







RoMe
摘要
在自动驾驶领域,准确且高效的路面重建是至关重要的.这篇文章提出一种大规模路面重建方案 - RoMe, 通过使用独特的mesh表示方法,RoMe 可以确保重建的路面既准确且与语义无缝对齐.为了应对计算效率上的挑战,我们提出了一种路标采样策略(waypoint sampling strategy),使得 RoMe 能够通过聚焦子区域路面重建,并通过合并来进行更大场景的重建。此外,RoMe还引入了外参优化模块,以增强系统在外参标定不准确情况下的鲁棒性。我们在公开数据集和实际数据上的广泛评估,突显了 RoMe 在速度、精度和鲁棒性方面的优势。例如,从成千上万的图像中恢复 600 × 600 平方米的路面只需 2 个 GPU 小时。值得注意的是,RoMe 的能力不仅限于重建,它在自动驾驶应用中的自动标注任务中也具有重要价值, 同时作者将工作开源: RoMe-Github
介绍
通常道路表面重建主要有两种主要策略: 传统基于计算机视觉的三维重建和基于MLP的隐式重建.
传统基于计算机视觉的三维重建
目前传统三维重建主要采用COLMAP+MVS [1] 这种方式来获得稠密的重建. 本文作者在KAIST数据集,使用车载双目相机的左相机进行重建,结果如下:
Colmap-MVS-KAIST
在使用Colmap遇到的问题以及解决方案:
- 车载相机的运动方向比较单一,对于地面的观测不是特别充分,因此在Colmap在进行初始化时经常会失败. 因此本文作者采用VINS-MONO的方法来获得相机的Pose,同时参考VINS-FUSION融合了GPS,轮速等传感器,进一步提高相机Pose的准确度,然后利用Colmap直接进行三角化.
- Colmap特征提取采用的是SIFT,在一些光照不理想的场景效果不是很理想.因此采用SuperPoint进行特征提取,进一步提高鲁棒性.
同时可以看到基于COLMAP+MVS的重建,路面部分相对来说还是比较稀疏.且在纹理较为均匀的路面,往往会出现噪声并生成不完整的结果.
基于MLP的隐式重建
近年来的进展表明,基于Multi-Layer Perceptions ( MLP )的方法已被应用于逼真重建,类似与Nerf, 3DGS 等。这些方法利用多层感知器(MLP)等工具重建复杂的城市景观。然而,它们对资源的巨大需求使得这些方法在大规模应用中往往不可行。
RoMe
RoMe 从一系列图像中构建出一个全面的 3D 路面网格,并辅以语义标注。每个网格顶点都包含了高度、颜色和语义的详细信息。如下所示:

RoMe主要有三部分组成: 路点采样(Waypoint Sampling), Mesh初始化, 优化,整体架构如下所示:
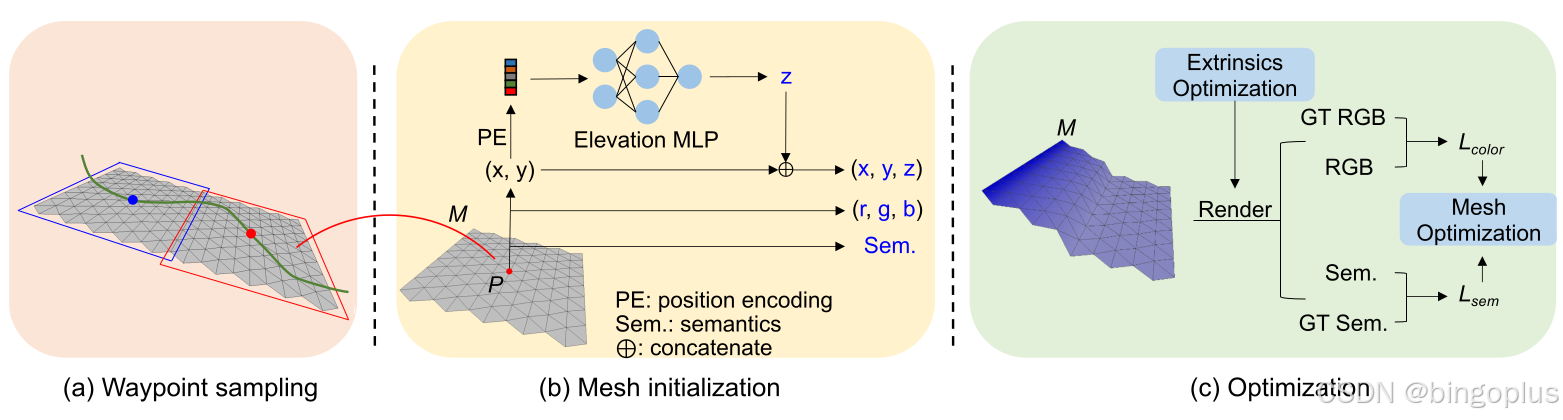
定义:
- Ego: 自车,通常为IMU的安装位置
- Ego pose: 自车在世界坐标系下的位姿.
