




 本文探讨了处理大数据集的挑战,重点介绍了随机梯度下降、Mini-Batch小批量梯度下降及其收敛性。此外,还讨论了在线学习算法如何适应不断变化的数据,并解释了如何通过减少映射与数据并行来加速训练过程。
本文探讨了处理大数据集的挑战,重点介绍了随机梯度下降、Mini-Batch小批量梯度下降及其收敛性。此外,还讨论了在线学习算法如何适应不断变化的数据,并解释了如何通过减少映射与数据并行来加速训练过程。
目录
1 学习大数据集
在机器学习中,通常情况下,决定因素往往不是最好的算法,而是谁的训练数据最多。

如图所示,当数据量达到一亿时需要很久才能进行梯度下降,上图显示了大数据对于偏差有帮助,对方差帮助较少。因此我们需要找出合理的算法来处理大数据集。
2 随机梯度下降

随机梯度下降算法不需要处理所有训练样本,我们每次迭代只考虑一个训练样本。

具体过程:1,随机打乱所有数据
2,遍历所有样本,使参数对每个样本进行拟合。
这样做虽然中途会出现偏差,但最终会落到一个范围以内。
3 Mini-Batch小批量梯度下降
这个算法介于前两种之间,b是mini-batch size,每次迭代不是用m或1个样本,而是用b个样本:

相较于原始梯度下降算法,不需要遍历所有样本,只要遍历b个就行了。
4 随机梯度下降收敛

如何判断随机梯度下降算法收敛?首先在更新参数去算出代价值,每1000次迭代得到一个均值,并以此画出曲线。
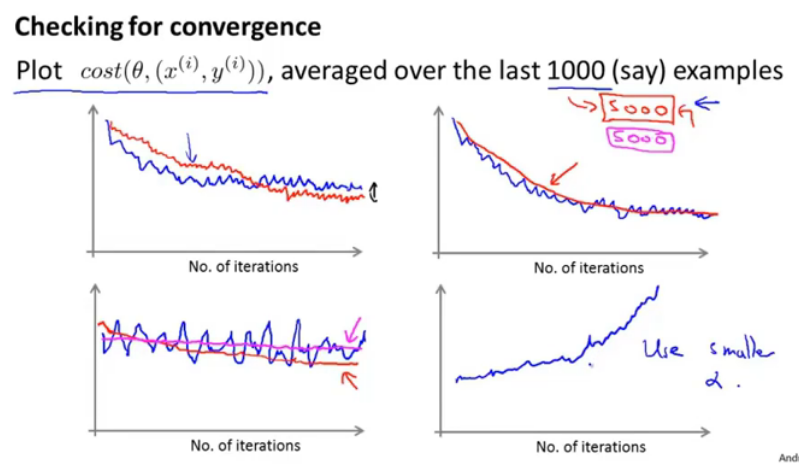
上图中图一的红线表示使用了较小的学习率,图二表示把1000变成了5000,降低了噪声,第三个图表示算法没有在学习,第四个表示算法在发散。
5 在线学习算法

现有一个网站,要根据起点和终点给出运费,并以用户是否选择服务作为y。算法的运算过程是获取用户的(x,y),并使用它更新参数。这个过程与以往不同的是没有固定的数据集,我们不断地学习用户样本然后丢弃,这样的好处是可以持续的追踪用户的喜好。
6 减少映射与数据并行
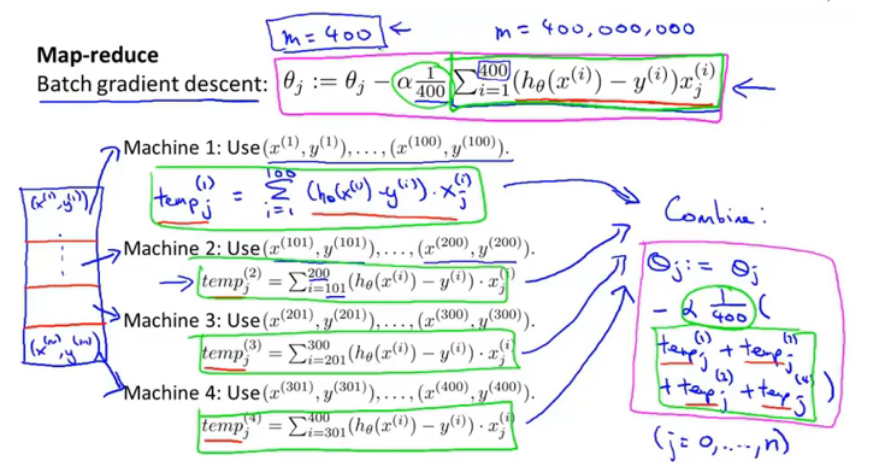
映射化简map-reduce和数据并行在大规模机器学习问题中有广泛应用,它将训练集划分为不同子集,分配给多台机器使用,以此提高速度,最后送到同一个服务器上整合结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









