



本文详细介绍了LangChain生态系统中的LangGraph和LangSmith如何协作构建、部署、评估和监控智能体AI系统。LangGraph用于构建基于图的智能体,而LangSmith提供监控、跟踪开支和实验评估功能。通过数学问题求解智能体的实例,展示了从创建智能体到使用LangSmith进行跟踪、数据集创建和评估的完整流程,帮助开发者优化AI系统性能并降低成本。
LangChain 创造了一个包含 LangChain、LangGraph、LangSmith 和 LangServe 的良好生态系统。利用这些工具,我们可以构建、部署、评估和监控智能体 AI 系统 (Agentic AI systems)。
在构建 AI 智能体时,我不禁想:“为什么不展示一个简单的 Demo 来演示 LangGraph 和 LangSmith 是如何协作的呢?” 这将会非常地有用,因为 AI 智能体通常需要多次调用 LLM,并且费用较高。这种组合将有助于跟踪开支并使用自定义数据集评估系统。
LangGraph
简而言之,AI 智能体是具备思考/推理能力的 LLM,它们可以访问工具来弥补自身的不足或获取实时信息。LangGraph 是一个基于 LangChain 的智能体 AI 框架,用于构建这些 AI 智能体。LangGraph 有助于构建基于图的智能体 (graph-based Agents);此外,LangGraph/LangChain 库中已经存在的许多内置功能简化了智能体工作流 (Agentic workflows) 的创建。
什么是 LangSmith?
LangSmith 是 LangChain 推出的一个监控和评估平台。它不依赖于特定框架,旨在与任何智能体框架(例如 LangGraph)甚至完全从头构建的智能体配合使用。
可以轻松配置 LangSmith 来跟踪 (trace) 运行过程,并追踪智能体系统的开支。它还支持对系统进行实验 (experiments),例如更改系统中的提示词 (prompt) 和模型,并比较结果。它具有预定义的评估器,如有用性 (helpfulness)、正确性 (correctness) 和幻觉 (hallucinations)。你也可以选择定义自己的评估器。让我们看一下 LangSmith 平台以获得更好的理解。
LangSmith 平台功能
让我们先注册/登录平台:https://www.langchain.com/langsmith
平台包含多个选项卡:
- Tracing Projects (跟踪项目): 跟踪多个项目及其轨迹 (traces) 或运行集 (sets of runs)。在这里,可以跟踪成本、错误、延迟 (latency) 以及许多其他信息。
- Monitoring (监控): 在这里你可以设置警报,例如,在系统失败或延迟超过设定的阈值时发出警告。
- Dataset & Experiments (数据集与实验): 在这里,你可以使用人工制作的数据集运行实验,或者使用平台创建 AI 生成的数据集来测试你的系统。你还可以更改模型以查看性能如何变化。
- Prompts (提示词): 在这里你可以存储一些提示词,稍后更改措辞或指令顺序,以查看结果的变化。
LangSmith 实践
我们将构建一个使用简单工具来解决数学表达式的智能体,然后启用可追溯性 (traceability)。随后,我们将检查 LangSmith 仪表板,看看可以使用该平台跟踪哪些信息。
获取 API 密钥:
-
访问 LangSmith 仪表板并点击 ‘Setup Observability’ 按钮。然后你会看到这个界面:https://www.langchain.com/langsmith
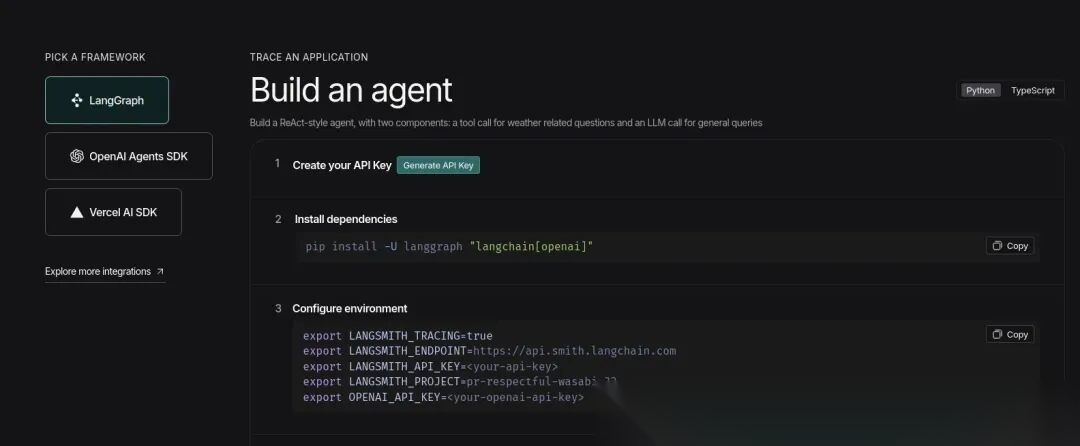
-
点击 ‘Generate API Key’ 选项,并将 LangSmith 密钥放在手边。
-
现在访问 Google AI Studio 以获取 Gemini API key:https://aistudio.google.com/api-keys