- Camera pose: 相机在世界坐标系下的位姿.
- Elevation: 道路表面在世界坐标系下的高度
- Waypoints: 将道路划分为子区域的点,便于更快的重建
Mesh Initialization
Mesh初始化首先需要一个准确的Camera Pose,可以通过ORB-SLAM2或者COLMAP获得.其次需要道路语义元素,RoMe选择Mask2Former进行分割,主要是该方法在Cityscapes和Mapillary Vistas这类自动驾驶数据集上表现比较好,语义元素包括:道路,路缘,道路标识,以及车辆等,同时语义分割的结果也可以用来去除车辆以及行人等动态物体.
将ego poses在路面横向进行展开获得半稠密点, 随后考虑ego的高度将这些点投影到地面获得接近地面的高度.通过用这些点对高度 MLP 进行预训练,有助于恢复道路的高度,尤其是在陡坡区域。如下图所是,对一快平坦的路面记作M,它由多个等边三角形元面组成.每个元面包含三个顶点,每个顶点P包含:位置信息(x,y,z), 颜色信息(r,g,b)以及语义信息. 显然通过ego poses得到的地面半稠密点是无法覆盖每个顶点,因此作者将位置编码应用于 (x, y),然后将其输入到高度 MLP 中,以根据公式 1 预测高度 z。使用 MLP(·) 的理由是通过调整位置编码(PE)的频率来控制路面表面的平滑度。
z
=
M
L
P
(
P
E
(
x
,
y
)
)
z = MLP(PE(x,y))
z=MLP(PE(x,y))
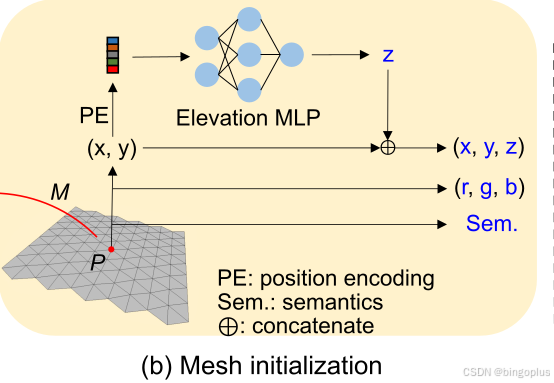
Waypoint Sampling
为了加快大规模场景的重建,RoMe采用了新的路点采样的方法来提高mesh initialization的效率, 路点采样的核心思想是:分而治之,如下图所示,RoMe 将广阔的区域划分为以路标为中心的小型可管理子区域。每个子区域会单独进行重建。一旦所有子区域处理完毕,它们将无缝地合并成完整的路面重建。这种方法提高了计算效率,并确保整个区域的细节得以充分表示.
