



本文系统介绍了AI大模型技术演进,从AIGC的单模态、多模态特性,到解决实时性问题的RAG技术,再到赋予AI工具使用能力的Function Calling。进一步探讨了智能体Agent的闭环工作流程,以及MCP协议作为标准化接口如何解决AI应用生态整合难题,为AI技术发展提供统一框架。
一、前言
为啥我会写这篇文章?是因为我前几天看到一个报告,报告显示,大部分人还只是停留在简单与模型对话,甚至只有2%的人开发过智能体,更离谱的是30%多仅仅是听说过。表明整体AI技能基础相对薄弱。
技术圈针对AI已经到了疯癫的程度,这份报告颠覆了我之前的看法,以为AI如干柴烈火之势的发展,大家应该或多或少都知道一些相关的知识,但在技术圈往往会出现幸存者偏差,所以老周得出来写一篇AI相关技术的普及知识。
随着AI技术发展迅猛,日新月异。大语言模型(LLM)、AIGC、多模态、RAG、Agent、MCP等各种相关概念层出不穷,极易混淆。我 这次不讲太多原理性的东西,作为技术科普文来聊一聊这其中的关系。
二、AIGC
2.1 单模态
我们大部分人都是从ChatGPT问世开始接触AI的。刚开始用ChatGPT的时候,我们体验的其实是一种文生文的能力。比如你输入一句话,模型给你生成一段文字回应。
不管是我们平时写代码、还是写文章,都是AI根据你的输入文字(提示词Prompt),生成另一段文字。这种让AI自动生成内容的能力,就叫做AIGC。
啥叫AIGC呢?下面来自百度百科的回答:
AIGC(Artificial Intelligence Generated Content)——生成式人工智能,是指基于生成对抗网络、大型预训练模型等人工智能的技术方法,通过已有数据的学习和识别,以适当的泛化能力生成相关内容的技术。 AIGC技术的核心思想是利用人工智能算法生成具有一定创意和质量的内容。
老周用大白话说就是:用AI自动生成“人类常干的活”。
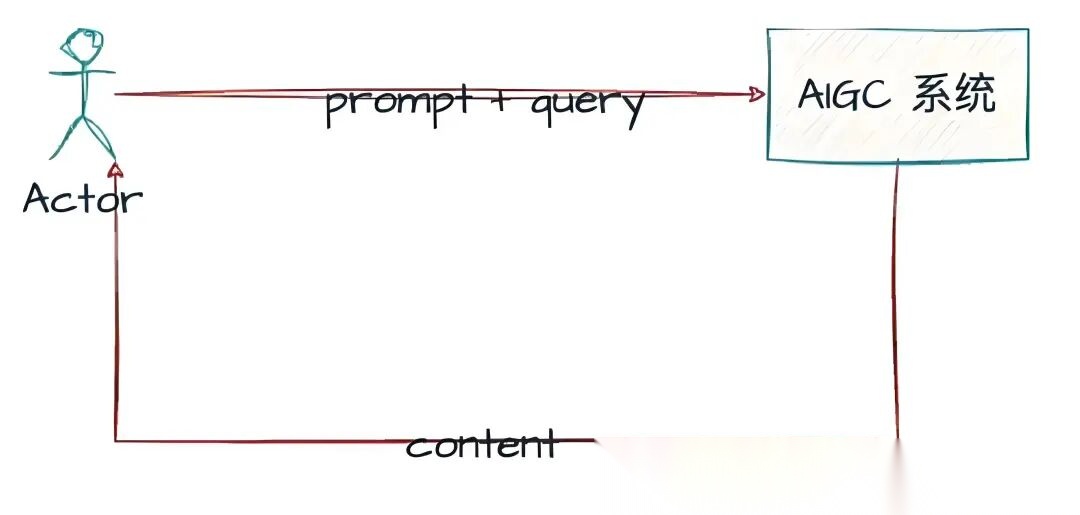 单模态。
单模态。
2.2 多模态
随着AI的进化,不只是文生文,像文生图、图生文、文生视频、图生视频等也都逐渐支持了,而这种支持多种类型消息的,就被称为多模态。比如现在的GPT-5。而这些多模态模型,才是真正让AI从工具进化成助手的关键。

