




 该研究提出了一种名为SN-Net的双分支神经网络,用于同时对语音和噪声进行建模。每个分支预测语音和噪声,中间通过交互模块促进信息交流,增强模型的辨别能力。使用残差卷积注意力模块捕捉时间频率依赖性。实验表明,这种方法在多个数据集上提高了语音增强的质量,达到了最先进的性能。
该研究提出了一种名为SN-Net的双分支神经网络,用于同时对语音和噪声进行建模。每个分支预测语音和噪声,中间通过交互模块促进信息交流,增强模型的辨别能力。使用残差卷积注意力模块捕捉时间频率依赖性。实验表明,这种方法在多个数据集上提高了语音增强的质量,达到了最先进的性能。

0. 摘要
AAAI2021paper
当前大多数模型都是对语音进行建模,而不是对噪声。本文提出了一种在两分支卷积神经网络(SN-NET)中同时对语义和噪声进行建模的方法,两个分支分别对语音和噪声进行预测。不仅仅是在最终输出层进行信息融合,本文模型在两个分支之间的几个中间特征域中引入交互模块to benefit each other. 这种交互可以利用从一个分支学到的特征来抵消不需要的部分并恢复另一份分支的缺失部分,从而增强两个分支的辨别能力。此外,本文还设计了一个特征提取模块——残差卷积注意力模块(residual-convolution and attention, RA),以获取语音和噪声沿时间和频率维度的相关性。对公共数据集的评估结果表明,交互模块在同步建模中起到了关键作用,SN-Net模型在多项评估指标中获得了STOA性能,该模型同样能够应用到说话人分离领域。
1. Introduction
主流的基于深度学习语音信号预测方法采用有监督学习的策略,如图1(a)所示:

多数科研工作在时频域对信号进行处理,预测noisy和clean信号之间的mask或者直接对干净语音的频谱进行估计。同样有一些方法直接在时域上进行处理,采用端到端的方法预测语音信号。虽然这些方法相较于传统方法在语音增强性能方面取得了很大的提升,但是增强后的语音仍然存在语音失真和残留噪声的问题,这就说明,预测语音和残留噪声之间依然存在相关性。
与当前基于深度学习的方法有所不同,传统的语音信号处理和基于模型的方法中,大多采用其他策略,如图1(b)所示,例如:通过估计噪声或者构建噪声模型的方式进行语音增强。但是当其不能满足先验噪声假设或者干扰信号没有结构化时,这些方法往往不能很好的发挥作用。在深度学习领域,有两项工作【Odelowo and Anderson 2017, 2018】直接对噪声进行预测,其主要考虑噪声在低信噪比条件下占主导地位,但是方法取得效果有限。
Odelowo, B. O.; and Anderson, D. V. 2017. A noise prediction and time-domain subtraction approach to deep neural network based speech enhancement. In 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), 372–377. IEEE.