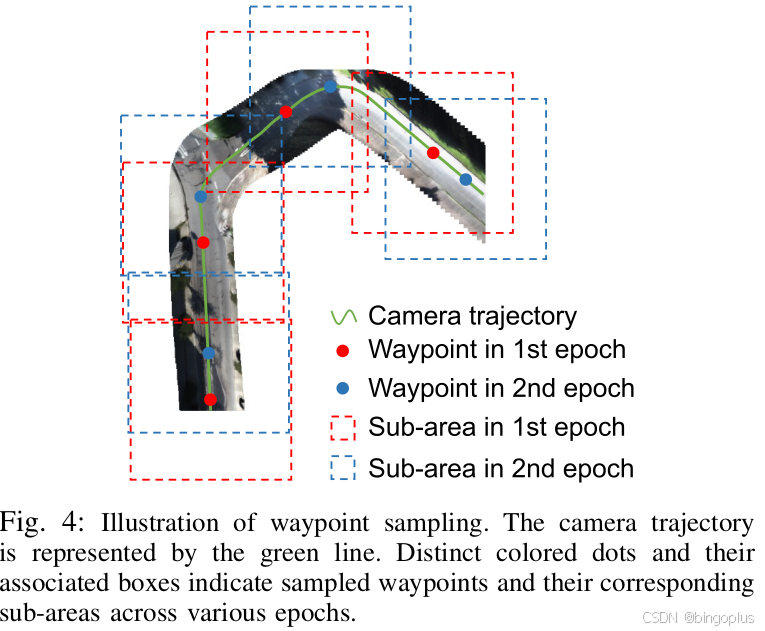
具体的算法细节如下所示,所有的Camera Pose被当作一系列的点云P,给定期望的采样半径 R,最远点采样算法会选择路标 (p₁, p₂, …, pₙ)。接下来的步骤是收集每个路标 pⱼ 半径范围内的所有摄像机位姿 Pᵢⱼ 和图像 Iᵢⱼ,并遍历每个子区域 Aᵢⱼ 进行优化。这个过程会迭代应用,直到所有子区域都被充分覆盖,最终更新整个路面。在实际操作中,每个训练周期的初始路标都会随机选择,以确保不同子区域之间的边界保持一致。

- 内循环用于路标采样。索引 j 遍历每个路标。最远点采样决定了路标的数量。对于一个典型的 300 × 300 重建区域,大约有五个路标。最远点采样的具体步骤如下:
a. 将所有自车位姿收集为点云,包含位置 x, y, z。
b. 从点云中随机选择一个点作为起始点。
c. 给定预设参数半径 R,绘制一个圆形区域作为起始区域。所有位于 R 范围内的点被标记为已选择。
d.从未选择的点中挑选最远的点,并以此为中心绘制一个半径为 R 的圆形区域。
e.重复步骤 (2)-(4),直到所有点云中的点都被选择。 - 外循环用于多轮训练。我们的初步实验(见下图)表明,经过七轮训练可以很好地平衡点的覆盖和计算需求。
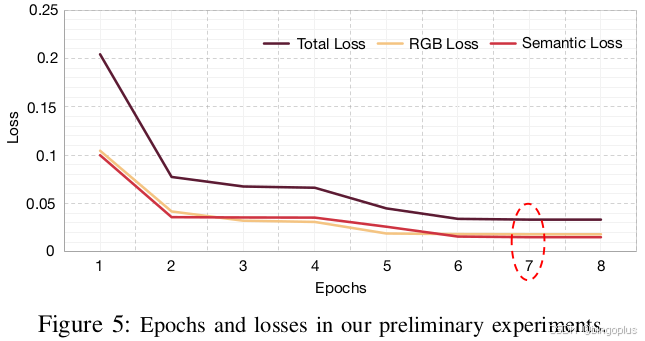
- 停止条件:
内循环的停止条件是路标的数量(5 个路标)。
外循环的停止条件是训练的轮数(7 轮)。
Optimization
优化策略包含两方面:
- 外参优化:旨在提高 RoMe 在不同摄像机设置下的鲁棒性。
- 网格优化:在训练过程中对网格进行优化,关注颜色和语义信息。
外参优化 (Extrinsic Optimization):
外参指的是摄像机在世界坐标系中位置和朝向的参数。它们描述了摄像机的局部坐标系与全局固定坐标系之间的关系。准确的摄像机外部参数并不总是能够得到保证。例如,在某些场景中,nuScenes 数据集中的摄像机外部参数并不总是理想的。自车位姿(Ego poses)指的是自动驾驶车辆(或称自车)在其环境中的位置和朝向。它提供了一个参考坐标系,通过该该坐标系可以对其他物体和地标进行描述。在RoME中将摄像机位姿解耦为车辆的自车位姿和摄像机的外部参数。
