




一、什么是梯度?
答:▽ L就是梯度(如图),三角形符号倒过来(▽ )是梯度算子(在空间各方向上的全微分)

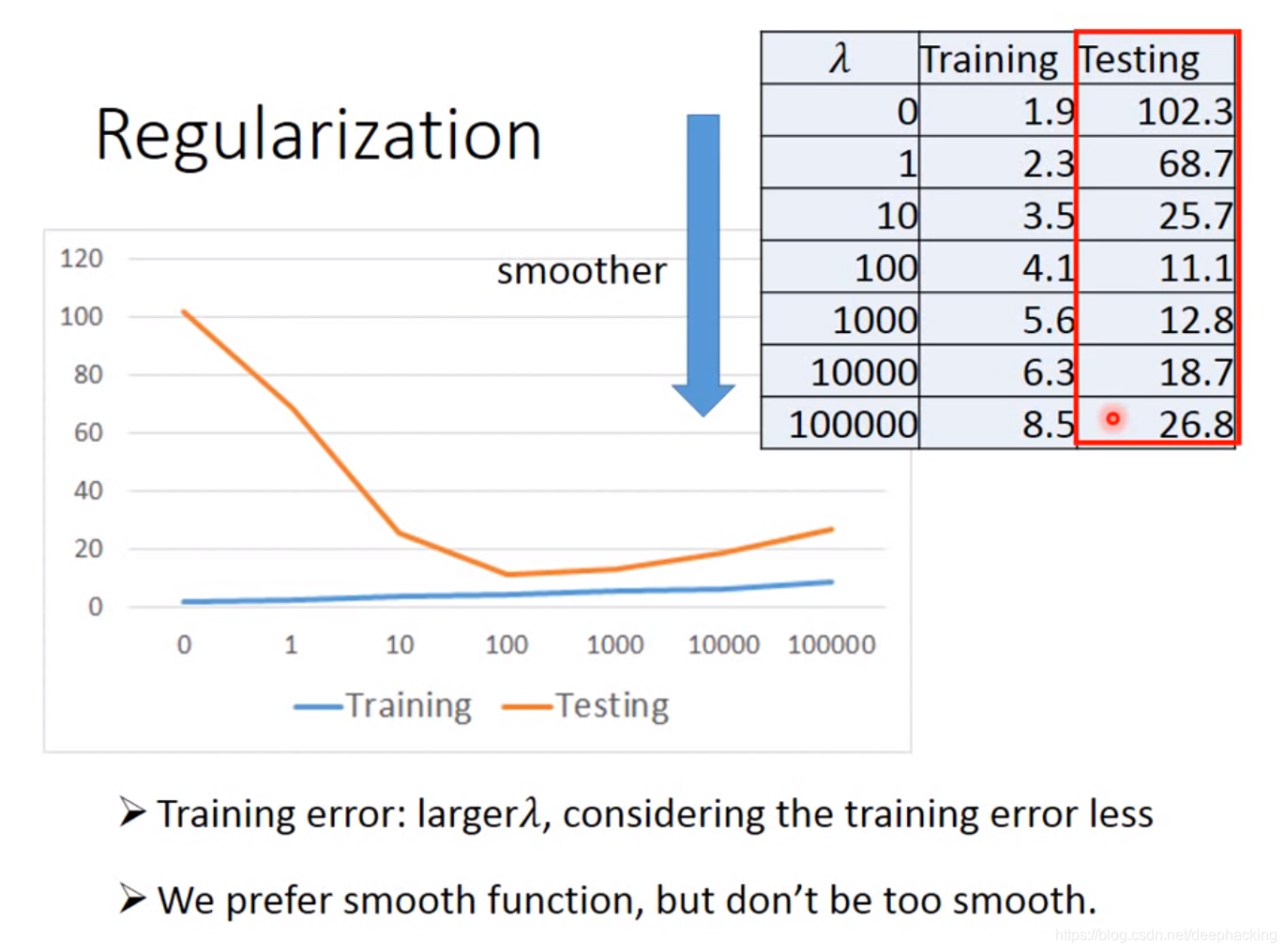
二、为什么要正则化?
答:我们希望得到一个平滑的function,这个function受到噪点数据的影响就会变小。对异常数据就不会那么敏感,可以提升模型的容错率。所有在Loss Function中加入了参数的平方和项

三、偏差(Bias)和方差(Variance)的关系?
答:模型越复杂,对真实数据就模拟得更加准确,期望值就接近真实值,所以偏差(Bias)就越小;但样本数据就会更加分散,方差(Variance)会增大。相反,模型越简单,就不一定包含真实函数模型,偏差(Bias)就会较大;但样本数据就会更加集中,方差(Variance)会变小。终上所述,模型要选择一个适中,让偏差(Bias)尽可能小的情况下方差(Variance)也小。
如果偏差(Bias)很大,叫欠拟合(underfitting);如果方差(Variance)很大,叫过拟合(overfitt
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