AIGC不管单模态还是多模态,有两个天生的限制:
- 不具备实时性:LLM是离线训练的,一旦训练完成后,它们无法获得新的信息。因此,它们无法回答训练数据时间点之后发生的事件,比如“今天的最新新闻”。
- 不会使用工具:最初的AIGC只可以从现在的知识库中获取内容,而不会查询最新的信息,也不能调用API。
因此,这就引出了两个技术方向,一个叫RAG,一个叫Function Call。
2.3 RAG 技术
RAG(Retrieval-Augmented Generation,检索增强生成) 技术,它是一种人工智能(AI)框架,结合了信息检索和生成式语言模型的能力,以提高响应的准确性和相关性。
核心思想:当 LLM 需要回答一个问题或生成文本时,不是仅依赖其内部训练时学到的知识,而是先从一个外部知识库中检索出相关的信息片段,然后将这些检索到的信息与原始问题/指令一起提供给LLM,让LLM基于这些最新、最相关的上下文信息来生成更准确、更可靠、更少幻觉的答案。
通俗的讲:原来模型靠死记硬背,现在它成了会“看资料答题”的开卷考试了。
RAG的工作原理:
- 检索(Retrieval): 系统首先识别用户查询中的关键词,并使用一个检索模型在大型数据集(如文档库、数据库或互联网)中查找与查询最相关的文本片段。
- 增强(Augmented): 检索到的信息被整合到原始的用户提示(prompt)中,为语言模型提供额外的上下文信息。
- 生成(Generation): 大型语言模型接收到增强后的提示,并利用这些检索到的事实信息来生成一个更丰富、更准确且与用户需求更贴切的回答。
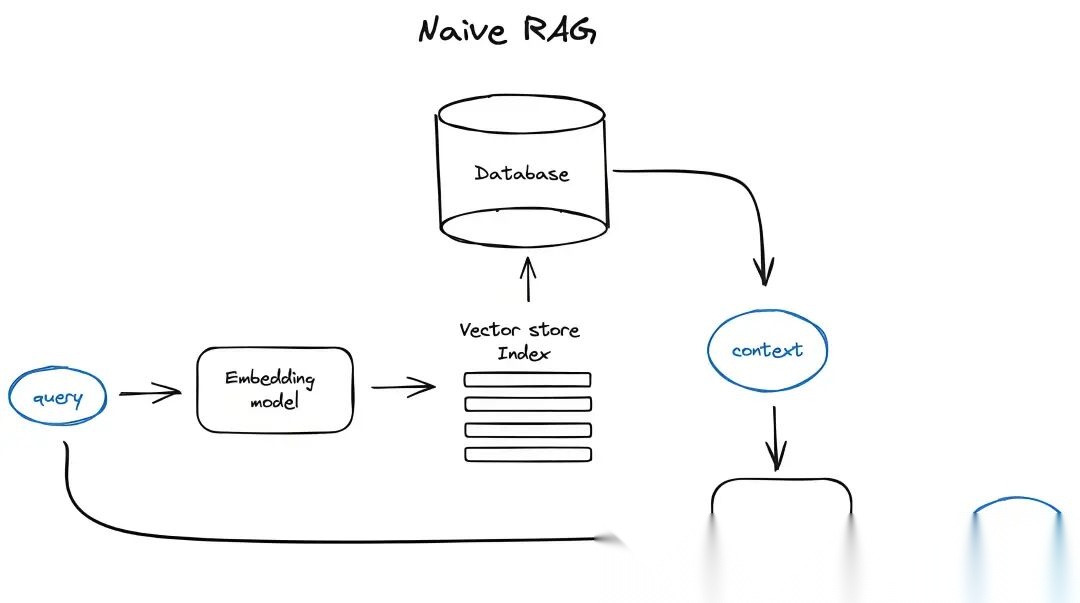
这是原始RAG最经典的一张图了,当然后续还有进阶RAG和高级RAG,这块单独还能出一篇,为了有些新手看的没那么复杂,老周这里把后面两个屏蔽掉了。无非在检索前做些优化(查询路由、查询重写、查询扩展)、检索后优化(重排序、过滤、聚合)。
假如我想查询现在的天气?RAG只会根据现在的资料与知识来回答现在的天气,但天气是实时变化的,如何才能做到真正的查询最新的天气呢?
