




 本文介绍了推荐系统中的协同过滤技术,包括低秩矩阵分解和均值规范化等关键算法。通过实例说明了如何训练用户和物品的特征向量,进而预测用户对未评分物品的喜好程度。
本文介绍了推荐系统中的协同过滤技术,包括低秩矩阵分解和均值规范化等关键算法。通过实例说明了如何训练用户和物品的特征向量,进而预测用户对未评分物品的喜好程度。
目录
1 引入问题
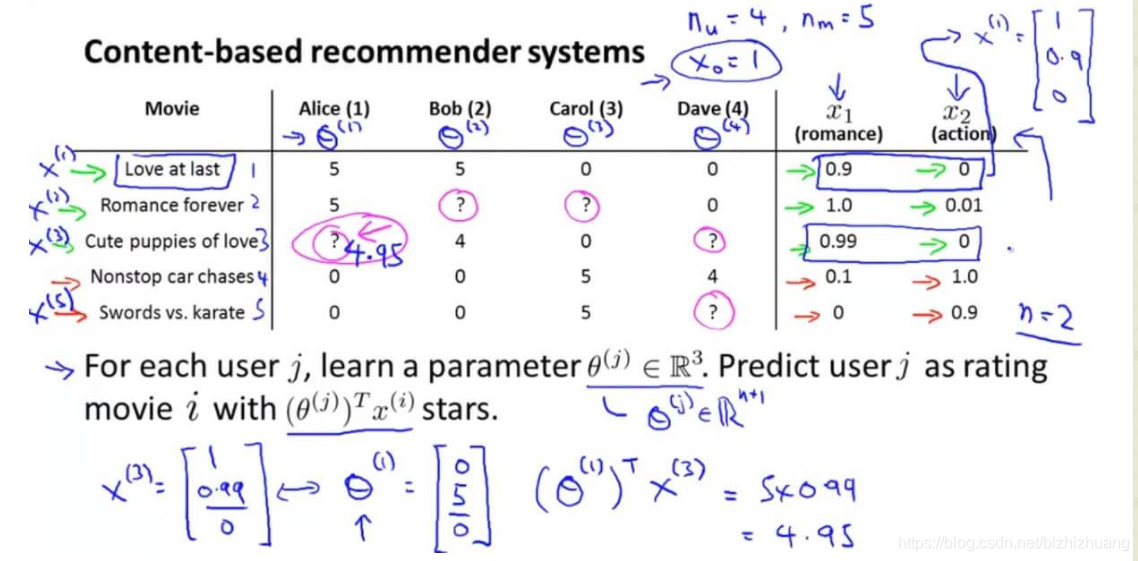 在这个例子里,我们假设每个电影有两个特征,因此n=2,它们组成了一个特征向量。我们对每个用户训练一个线性回归的模型,标记如下
在这个例子里,我们假设每个电影有两个特征,因此n=2,它们组成了一个特征向量。我们对每个用户训练一个线性回归的模型,标记如下

