







一、回归应用广泛
二、引出梯度下降算法来求解minL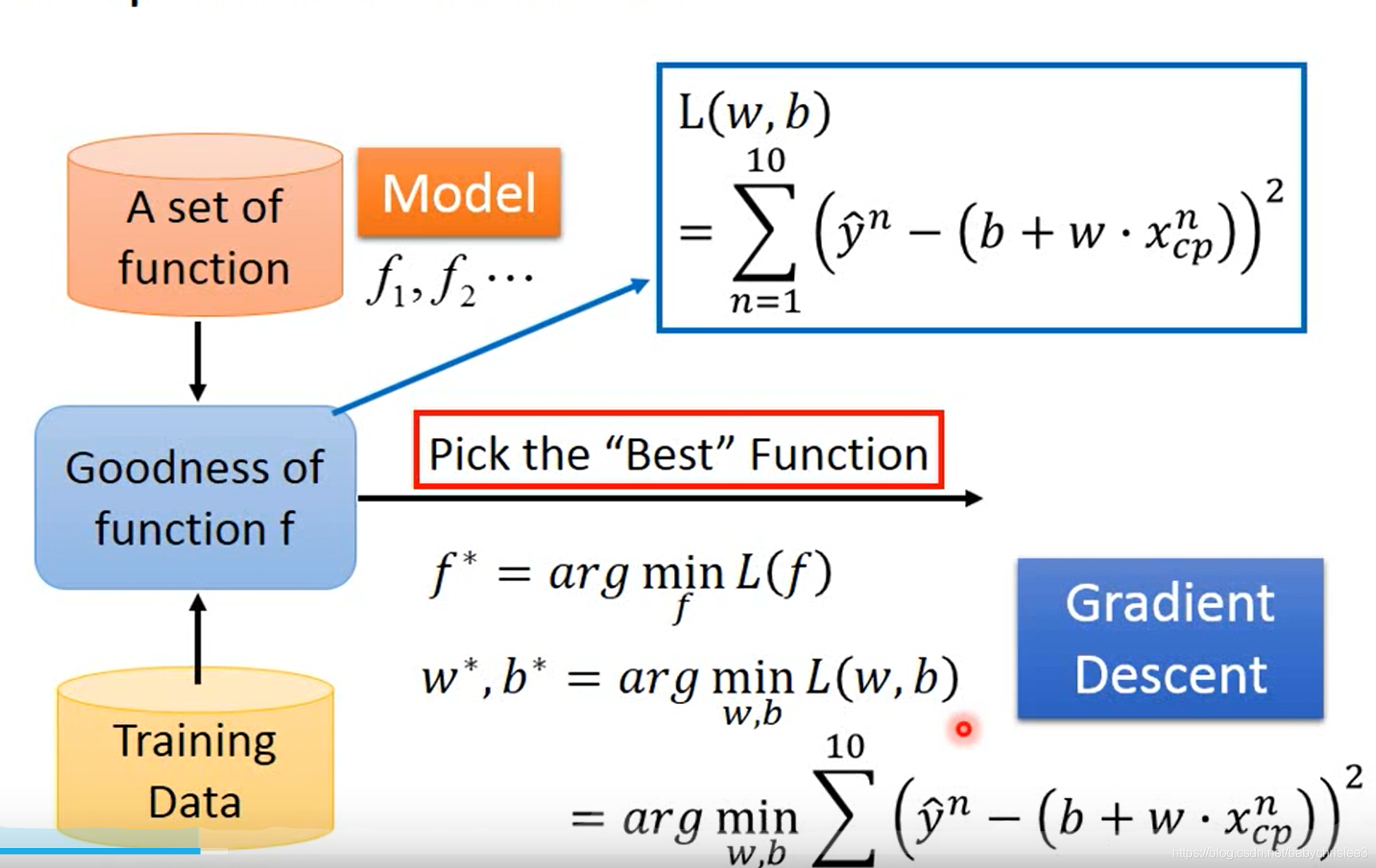
(1)梯度下降厉害的地方在哪里?