接下来就轮到**Function Calling(函数调用)**出场了。
2.4 Function Calling
Function Calling就是让模型具备调用工具的能力
在日常对话中,大模型通常只需返回文字答案。但当用户提出诸如“帮我查一下明天北京的天气”这类超出模型内置知识范围的问题时,就需要借助 Function Calling,即让 AI 调用外部工具来完成任务。
Function Calling 的核心作用在于让模型具备以下能力:
- 判断当前问题是否需要使用工具
- 自动提取参数,并以结构化 JSON 形式生成调用指令
- 将调用交由程序执行,并接收返回结果,用于后续生成回复。
举个栗子:
“我明天要去杭州旅游,请帮我查天气”
传统的LLM:
对不起,我只能提供截至2025年10月的信息。
支持RAG的模型:
明天北京24℃,小雨。(它查了资料,但没动手)
支持Function Calling的模型:
它判断你这个请求,需要调用一个叫获取天气的函数,然后自动生成参数“city=杭州”,调用完天气API -> 拿到结果 -> 生成回复:“明天杭州24℃,小雨,建议带伞”。
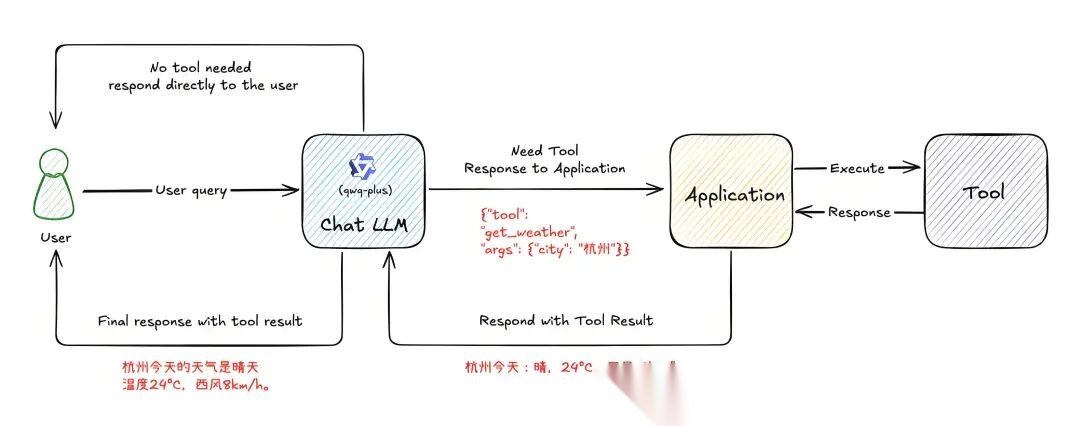
本质上,大模型通过自然语言理解用户意图:要完成什么任务、需要哪些信息。它会自动从对话中提取出关键参数。随后,用户的程序可根据这些参数调用对应的函数完成任务,并将执行结果返回给模型,由模型生成最终回复。