-
点击右上角的 ‘Create API key’,如果项目不存在则创建一个,并将密钥放在手边。
代码实现
安装
!pip install -q langgraph langsmith langchain !pip install -q langchain-google-genai
★注意: 请确保在此处继续之前重启会话 (restart the session)。
设置环境
在提示时输入 API 密钥。
from getpass import getpassLANGCHAIN_API_KEY=getpass('Enter LangSmith API Key: ')GOOGLE_API_KEY=getpass('Enter Gemini API Key: ')import osos.environ['LANGCHAIN_TRACING_V2'] = 'true'os.environ['LANGCHAIN_API_KEY'] = LANGCHAIN_API_KEYos.environ['LANGCHAIN_PROJECT'] = 'Testing'
★ 注: 建议使用不同的项目名称来跟踪不同的项目;将其命名Testing
设置和运行智能体
这里我们使用一个智能体可以用来解决数学表达式的简单工具。
我们使用 LangGraph 内置的 create_react_agent,我们只需要定义模型,赋予工具访问权限,即可开始使用。
from langgraph.prebuilt import create_react_agentfrom langchain_google_genai import ChatGoogleGenerativeAIdef solve_math_problem(expression: str) -> str: """Solve a math problem.""" try: # Evaluate the mathematical expression result = eval(expression, {"__builtins__": {}}) returnf"The answer is {result}." except Exception: return"I couldn't solve that expression."# Initialize the Gemini model with API keymodel = ChatGoogleGenerativeAI( model="gemini-2.5-flash", google_api_key=GOOGLE_API_KEY)# Create the agentagent = create_react_agent( model=model, tools=[solve_math_problem], prompt=( "You are a Math Tutor AI. " "When a user asks a math question, reason through the steps clearly " "and use the tool `solve_math_problem` for numeric calculations. " "Always explain your reasoning before giving the final answer." ),)# Run the agentresponse = agent.invoke( {"messages": [{"role": "user", "content": "What is (12 + 8) * 3?"}]})print(response)
输出: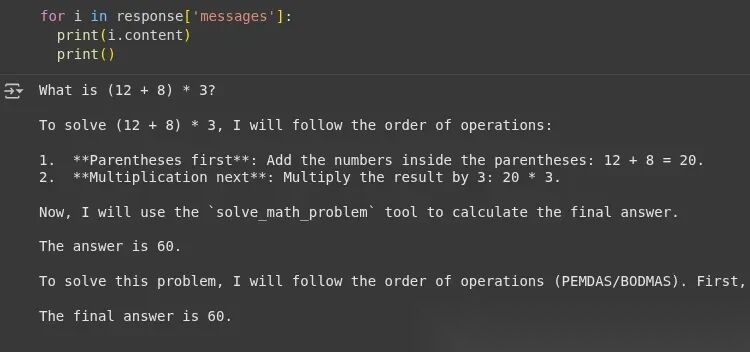
我们可以看到智能体使用了工具的响应 ‘The answer is 60’,并且在回答问题时没有产生幻觉。现在让我们查看 LangSmith 仪表板。
LangSmith 仪表板
Tracing Projects 选项卡