只要方程可微分,都可以拿来进行处理,来找比较好的参数和方程。
梯度的方向是变化率最大的方向。
(2)梯度下降法:只有一个参数时

总是为了让loss减少。
任取一点,求出来该点的导数为负,就增加w;反之减少w。
n : learning rate 学习率 (决定步长)

可以看出来步长是变化的。
越接近min,导数值越小,步长越小。
梯度下降法:有两个参数时

【注意】w和b一定是同步更新的
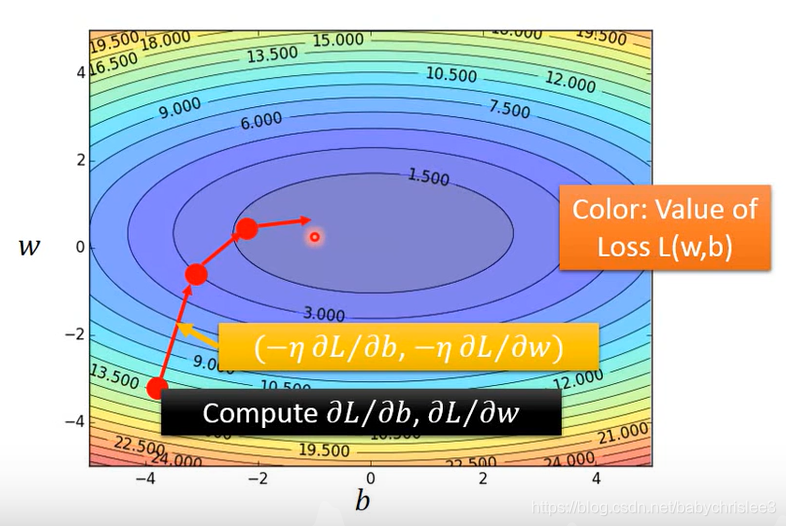