因此,Function Calling是AI走向智能体的关键。
三、智能体Agent
接下来我们来说一说传说中的“人工智能——智能体Agent。
前面咱们说了,Function Calling让模型拥有了“动手能力”。但是你会发现,现实世界的任务,往往不是一句话、调一次函数就能搞定的。
比如说你问它:我十一想自驾从上海去深圳旅游,帮我规划下出行方案。一个聪明的AI应该怎么做?理想流程可能是这样的:
- 查深圳十一当天的天气(看是否适合出行)
- 查从上海到深圳的高速路况
- 查加油站分布和服务区情况
- 安排中途住宿
- 综合输出一份旅游行程建议
可以理解成:它会思考、规划、决策、执行,真正具备了“完成任务”的闭环能力。
通过一张Agent流程图展示如下:
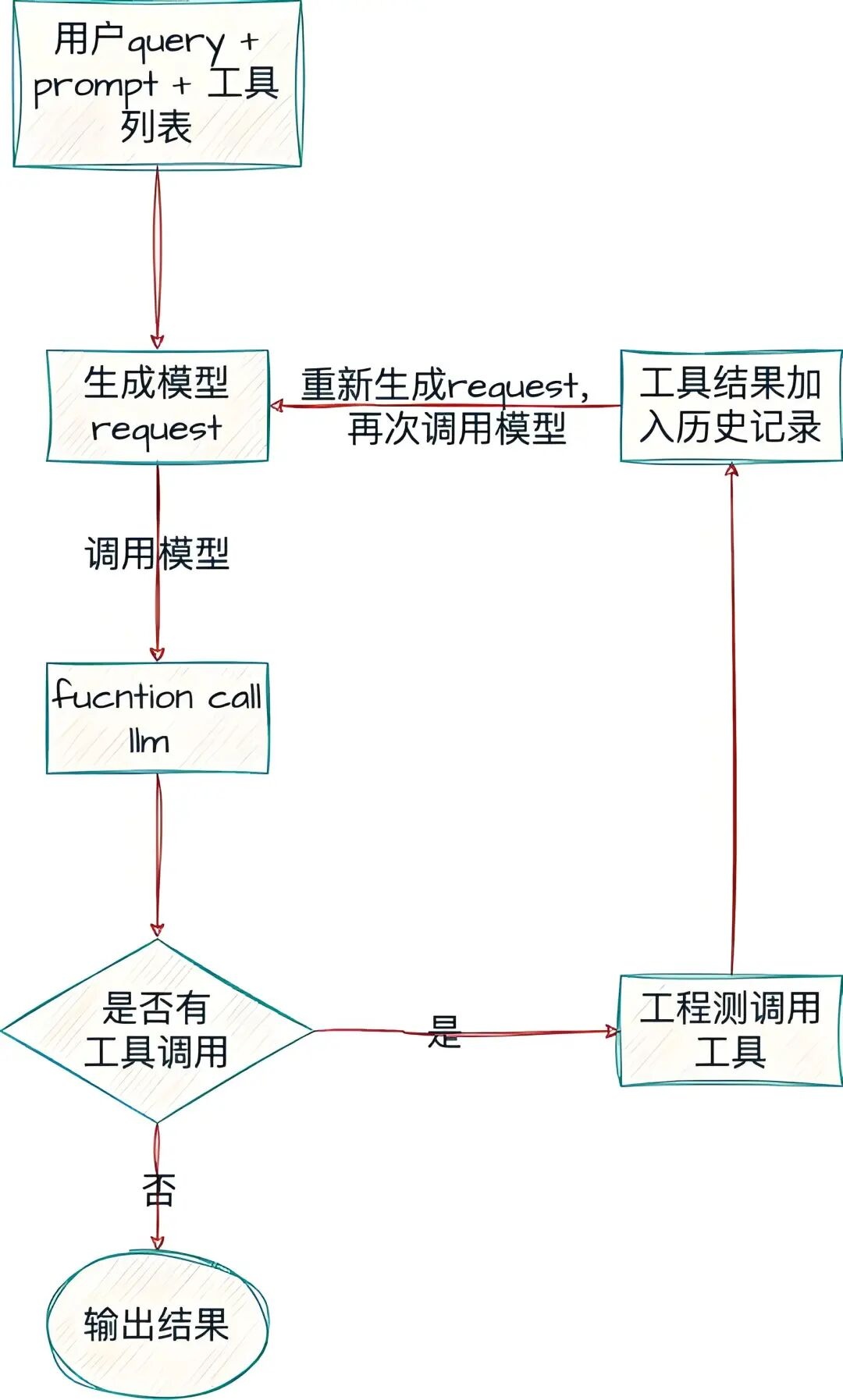
并且,这整个流程可以重复多轮,直到目标完成。
以“十一从上海自驾去深圳旅游为例”,它可能经历这样的Agent执行链:
- 查询天气→如果有雨,提醒注意安全
- 查询路线→如果太远,中途加一站住宿
- 住宿安排→查附近酒店并给出建议
- 最终输出一个可执行的旅游计划
这就是Agent的特性:不是你一步步告诉它怎么干,而是它自己规划该怎么干,直接给你最终的规划和结果。
但是各家厂商大力发展Agent的同时,各自有各自的标准,当Agent越来越多,调用的工具越来越多、系统越来越复杂的时候,如何让模型可以按照统一的标准,低成本地接入更多工具呢?
答案就是:MCP协议!