Odelowo, B. O.; and Anderson, D. V. 2018. A study of training targets for deep neural network-based speech enhancement using noise prediction. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5409–5413. IEEE
预测语音和噪声之间依然存在的相关性,促使本文探索语音和噪声之间的信息流,如图1(c)所示。由于和语音相关信息可能存在于预测的噪声中,反之亦然,因此在它们之间添加信息通信可能有助于恢复一些缺失的信息,并从对方的信息中去除不需要的内容。在本文中,作者提出了一种双分支卷积神经网络-SN-Net,同时对语音和噪声信号进行预测。分支之间使用信息交互模块,通过信息交互,达到相互促进和抵消的目的。通过该方法,模型的辨别能力得到了有效提升。两个分支共享网络结构,采用基于encoder-decoder的模型架构,中间有几个参加卷积和注意力块(RA)用于分离。本文在每个RA块内结合实践自注意力和频率自主利益,以可分离的方式捕获延时间和频率维度的全局依赖性。
2. Related work
2.1 Deep learning-based speech enhancement
主要分为时频域方法和时域信号处理方法。前者主要使用经过STFT变换后的T-F表示作为网络输入,可以是复数信息,也可以是幅度谱信息,通常估计出一个实数或者复数mask,或者直接对干净语音的频谱表示进行预测。后者直接使用时域波形信息作为网络输入,通过encoder提取隐层特征表示,并通过decoder重建增强后的语音。
2.2 Noise-aware speech enhancement
针对噪声信息的处理通常出现在传统的信号处理方法中,这些方法通常会使用语音和噪声的先验分布假设。然而,对非平稳噪声的噪声功率谱密度进行估计是非常困难的,因此通常假设噪声为平稳信号。一些基于模型的方法显示出更有前景的结果,这些方法同时为语音和噪声进行建模。例如基于codebook的方法【Srinivasan, Samuelsson, and Kleijn 2005b,a】和基于非负矩阵分解的方法【Wilson et al. 2008; Mohammadiha, Smaragdis, and Leijon 2013】。但是这些方法或者需要噪声类型的先验知识【codebook方法】,或者只对结构化噪声有效【NMF方法】。因此基于模型的方法泛化性能较差。
基于深度学习的方法能够应用于各种噪声条件中,当前已经有一些工作尝试考虑噪声信息,例如,通过损失函数加以约束【Fan et al. 2019; Xu, Elshamy, and Fingscheidt 2020; Xia et al. 2020】,或者直接对噪声进行预测,而不是预测语音【Fan et al. 2019; Xu, Elshamy, and Fingscheidt 2020; Xia et al. 2020】。前者没有对噪声进行建模,同时也没有利用噪声的特性。后者丢掉了语音信息,甚至在低信噪比和unseen noise 条件下取得的性能要差于其他方法。【Sun et al. 2015】曾利用两个深度自编码器(DAEs)对语音和噪声进行估计。该方法首先训练一个DAE对语音频谱进行重构,之后利用另外一个DAE对噪声进行建模,约束条件的是两个DAE的输出之和等于噪声频谱。
Xu, Z.; Elshamy, S.; and Fingscheidt, T. 2020. Using Separate Losses for Speech and Noise in Mask-Based Speech Enhancement. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 7519–7523. IEEE.
Xia, Y.; Braun, S.; Reddy, C. K.; Dubey, H.; Cutler, R.; and Tashev, I. 2020. Weighted Speech Distortion Losses for Neural-Network-Based Real-Time Speech Enhancement. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 871– 875. IEEE.
2.3 Two-Branch neural network
双分支网络已在多种任务中得到应用,捕获跨模态信息【Wang et al. 2019】或者不同级别【Wang et al. 2020】的信息。在语音增强领域,【Yin et al. 2020】利用双分支网络分别预测增强信号的幅度和相位。本文利用双分支网络对语音和噪声进行建模,并通过交互模块实现更好的区分。
Wang, H.; Zha, Z.-J.; Chen, X.; Xiong, Z.; and Luo, J. 2020. Dual Path Interaction Network for Video Moment Localization. In Proceedings ofthe 28th ACM International Conference on Multimedia, 4116–4124.
Wang, L.; Li, Y.; Huang, J.; and Lazebnik, S. 2019. Learning two-branch neural networks for image-text matching tasks. IEEE transactions on pattern analysis and machine intelligence 41(2): 394–407.
2.4 Self-Attention model
自注意力机制同样在多种任务中得到了广泛应用,包括机器翻译、图像生成、视频问答等。在视频领域,空间注意力机制用于学习空间和时间维度上的长期依赖性。语音相关的任务同样采用了自注意力机制,包括语音识别,语音增强【Kim, El-Khamy, and Lee 2020; Koizumi et al. 2020】。但是这些任务中仅仅在时间维度上学习长期以来,忽略了频率之间的全局依赖性。
Kim, J.; El-Khamy, M.; and Lee, J. 2020. T-GSA: Transformer with Gaussian-Weighted Self-Attention for Speech Enhancement. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6649–6653. IEEE.