梯度方向其实也是等高线的法线方向
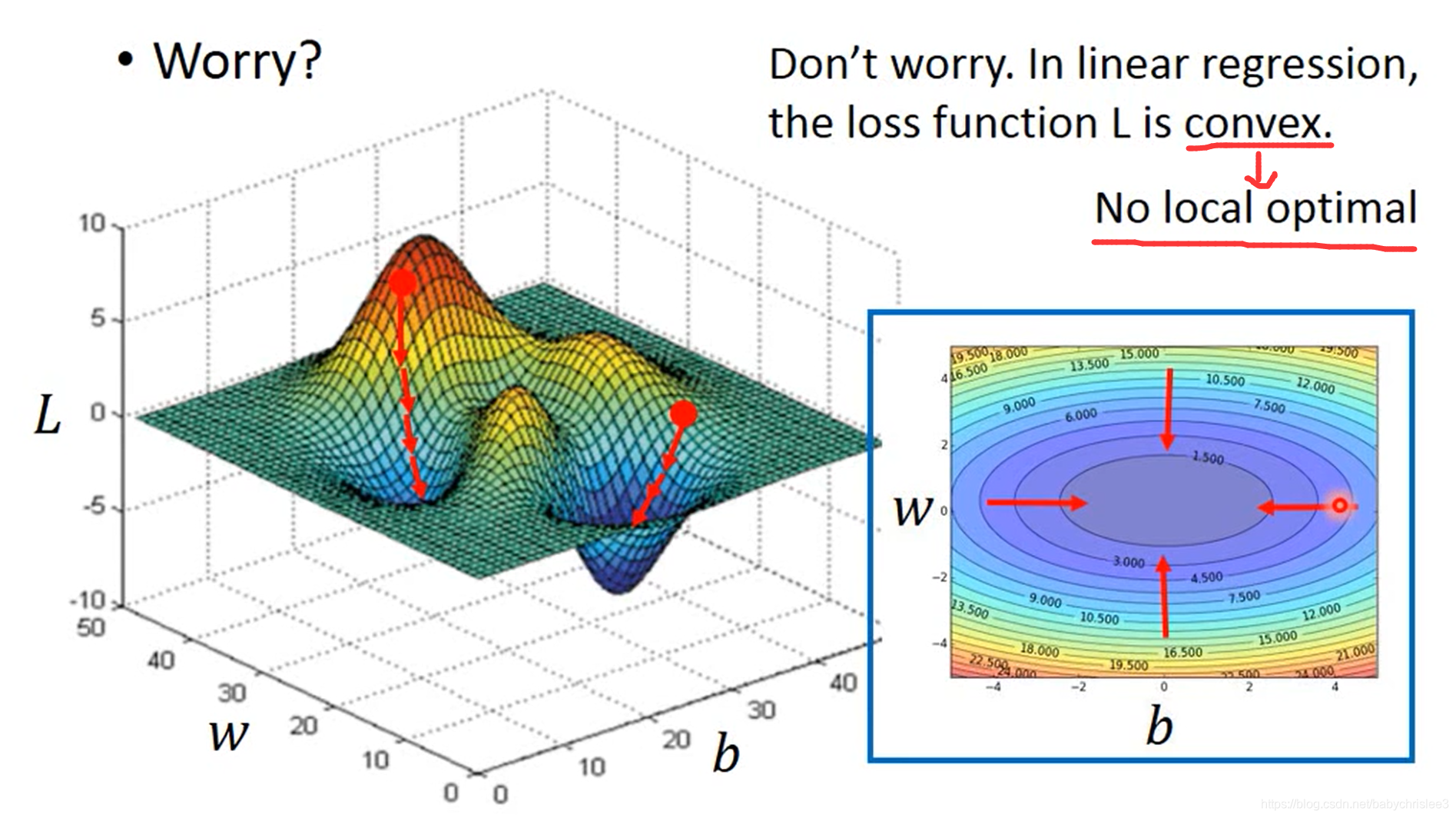
在线性回归里,损失函数是凸函数,局部最优就是全局最优,不会出现左图中在不同的初始点会找到不同的局部最优的情况。
也就是如出现的如右图所示,在任意一个点,都会最终沿着梯度下降到全局最优点。
看看梯度下降得到的结果
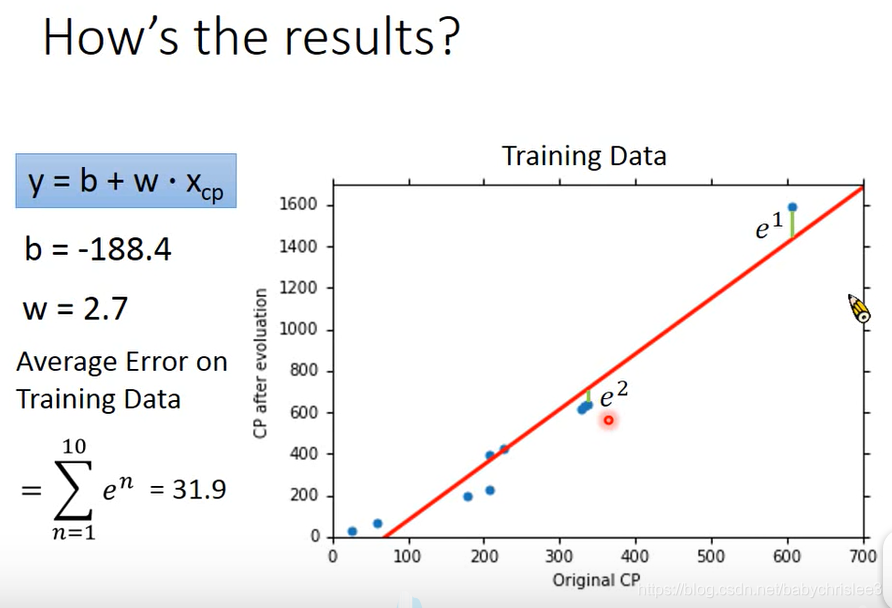