四、MCP
4.1 什么是 MCP
MCP模型上下文协议(Model Context Protocol,简称MCP)是一个由Anthropic在2024年11月25日开源的一个开放的、通用的、有共识的协议标准。
Anthropic公司是由前OpenAI核心人员成立的人工智能公司,其发布的Claude系列模型是为数较少的可以和GPT系列抗衡的模型。
4.2 为什么需要MCP
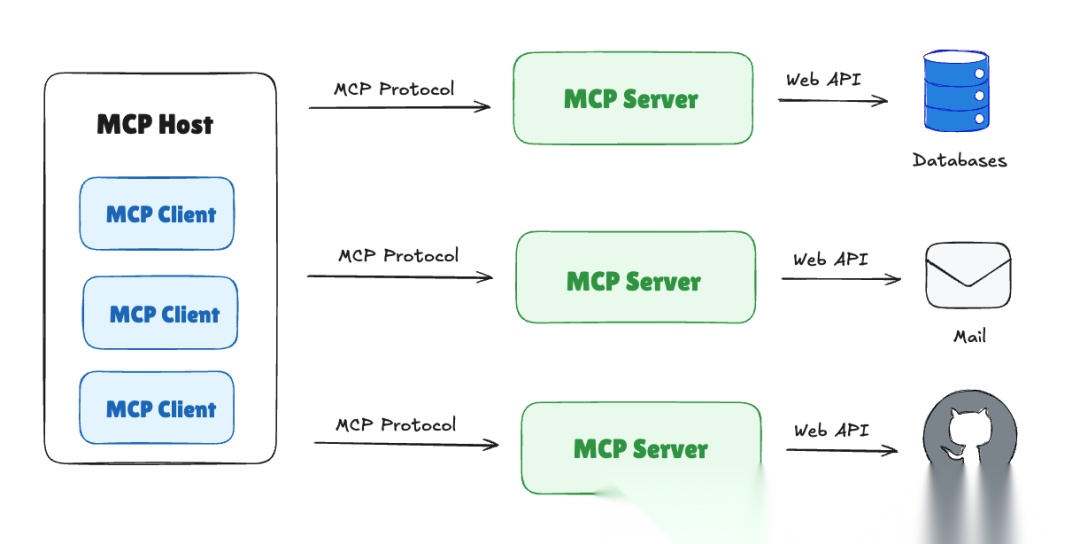
MCP协议旨在解决大型语言模型(LLM)与外部数据源、工具间的集成难题,被比喻为“AI应用的USB - C接口”。
类比来看,不同的AI助手就像不同的电子设备,以前每个设备需要不同的数据线连不同的外设(比如老式手机数据线各不相同),而MCP提供了一个统一的细窄接口,让AI能够即插即用各种外设。例如,通过MCP,一个AI助手今天可以连U盘(数据库),明天插打印机(邮件系统),后天接显示器(报告生成)——接口都一样,只是功能不同。就像USB-C让我们少了无数转换头和线缆,MCP也让AI集成少了无数专有API和脚本。对于终端用户来说,这意味着AI助手将变得更加多才多艺且使用方便,因为背后复杂的连接都被这个看不见的"USB-C"标准屏蔽掉了。
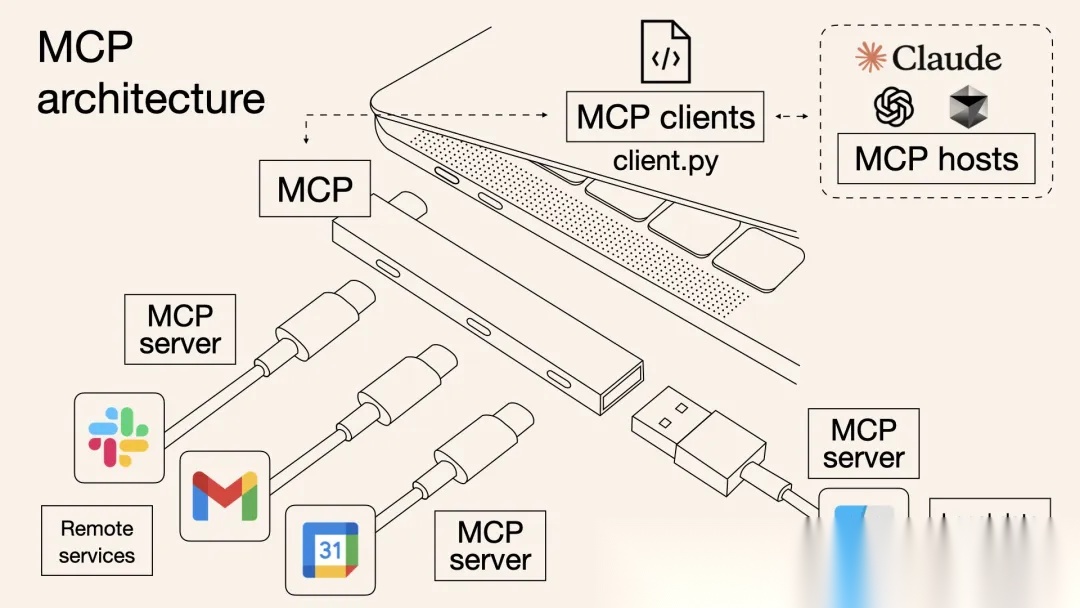
在 MCP 协议没有推出之前:
- 智能体开发平台需要单独的插件配置和插件执行模型,以屏蔽不通工具之间的协议差异,提供统一的接口给 Agent 使用;
- 开发者如果要增加自定义的工具,需要按照平台规定的 http 协议实现工具。并且不同的平台之间的协议可能不同;
- M×N 问题”:每新增一个工具或模型,需重新开发全套接口,导致开发成本激增、系统脆弱;
- 功能割裂:AI 模型无法跨工具协作(如同时操作 Excel 和数据库),用户需手动切换平台。
没有标准,整个行业生态很难有大的发展,所以 MCP 作为一种标准的出现,是 AI 发展的必然需求。
总结:MCP 如何重塑 AI 范式:
 4.3 MCP的核心原理和技术架构
4.3 MCP的核心原理和技术架构
4.3.1 核心架构
MCP采用客户端-服务器的分布式架构,它将 LLM 与资源之间的通信划分为三个主要部分:客户端、服务器和资源。客户端负责发送请求给 MCP 服务器,服务器则将这些请求转发给相应的资源。这种分层的设计使得 MCP 协议能够更好地控制访问权限,确保只有经过授权的用户才能访问特定的资源。官方架构图如下:
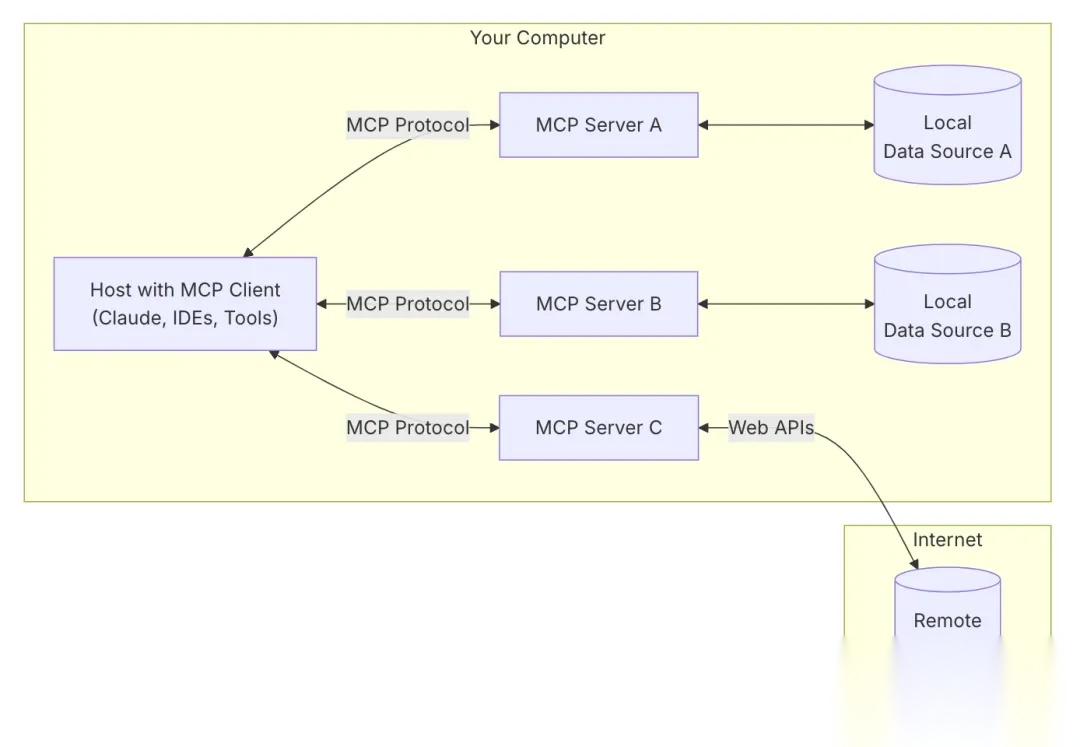
- MCP Host(主机应用):Hosts 是指 LLM 启动连接的应用程序,像Cursor、Claude、Desktop、Cline 这样的应用程序。
- MCP Client(客户端):客户端是用来在 Hosts 应用程序内维护与 Server 之间 1:1 连接。一个主机应用中可以运行多个MCP客户端,从而同时连接多个不同的服务器。
- MCP Server(服务器):独立运行的轻量程序,通过标准化的协议,为客户端提供上下文、工具和提示,是MCP服务的核心。
- 本地数据源:本地的文件、数据库和 API。
- 远程服务:外部的文件、数据库和 API。
这种架构下,AI主机通过MCP客户端同时连接多个MCP服务器,每个服务器各司其职,提供对一种数据源或应用的标准化接入。这样设计有几个好处:一是模块化,增加或移除某个数据源只需启用或停用对应的服务器,不影响AI主体或其他部分;二是解耦,AI模型与具体数据源实现隔离开,通过协议交互,不直接依赖数据源的内部细节;三是双向通信,不仅AI可以请求数据源,某些情况下数据源也能要求AI执行操作或生成内容,从而支持更复杂的交互流程。
4.3.2 工作流程
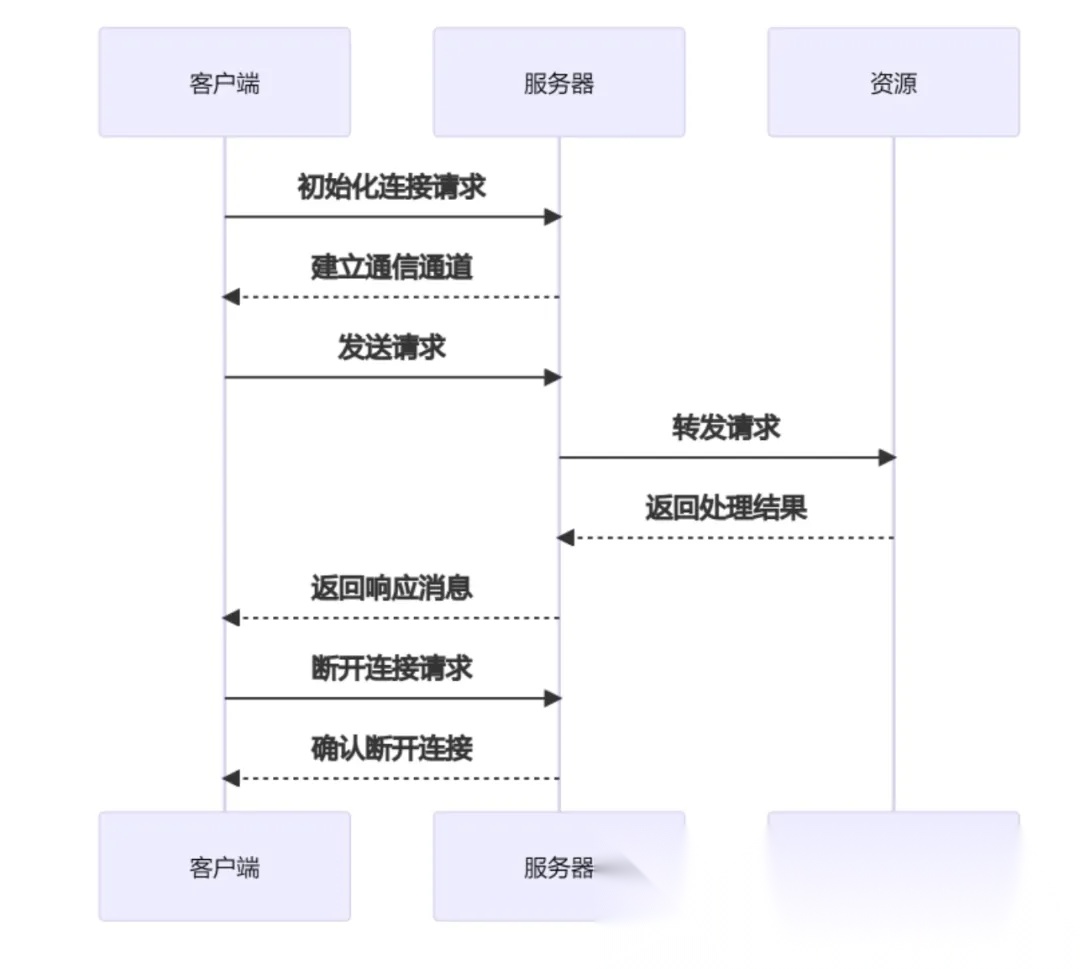
- 初始化连接:客户端向服务器发送连接请求,建立通信通道。
- 发送请求:客户端根据需求构建请求消息,并发送给服务器。
- 处理请求:服务器接收到请求后,解析请求内容,执行相应的操作(如查询数据库、读取文件等)。
- 返回结果:服务器将处理结果封装成响应消息,发送回客户端。
- 断开连接:任务完成后,客户端可以主动关闭连接或等待服务器超时关闭。
4.3.3 通信方式
MCP定义了一套基于JSON-RPC 2.0的消息通信协议。核心特点如下:
- 传输灵活:原生支持两种传输方式——进程管道的STDIO(本地场景)和SSE+HTTP POST(网络通信),同时允许开发者自定义其他传输通道。
- 消息透明:采用纯JSON格式封装三种消息类型——请求(带唯一ID)、响应(含结果/错误)和通知(无回复)。每条消息包含方法名和参数,类似函数调用,直观表达"执行操作/获取数据"等行为。