Koizumi, Y.; Yaiabe, K.; Delcroix, M.; Maxuxama, Y.; and Takeuchi, D. 2020. Speech enhancement using selfadaptation and multi-head self-attention. In ICASSP 20202020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 181–185. IEEE.
3. Proposed Method
3.1 Overview

网络的输入为复数T-F频谱
X
I
∈
R
T
×
F
×
2
X^I \in R^{T \times F \times 2}
XI∈RT×F×2,其中T表示时间帧数,F表示频率点数。SN-Net的两个分支共享相同的网络结构,但是采用不同的网络参数。网络分支采用基于encoder-decoder的架构,中间嵌入RA模块。两个分支之间通过interaction模块传输和共享信息。最后通过Merge Branch合并输出信息,得到最终的增强语音。
3.2 Encoder and Decoder
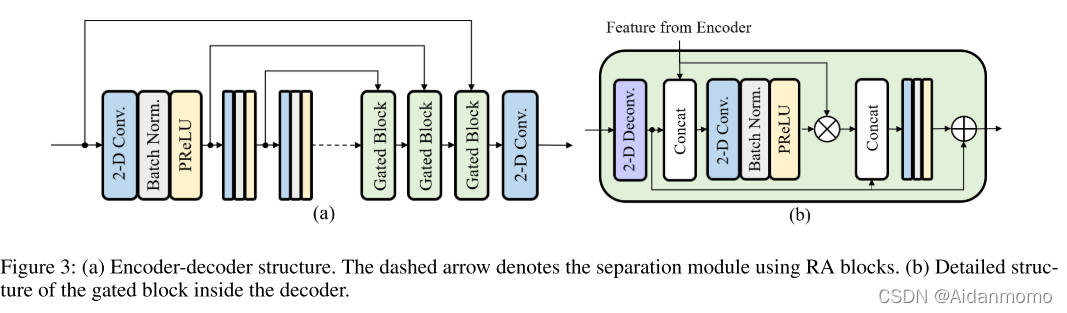
如图3(a)所示,encoder包含三个二维卷积层,卷积核大小为(3, 5),第一个卷积层的步长为(1,1),后面两层的步长为(1, 2)。通道数分别为16,32,64。因此可得到encoder的输出为
F
k
E
∈
R
T
×
F
′
×
C
F^E_{k} \in \mathbb{R}^{T \times F^{'} \times C}
FkE∈RT×F′×C,其中
F
′
=
F
4
F^{'}=\frac{F}{4}
F′=4F,C=64,
k
∈
{
S
,
N
}
k \in \{S, N\}
k∈{S,N}。S和N分别表示语音和噪声分支。