training data 训练集 算出来的误差是 31.9,但是这个并不是我们真正关心的。
我们真正关心的是当用训练出来的模型去测试新的样本时 的准确性。
因此,我们来看看用testing data 来测试一下误差。
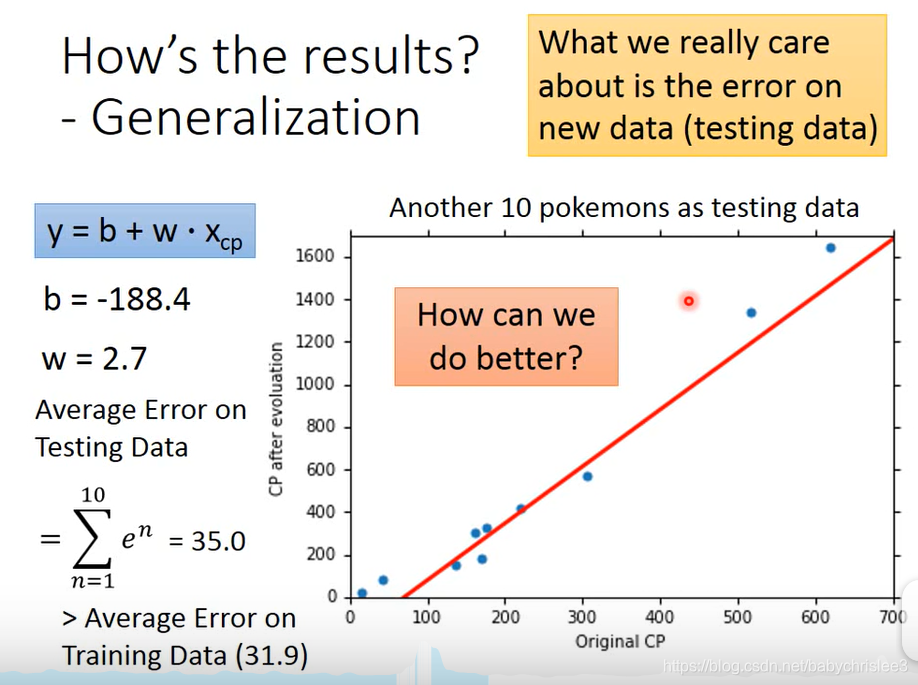
结果不太好时,我们如何做到更好呢?
可以尝试重新拟合
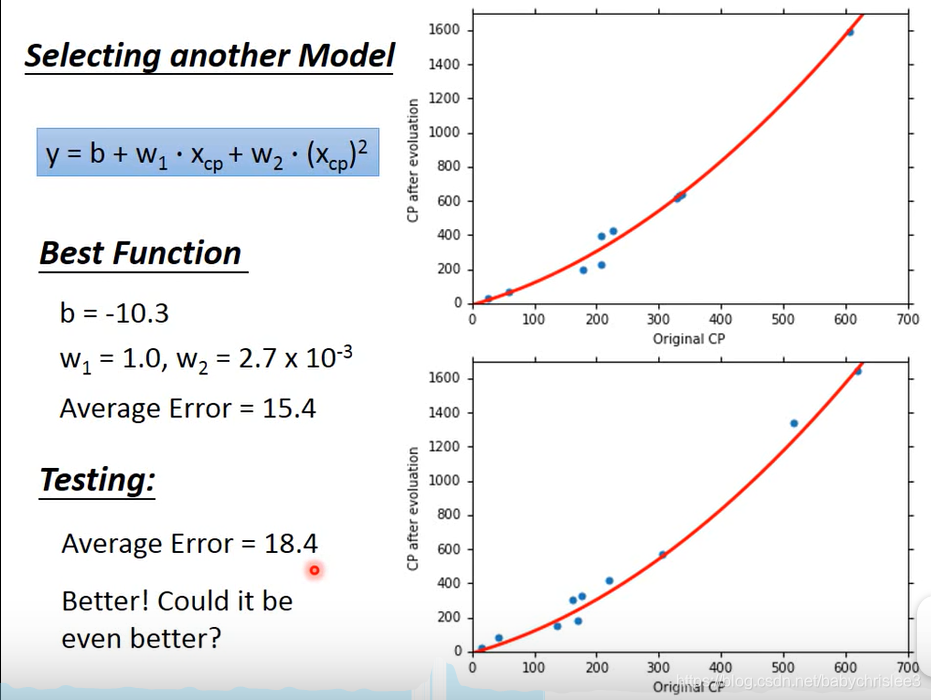
可以看到是好了一些的。
注意w2的系数很小了
有没有可能做得更好?