我们可以看到项目已以 ‘testing’ 名称创建;你可以点击它查看详细日志。
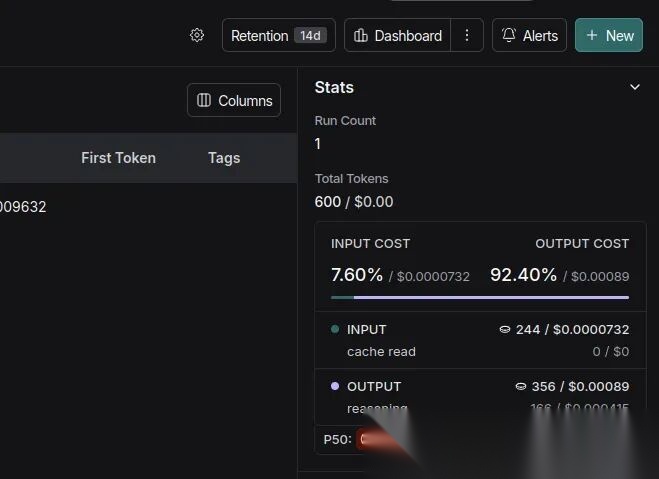
这里显示了按运行划分的详细信息:
- Total Tokens (总 Tokens 数)
- Total Cost (总成本)
- Latency (延迟)
- Input (输入)
- Output (输出)
- Time when the code was executed (代码执行时间)
Monitoring 选项卡
在这里你可以看到一个包含项目、运行和总成本的仪表板。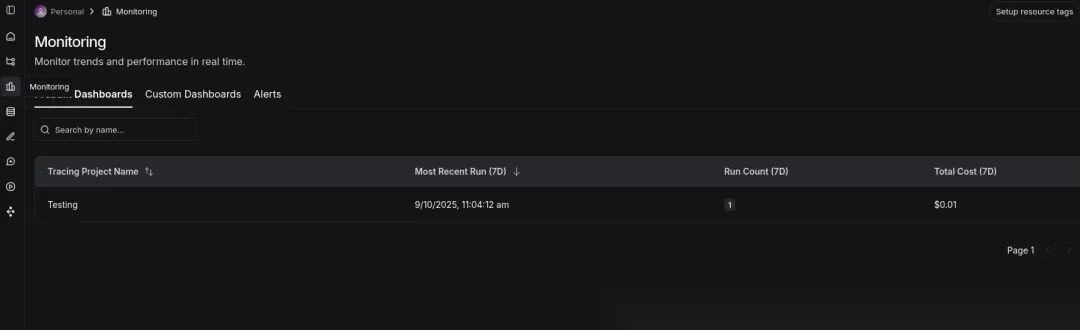
LLM 作为评判者
LangSmith 允许使用带有输入 (input) 和输出 (output) 键的简单字典来创建数据集 (dataset)。这个带有预期输出的数据集可以用于评估 AI 系统生成的输出在有用性、正确性和幻觉等指标上的表现。
我们将使用类似的数学智能体,创建数据集,并评估我们的智能体系统。
安装
!pip install -q openevals langchain-openai
环境设置
import osfrom google.colab import userdataos.environ['OPENAI_API_KEY']=userdata.get('OPENAI_API_KEY')
定义智能体
from langsmith import Client, wrappersfrom openevals.llm import create_llm_as_judgefrom openevals.prompts import CORRECTNESS_PROMPTfrom langchain_openai import ChatOpenAIfrom langgraph.prebuilt import create_react_agentfrom langchain_core.tools import toolfrom typing import Dict, Listimport requests# STEP 1: Define Tools for the Agent =====@tooldef solve_math_problem(expression: str) -> str: """Solve a math problem.""" try: # Evaluate the mathematical expression result = eval(expression, {"__builtins__": {}}) returnf"The answer is {result}." except Exception: return"I couldn't solve that expression."# STEP 2: Create the LangGraph ReAct Agent =====def create_math_agent(): """Create a ReAct agent with tools.""" # Initialize the LLM model = ChatOpenAI(model="gpt-4o-mini", temperature=0) # Define the tools tools = [solve_math_problem] # Create the ReAct agent using LangGraph's prebuilt function agent = create_react_agent( model=model, tools=[solve_math_problem], prompt=( "You are a Math Tutor AI. " "When a user asks a math question, reason through the steps clearly " "and use the tool `solve_math_problem` for numeric calculations. " "Always explain your reasoning before giving the final answer." ), ) return agent