Decoder部分包含三个Gated blocks和一个二维卷积层。重构得到的输出信号为 F D ∈ R T × F × 2 F^D \in \mathbb{R}^{T \times F \times 2} FD∈RT×F×2。如图3(b)所示,门控模块从编码器的响应特征中学习乘法掩码,用于抑制不需要的部分。mask 后的编码器特征与反卷积的特征融合到一起(concatenated),输入另一个二维卷积层中生成残差特征表示。经过三个门控模块后,最终的卷积层学习用于语音重构的幅度增益和相位信息。所有二维反卷积层的卷积核大小为(3, 5),前两个门控模块反卷积层的步长为(1, 2),最后一个为(1, 1)。通道数分别为32, 16, 2。所有二维卷积层的卷积核大小为(1, 1), 步长为(1, 1),通道数与对应的反卷积层通道数相同。
encoder和decoder的所有卷积层后都会进行batch normalization和parametric ReLU(PReLU)。时间维度不进行下采样,从而保持时间分辨率。
3.3 RA Block
RA模块用于提取特征,对语音和噪声分支进行分离。本文采用可分离的自注意力机制(SSA, separable self-attention)捕获沿时间和频率维度的全局依赖性。分别对两个维度使用注意力机制是值得尝试的方法,因为人们倾向于更多地关注音频信号的某些部分(例如语音部分),而较少关注周伟部分(例如噪声),并且语音和噪声在不同频率上的感知也是不同的。在本文提出的SN-Net网络中,语音和噪声分支中的SSA模块对信号的感知不同,本文将在ablation实验中进行测试评估。
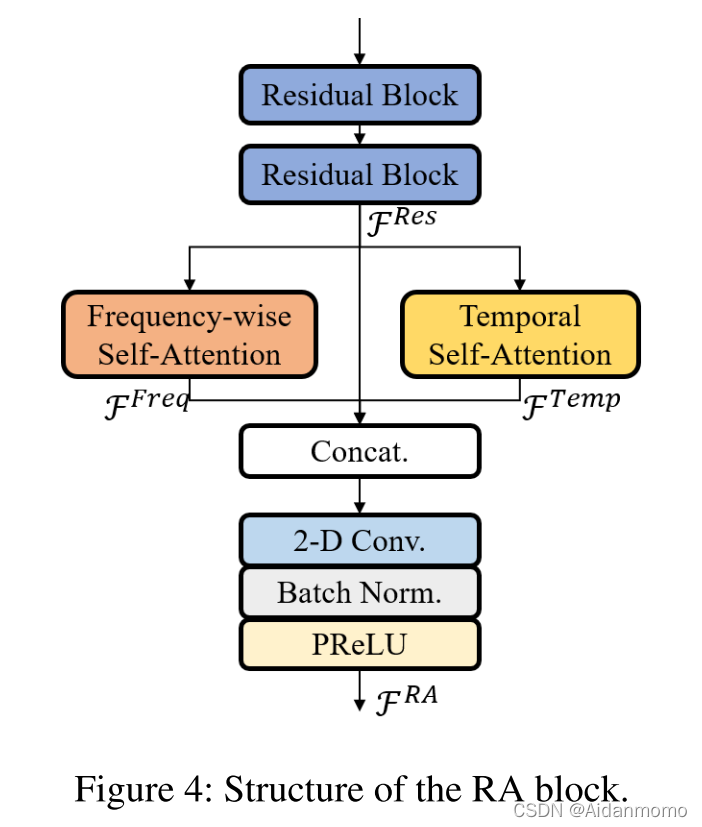
在SN-Net中,encoder和decoder之间包含四个RA模块。每个块包含两个残差块和一个SSA模块,用于信号中的局部和全局依赖性,如图4所示。每个残差块包含两个二维卷积层,卷积核大小为(5, 7),步长(1,1),输出通道数与输入通道相同。两个残差块的输出特征并行输入到时间自注意力块和频率自注意力块中,可以表示为
F
i
R
e
s
∈
R
T
×
F
′
×
C
F^{Res}_i \in \mathbb{R}^{T \times F^{'} \times C}
FiRes∈RT×F′×C,其中