为了学习所有客户,我们对所有用户求和,然后用梯度下降法求最优解。

2 协同过滤
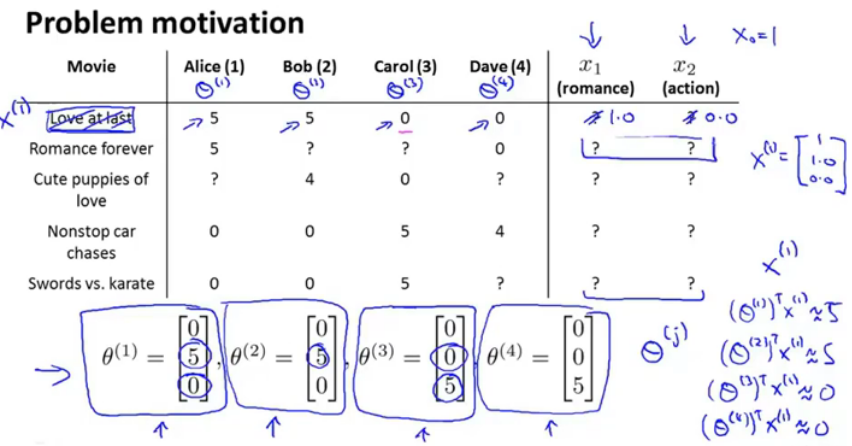
因为电影的特征向量通常情况下我们无法获取,我们可以通过算法来自行学习所需要的特征,假设上面的例子里我们没有x1x2两个特征,只有用户的打分,我们同样根据评分可以得到对应的特征向量,过程与上面的线性回归过程相同。
3 协同过滤算法
上面的过程需要通过两个参数相互反复计算,过于麻烦,我们提出了一个新的算法,它能够同时计算出两个参数
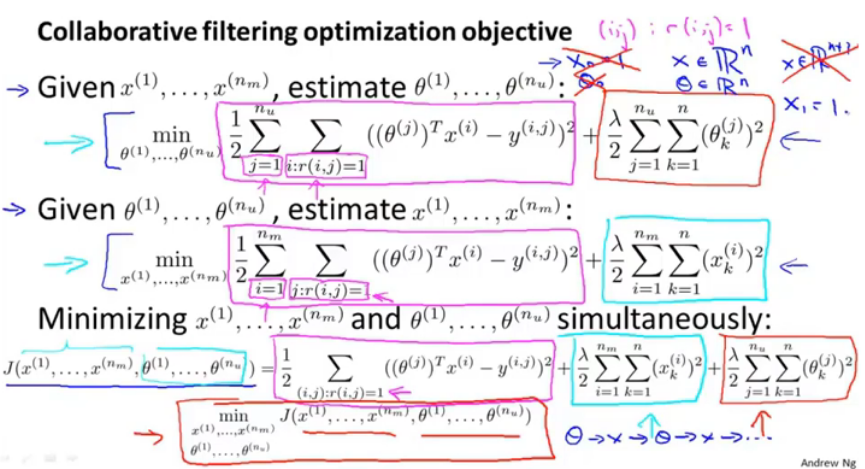
上图中第一个式子对用户对所有电影评分求和,第二个对电影的所有评分求和,第三个合并一二并求最小化值,在这些式子中不存在我们通常置为一的常数项,即x和θ都是n维的。

1,将 x 和 θ 初始化为小的随机值。
2,用梯度下降话最小化代价函数。
3,利用一个用户的参数和一部电影,预测用户对电影的评分。
4 低秩矩阵分解
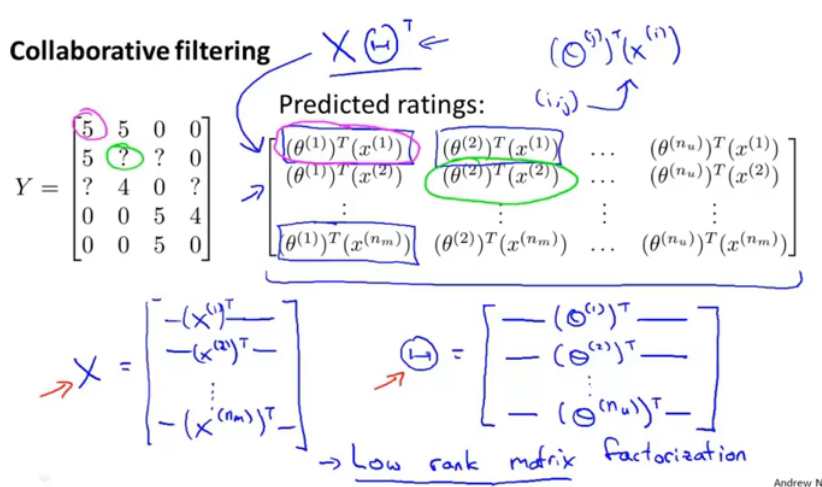
如何简化上述矩阵,将X矩阵表示为左下,θ矩阵表示为右下,整个大矩阵可表示为 XθT。
5 均值规范化
当有一个用户什么电影都没有看过的话,我们用θTx计算最后得到的结果全部都是一样的,并不能很好地推荐哪一部电影给他。此时应当将其他人评分的均值赋给他。
具体操作是先计算每一行的均值,再用每个数据减去均值,得到一个新的评分矩阵,用这个矩阵拟合出θTx,最后结果再加上均值,将这个均值作为无评分用户的权值推荐。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