摄像机外参描述了车辆坐标系(通常称为自车坐标系)与摄像机坐标系之间的变换。这一变换对于对齐摄像机和车辆上其他传感器捕获的视觉数据至关重要。在 RoMe 中,摄像机外部参数表示为变换矩阵 T = [R|t] ∈ SE(3),其中 R ∈ SO(3) 和 t ∈ R³ 分别表示旋转和位移。由于位移 t 定义在欧几里得空间中,因此它可以很容易地进行优化。
旋转 R 表示为轴-角形式:φ := αω,φ ∈ R³,其中 α 是旋转角度,ω 是归一化的旋转轴。可以通过罗德里格斯公式将其转换为旋转矩阵 R。
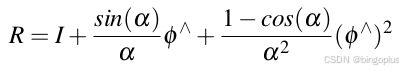
(⋅)∧将一个向量 𝜙转换为一个反对称矩阵(又称为斜对称矩阵):
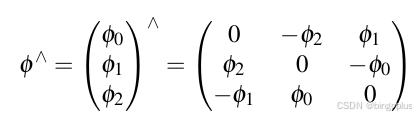
为了实现更快且更容易收敛的优化过程,我们通过优化相对摄像机外参(与标定后的外参相比),具体优化的参数包括旋转角度 𝛼、旋转轴 𝜙和位移 𝑡。
网格优化(Mesh Optimization)
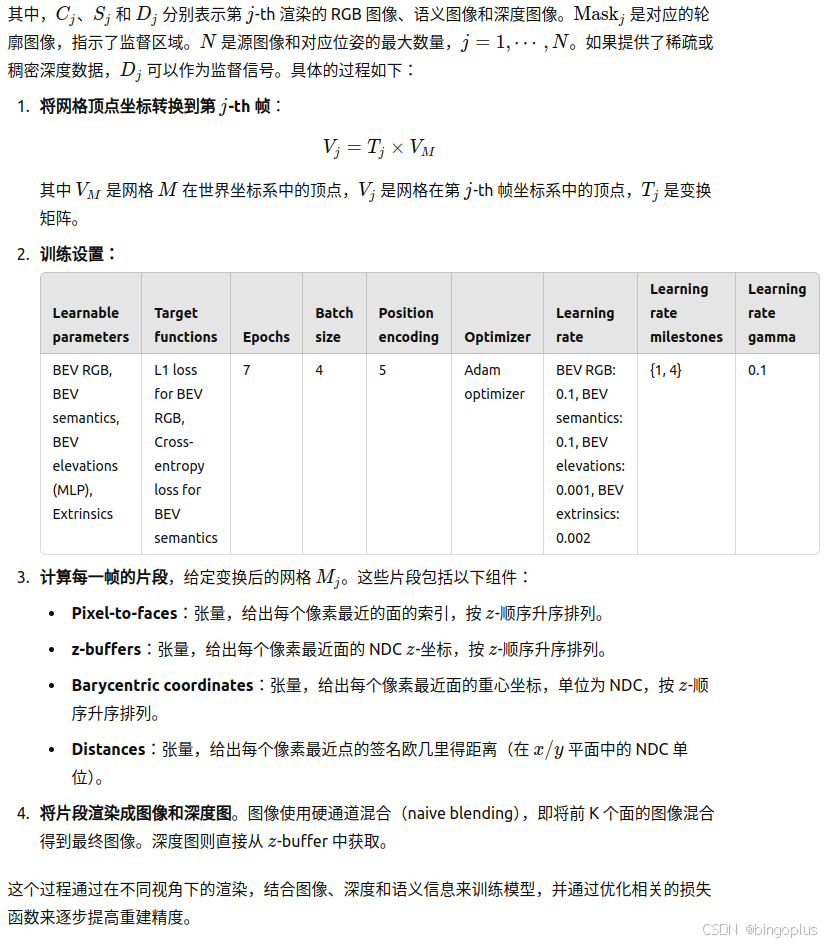
为了推导训练监督,我们首先将源网格 𝑀 输入到pytorch3d可微分渲染器 [2] 中,公式如下所示,应用 MeshRenderer 函数对
𝑀进行处理,以从第 𝑗-th 摄像机位姿 𝜋𝑗获得图像视图的渲染结果。
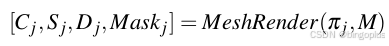

参考文献
[1] Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceed-
ings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113,
2016.
[2] J. Johnson, N. Ravi, J. Reizenstein, D. Novotny, S. Tulsiani, C. Lassner, and S. Branson, “Accelerating 3d deep learning with pytorch3d,” in SIGGRAPH Asia 2020 Courses, 2020, pp. 1–18.


















 49
49

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