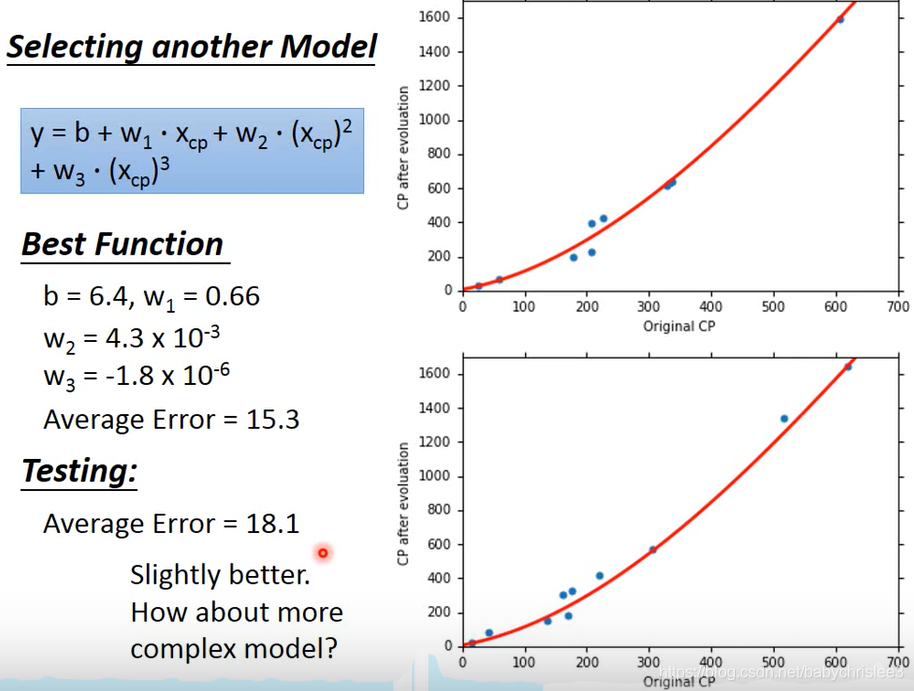
看w2 、w3已经很小了
更加复杂的话…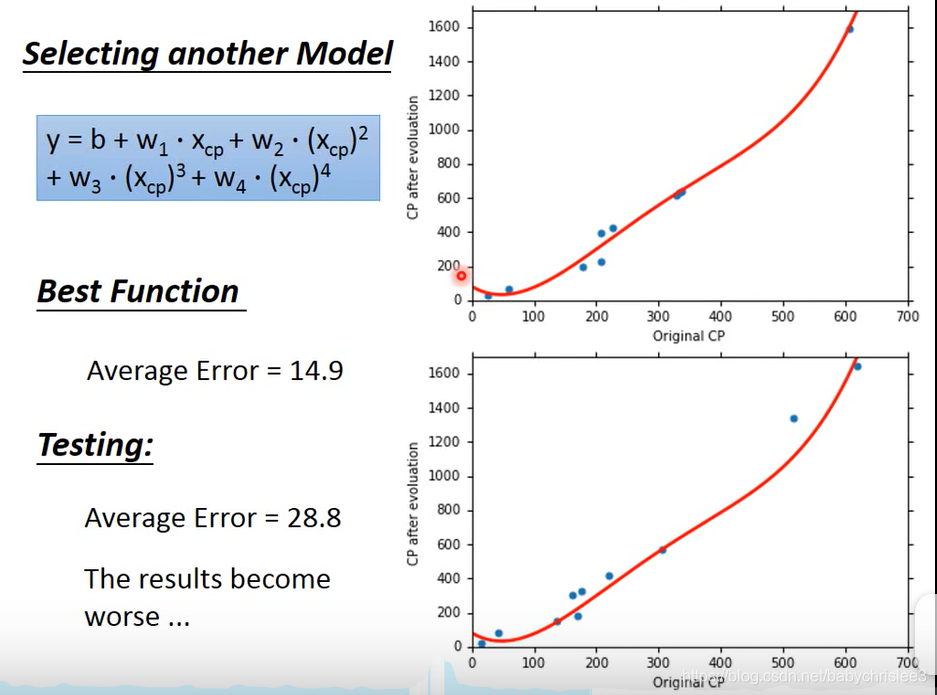
testing data上的误差更大了。模型差了。