- 开发友好:相比二进制协议(如gRPC),JSON消息可人工阅读,配合结构化日志更易调试。协议层自动处理请求响应匹配、错误传递和并发管理,开发者只需关注业务逻辑。
关键机制 – “Primitives”(原语)概念:MCP将AI与外部系统交互的内容抽象为几类原语,以此规范客户端和服务器各自能提供的功能。
MCP通讯模式:
- STDIO(Standard Input and Output):是最基本的输入输出方式,广泛应用于命令行工具、脚本编程以及本地调试过程中。它通过标准输入、输出和错误流来进行数据的传输。
- SSE(Server - Sent Events):是一种基于HTTP协议的数据流传输方式,主要用在远程服务上,Client使用SSE与Server进行通讯,特别适合需要持续更新的实时场景。
- Streamable HTTP:是一种基于HTTP协议的流式传输技术,专门用于大文件(如视频、音频)的分段传输。与SSE不同,Streamable HTTP允许文件在传输的同时被处理,使客户端可以边接收数据边处理,避免等待整个文件加载完成。
MCP服务器可以提供三种原语:
- Prompts(提示):预先编写的提示词或模板,相当于一段指导性文字片段,可以插入到模型的输入中去影响其行为。例如服务器可以提供一个"代码审查提示模板",供模型在阅读代码时使用。
- Resources(资源):结构化的数据或文档内容,可供客户端读取并提供给模型作为上下文。例如从数据库查询到的一条记录、用户的笔记文档内容等,都是资源类型。资源类似于"只读文件",模型可以请求某个资源,服务器会返回相应的数据内容。
- Tools(工具):可以被模型调用的可执行操作或函数。这是MCP最强大也最具互动性的部分,模型可以要求服务器执行某个工具函数来获取信息或改变外部状态,比如调用"发送邮件"工具发送一封邮件,调用"查询天气"工具获取天气数据等。由于工具调用可能带来副作用和安全风险,MCP规定模型调用工具必须经由用户批准后才执行。换言之,工具就像模型可用的"按键",但每次按键需要真人确认,避免模型滥用外部操作权限。
MCP客户端提供两种原语能力用于辅助服务器完成复杂任务:
- Roots(根):这是一种由客户端提供的文件系统入口或句柄。服务器可以通过Root来访问客户端这侧的本地文件或目录内容。例如客户端可以授权服务器读取某个文件夹(作为Root),那么服务器就能代表模型浏览那个文件夹下的文件内容(通常仍以资源形式提供给模型)。Roots机制确保服务器只能访问经授权的本地数据范围,增强安全性。
- Sampling(采样):这一机制允许服务器向客户端发起请求,要求客户端这侧的LLM模型生成一段文本(即一次补全/推理)。简单说,服务器也可以"反过来"调用模型,让模型基于一些额外提示执行推理。Sampling可以用于构建多轮交互的智能Agent:服务器在执行某工具过程中,发现需要模型进一步推理决定下一步时,就可以用Sampling请求模型产出结果,再继续后续操作。不过Anthropic也强调应谨慎使用这一机制,始终保持人类在环监督,以避免AI代理失控循环调用模型。Sampling机制并非所有MCP服务器均支持,需依赖客户端实现。
通过上述原语分类,MCP清晰地定义了模型与外部交互的意图类型。例如,让模型获取一段参考资料应该作为Resource提供,而不是混同于调用Tool;又如要求模型执行某操作就用Tool明确表示。这样的设计使AI系统的上下文管理更结构化:模型知道某段信息是只读资料还是可执行操作,用户也能对不同类型请求进行针对性地审批或监控。这比起简单地给模型一个隐式"工具插件"要透明得多。Anthropic的开发者指出,他们最初也考虑过是否把所有交互都当作"工具调用"统一处理,但最终认为Prompt和Resource这两类原语有其独特意义,能表达不同用途的功能,因此保留了多元的原语概念。
4.3.4 MCP现状及问题
- 问题1:MCP服务的配置,开关通常需要手动操作,使用方式还不够智能,如果开启大量的MCP服务,客户端如果第一次将所有工具信息都发给大模型让大模型来抉择,会浪费大量Tokens。
- 问题2:MCP只是解决了协议的问题,工具的稳定性很重要,调用工具时服务不可用非常影响用户体验。应该有个工具可用性检测机制,不可用及时下线。
- 问题3:现在MCP服务的封装主流还是前端框架和Python,Java来封装MCP似乎不太方便或者说上手门槛略高。
这几个问题留给大家去思考,好了,今天就讲到这,我们下期再见。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









