






为什么需要矩阵化向量化运算过程?
numpy在实现内部运算的时候,对矩阵运算过程进行了优化,且优化效果特别明显。如果我们使用的是原始的for循环虽然也可以完成任务,但是频繁的使用for循环将会大大的增加计算时间。我们应该尽量把运算向量化,交给numpy去完成。
举个例子:
一个输入样本X由1000000个特征组成的行向量,现在想计算 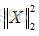 的值。
的值。
其中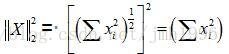
那么有两种写法:
import numpy as np
import time
def mod1(X):
sum=0
l=np.shape(X)[1]
for i in range(l):
sum=sum+X[0][i]**2
return sum
def mod2(X):
return np.matmul(X,np.transpose(X))
x=np.random.rand(1,1000000)
start=time.clock()
r1=mod1(x)
end1=time.clock()
r2=mod2(x)
end2=time.clock()
print(r1,(end1-start)/1000.0)
print(r2,(end2-end1)/1000.0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
mod1(X)使用的是for循环,这是一种特别容易想到的实现方法。
mod2(X)则将输入看作一个行向量,通过公式X·X^T 来计算。
我们看运行结果:
333247.873178 0.0011849279121984469
[[ 333247.87317754]] 7.115206039483013e-07
- 1
- 2
可以看到,使用向量化后的方法是10^-7这个数量级,而使用for循环的是10^-3这个数量级。运算时间差别也是有点大。
如何进行矩阵化、向量化
首先我们先考虑如何让单个输入样本向量化。
举个例子: 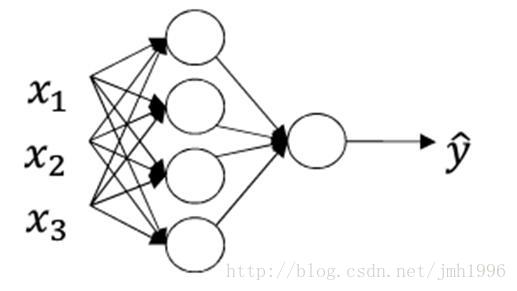




其它
该方法同时与适用于tensorflow中,因为tensorflow里面的矩阵运算模块就是基于numpy实现。

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









