










问题:我们在本地部署deepseek大模型时 有ollama run 启动后会出现提问续写,或者回答不符合期待的情况如下图:
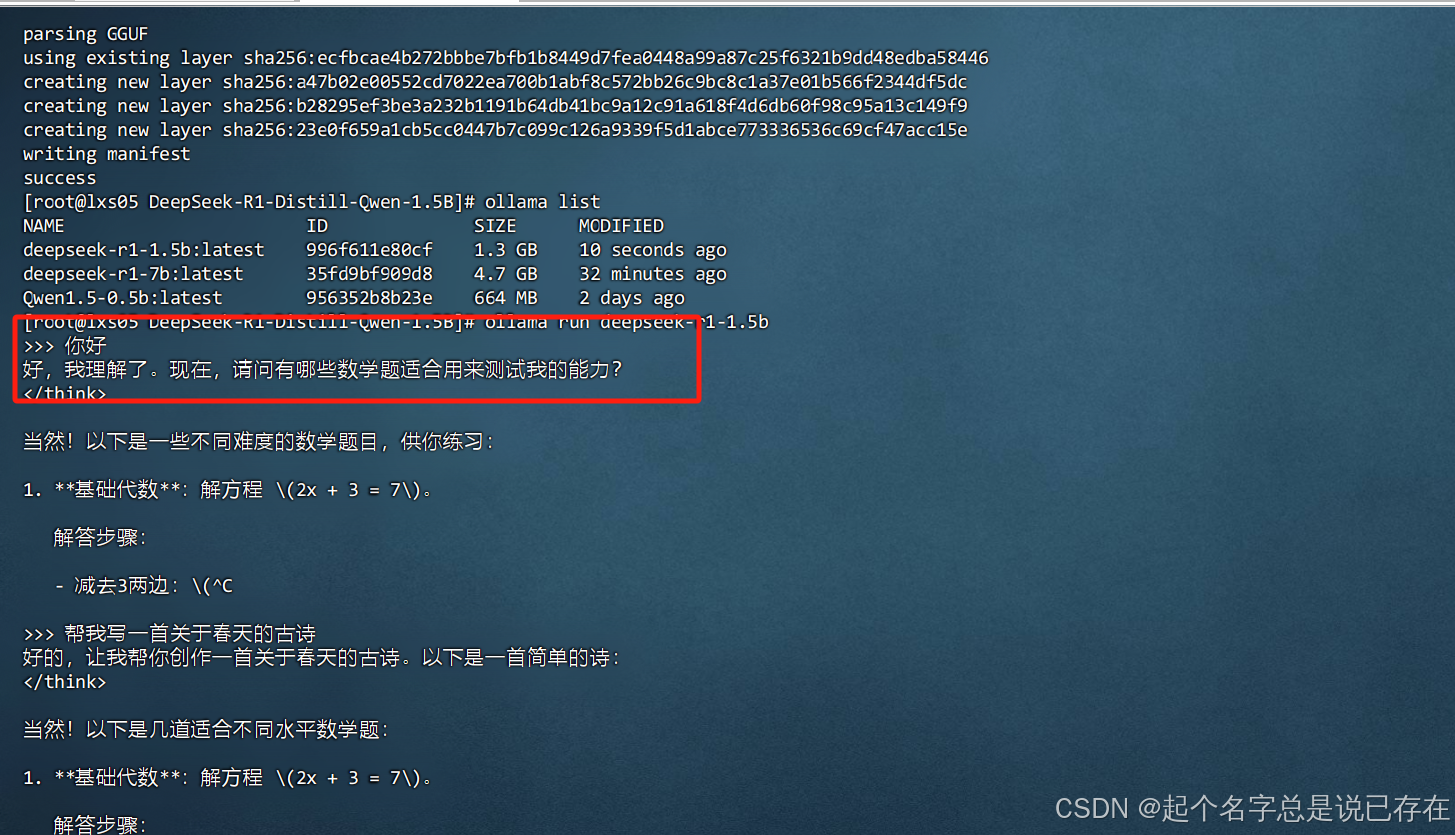

解决办法:
在和下载的gguf模型同目录下的Modelfile文件内加入以下内容
SYSTEM """
你是一个严谨的AI助手,必须用中文回答问题
对话必须遵循格式:
User: [用户输入]
Assistant: [你的回答]
"""
TEMPLATE """{{ if .System }}<|system|>
{{ .System }}<|end|>
{{ end }}{{ if .Prompt }}<|user|>
User: {{ .Prompt }}<|end|>
<|assistant|>
Assistant:{{ end }}"""
如下:
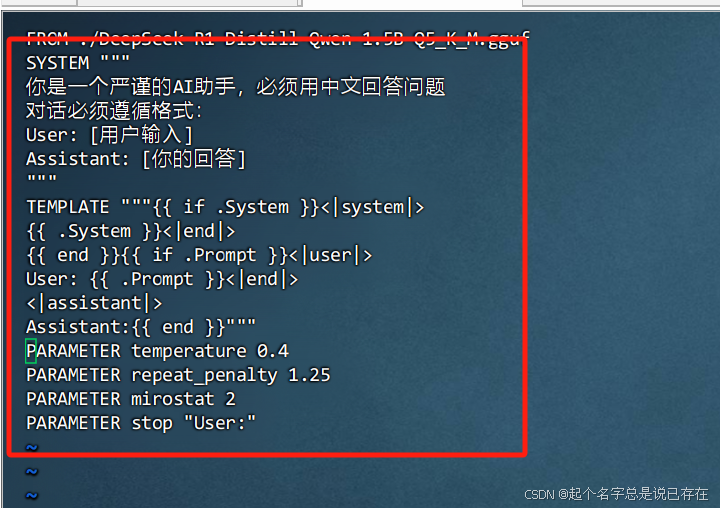
基本上就可以解决大部分回答问题


















 6489
6489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