创建数据集
让我们创建一个包含简单和困难数学表达式的数据集,我们稍后可以使用它来运行实验。
client = Client()dataset = client.create_dataset( dataset_name="Math Dataset", description="Hard numeric + mixed arithmetic expressions to evaluate the solver agent.")examples = [ # Simple check { "inputs": {"question": "12 + 7"}, "outputs": {"answer": "The answer is 19."}, }, { "inputs": {"question": "100 - 37"}, "outputs": {"answer": "The answer is 63."}, }, # Mixed operators and parentheses { "inputs": {"question": "(3 + 5) * 2 - 4 / 2"}, "outputs": {"answer": "The answer is 14.0."}, }, { "inputs": {"question": "2 * (3 + (4 - 1)*5) / 3"}, "outputs": {"answer": "The answer is 14.0."}, }, # Large numbers & multiplication { "inputs": {"question": "98765 * 4321"}, "outputs": {"answer": "The answer is 426,373,565."}, }, { "inputs": {"question": "123456789 * 987654321"}, "outputs": {"answer": "The answer is 121,932,631,112,635,269."}, }, # Division, decimals, rounding { "inputs": {"question": "22 / 7"}, "outputs": {"answer": "The answer is approximately 3.142857142857143."}, }, { "inputs": {"question": "5 / 3"}, "outputs": {"answer": "The answer is 1.6666666666666667."}, }, # Exponents, roots { "inputs": {"question": "2 ** 10 + 3 ** 5"}, "outputs": {"answer": "The answer is 1128."}, }, { "inputs": {"question": "sqrt(2) * sqrt(8)"}, "outputs": {"answer": "The answer is 4.0."}, }, # Edge / error / “unanswerable” cases { "inputs": {"question": "5 / 0"}, "outputs": {"answer": "I couldn’t solve that expression."}, }, { "inputs": {"question": "abc + 5"}, "outputs": {"answer": "I couldn’t solve that expression."}, }, { "inputs": {"question": ""}, "outputs": {"answer": "I couldn’t solve that expression."}, },]client.create_examples( dataset_id=dataset.id, examples=examples)