更复杂呢?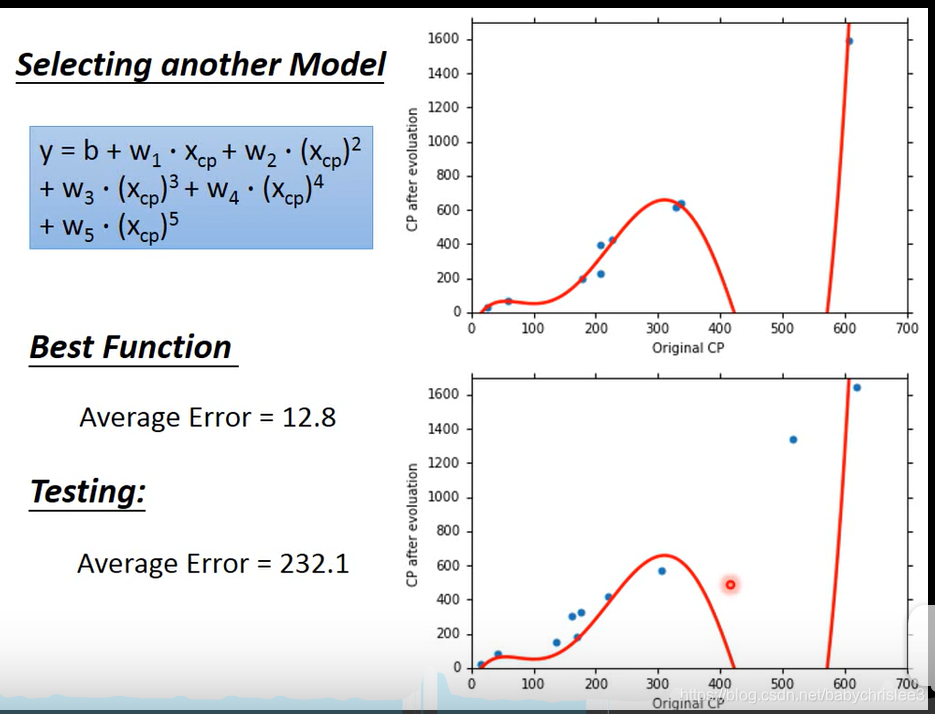
testing拟合太差了!
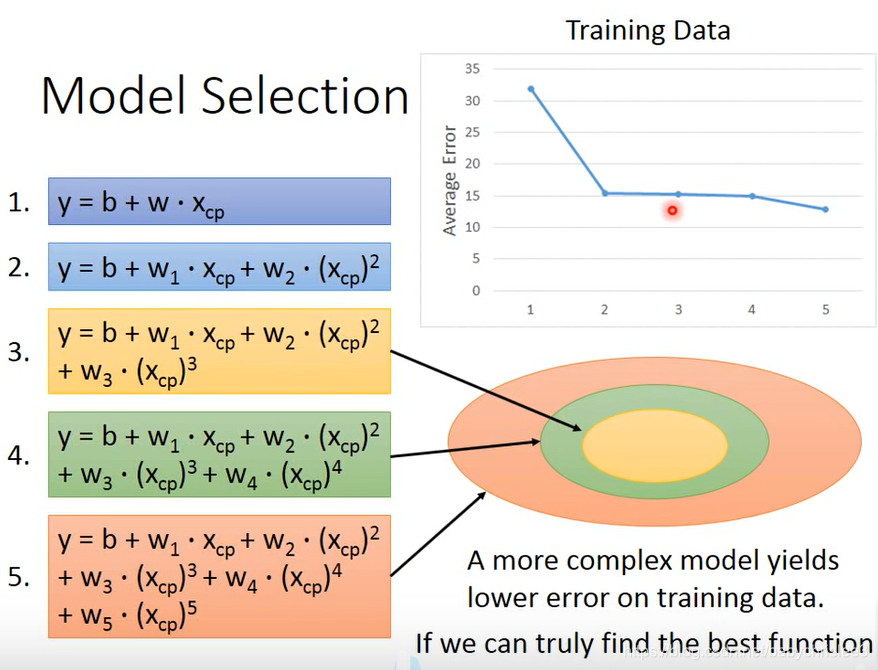
5包含4包含3.