i
∈
{
1
,
2
,
3
,
4
}
i \in \{1,2,3,4\}
i∈{1,2,3,4},
i
t
h
i^{th}
ith表示第i个RA块。两个自注意力块的输出表示为
F
T
e
m
p
,
F
F
r
e
q
∈
R
T
×
F
′
×
C
F^{Temp}, F^{Freq} \in \mathbb{R}^{T \times F^{'} \times C}
FTemp,FFreq∈RT×F′×C。三部分特征
F
R
e
s
,
F
T
e
m
p
,
F
F
r
e
q
F^{Res}, F^{Temp}, F^{Freq}
FRes,FTemp,FFreq融合之后输入到二维卷积层中,得到RA模块的输出
F
R
A
∈
R
T
×
F
′
×
C
F^{RA} \in \mathbb{R}^{T \times F^{'} \times C}
FRA∈RT×F′×C。
本文使用缩放点积自注意力机制。考虑到计算复杂度问题,SSA内部的通道数减少了一半,时间自注意力机制可以表示为:
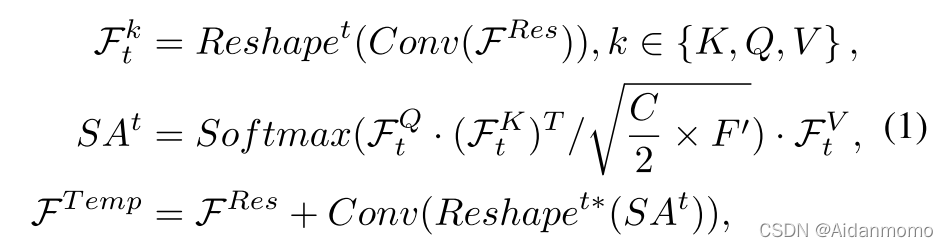
其中
F
t
k
∈
R
T
×
(
C
2
×
F
′
)
F^k_t \in \mathbb{R}^{T \times (\frac{C}{2} \times F^{'})}
Ftk∈RT×(2C×F′) ,
S
A
t
∈
R
T
×
(
C
2
×
F
′
)
SA^t \in \mathbb{R}^{T \times (\frac{C}{2} \times F^{'})}
SAt∈RT×(2C×F′),
F
T
e
m
p
∈
R
T
×
F
′
×
C
F^{Temp} \in \mathbb{R}^{T \times F^{'} \times C}
FTemp∈RT×F′×C。
(
⋅
)
(\cdot)
(⋅)表示矩阵乘法。
R
e
s
h
a
p
e
t
(
⋅
)
Reshape^t(\cdot)
Reshapet(⋅)表示对矢量进行reshape,从
R
T
×
(
F
′
×
C
2
)
