置'))
print("-------------")
此时的部分输出结果如下:
酒店服务还可以。早餐下来也比较好。※酒店
位置在路前,但一开始觉得比较不方便,下次来还真住这里。
-------------
酒店的早餐很一般但价格的希望很快早餐的速度还可以到9点早不过是怀旧时前台
位置很好,出门右走在饭店饭中往往,有一个很贵的餐馆和客房,不错的,又�
-------------
酒店大堂和藏厨部的设施都很正常,早上起来我很快就到酒店,前台服务员非常热情,提
位置不错,位于闹中取静。酒店的早餐不太好,但在门口等了半个小时还是很齐的。�
-------------
酒店的地毯很脏,其他都不错。※酒店内部环境不好,连地毯都没干净,早餐一般
位置比较好(我住的在5楼),早餐还可以※周围环境不错,位置还比较好
可以看到,相对于原有的输出,此时的输出结果已经可以在一定程度上看出表达的意义,并且也符合我们的输入引导词。更多内容读者可以仔细查阅。


















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