其实4.5 过拟合了。 选择3最合适。
接下来增加样本量看看拟合的还是那个吗?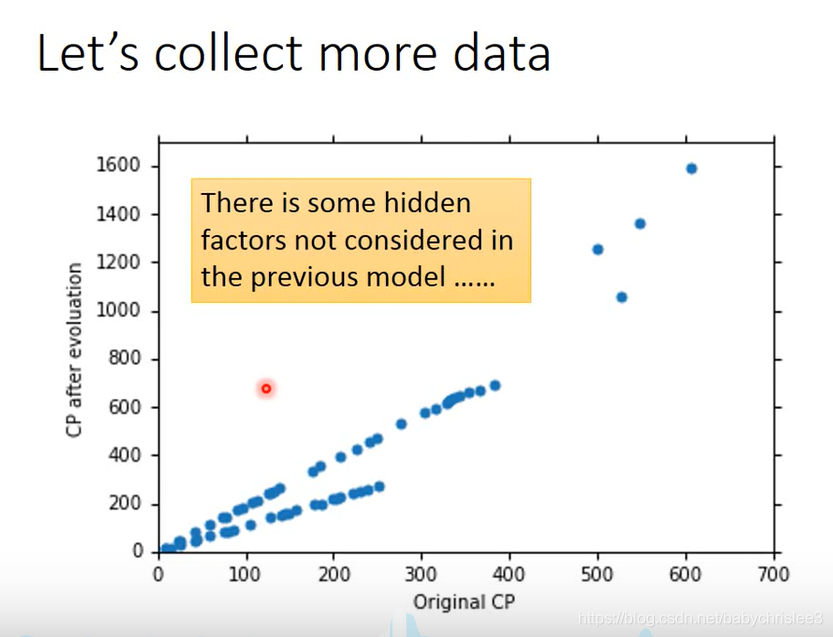
从图上直观来看,不太适合了。
仿佛有一些隐含特征没有找到。
!如果分类别来看的话:

那好,现在重新设计模型:
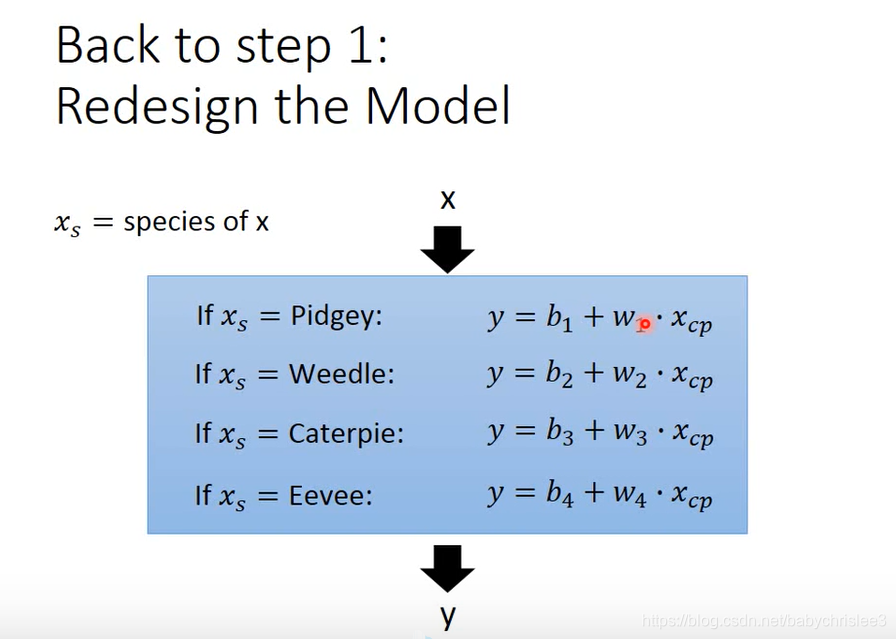
转换下写法:

看看结果:
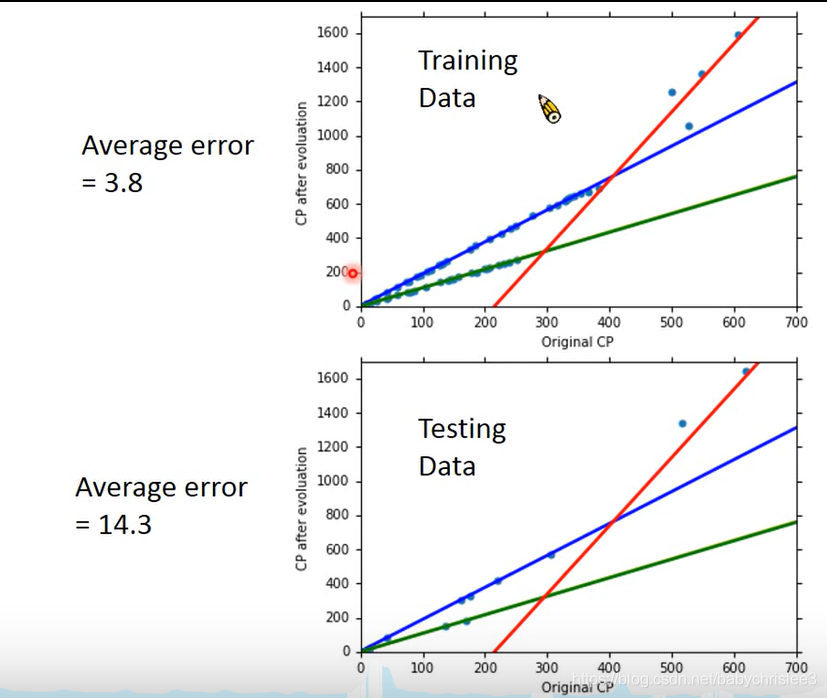
是不是可能会有其他的隐藏变量呢?