太棒了!我们创建了一个包含 13 条记录的数据集。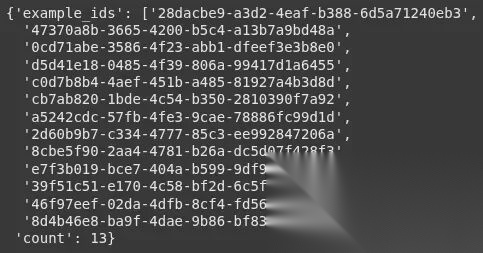
定义目标函数
此函数调用智能体并返回响应。
def target(inputs: Dict) -> Dict: agent = create_math_agent() agent_input = { "messages": [{"role": "user", "content": inputs["question"]}] } result = agent.invoke(agent_input) final_message = result["messages"][-1] answer = final_message.content if hasattr(final_message, 'content') else str(final_message) return {"answer": answer}
定义评估器
我们使用预构建的 llm_as_judge 函数,并从 openevals 库中导入提示词。
我们目前使用 4o-mini 来保持低成本,但推理模型可能更适合此任务。
def correctness_evaluator(inputs: Dict, outputs: Dict, reference_outputs: Dict) -> Dict: evaluator = create_llm_as_judge( prompt=CORRECTNESS_PROMPT, model="openai:gpt-4o-mini", feedback_key="correctness", ) eval_result = evaluator( inputs=inputs, outputs=outputs, reference_outputs=reference_outputs ) return eval_result
运行评估
experiment_results = client.evaluate( target, data="Math Dataset", evaluators=[correctness_evaluator], experiment_prefix="langgraph-math-agent", max_concurrency=2,)
输出:
运行后将生成一个链接。点击该链接,你将被重定向到 LangSmith 的 ‘Datasets & Experiments’ 选项卡,在那里你可以看到实验结果。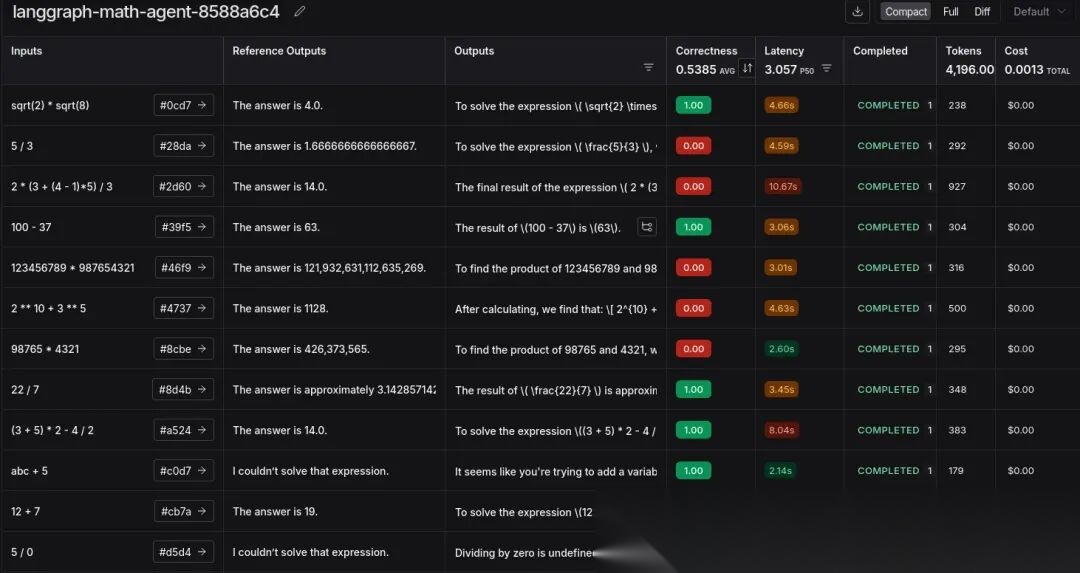
我们成功地进行了使用 LLM 作为评判者的实验。这在发现边缘案例 (edge cases)、成本和 token 使用方面具有洞察力。
这里的错误大多是由于使用逗号或存在长小数导致的不匹配。这可以通过更改评估提示词或尝试推理模型来解决。或者简单地在工具级别添加逗号并确保小数格式。
总结
就是这样!我们成功展示了 LangGraph(用于构建智能体)和 LangSmith(用于跟踪和评估它)的交织工作。这种组合对于跟踪开支和确保你的智能体通过自定义数据集按预期运行非常强大。虽然我们专注于跟踪和实验,但 LangSmith 的能力不止于此。你还可以探索更强大的功能,例如在生产环境中对不同提示词进行 A/B 测试、将人工干预反馈 (human-in-the-loop feedback) 直接添加到轨迹中,以及创建自动化来简化你的调试工作流。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 908
908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