那就利用你自己的knowledge,把能想到的都加进去。
这样又会出现个问题:过拟合
怎么解决? 正则化
正则化

李宏毅解释为什么添加正则项?为什么期待参数值接近0?
参数值较小时,模型较为平滑。平滑就意味着,输入改变的时候,输出的改变幅度较小。
如果一个平滑的函数,输入受到了一些noise噪声的影响,那么输出受到的影响就较小,从而给我们比较好的结果。(因为对于输入的改变不敏感)
考虑正则项的后果?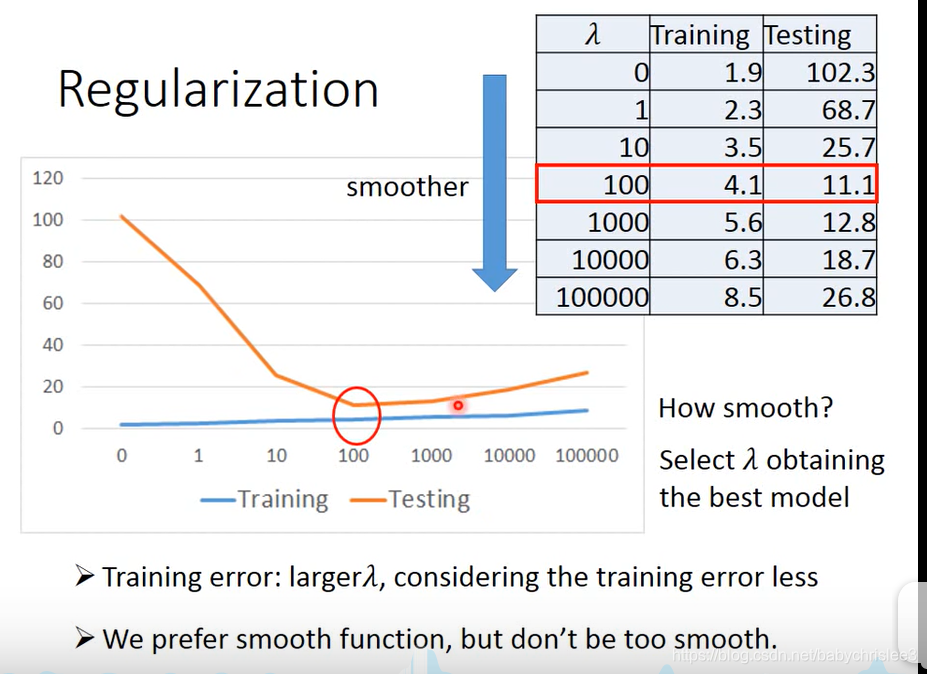 **λ越大,越偏向考虑正则项,找到的function就越平滑。
**λ越大,越偏向考虑正则项,找到的function就越平滑。
λ越大,training data的error 越大,因为越倾向于考虑w的值。**
最平滑的function就是一条水平线~

















 1476
1476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