\mathbb{R}^{T \times (F^{'} \times \frac{C}{2})}
RT×(F′×2C)到
R
T
×
(
C
2
×
F
′
)
\mathbb{R}^{T \times (\frac{C}{2} \times F^{'})}
RT×(2C×F′),
R
e
s
h
a
p
e
t
∗
(
⋅
)
Reshape^{t*}(\cdot)
Reshapet∗(⋅)表示反向reshape。
频率自注意力机制可以表示为:
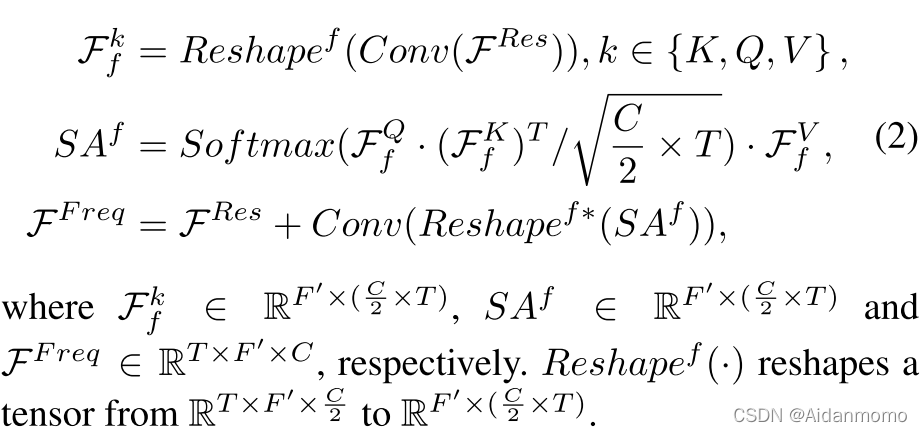
上面的公式中,Conv表示卷积层、BN和PReLU。所有的卷积层核大小为(1,1),步长为(1,1)。
3.4 Interaction Module
在SN-Net中,语音和噪声分支共享相同的输入信号,这就表明两个分支的内部特征存在关联性。因此,本文设计了交互模块用于实现分支之间的信息交换。通过该模块,从噪声分支传输到语音分支的信息用于对语音部分进行增强,并抵消语音分支内的噪声特征,反之亦然。
交互模块的网络结构如图5所示。
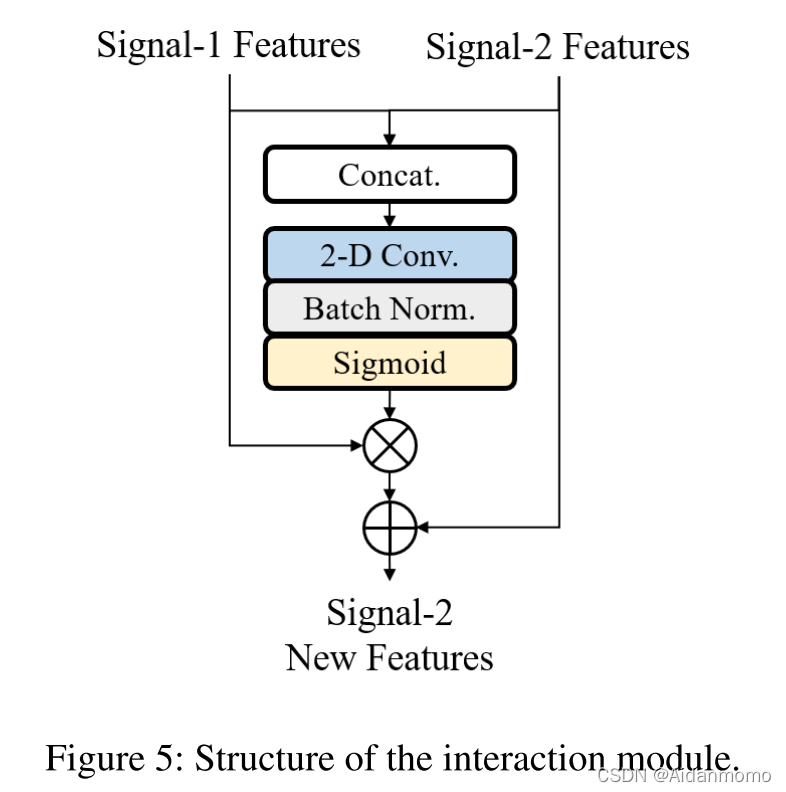
以语音分支为例,来自噪声分支的特征
F
N
R
A
F^{RA}_N
FNRA首先与来自语音分支的特征
F
S
R
A
F^{RA}_S
FSRA进行融合,之后输入到一个二维卷积层中,得到一个乘法掩码
M
N
M^N
MN,用于预测
F
N
R
A
F^{RA}_N
FNRA的抑制和保留区域。通过将
F
N
R
A
F^{RA}_N
FNRA与
M
N
M^N
MN相乘,得到残差表示
H
N
2
S
H^{N2S}
HN2S。最后模块将
F
S
R
A
F^{RA}_S
FSRA与
H
N
2
S
H^{N2S}
HN2S相加得到语音特征经过"过滤"的版本,该特征将会输入到下一个RA模块。
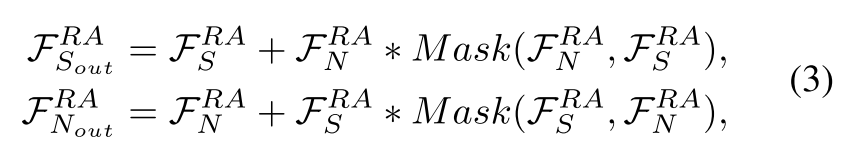
其中
M
a
s
k
(
⋅
)
Mask(\cdot)
Mask(⋅)表示concatenation、卷积和sigmoid操作的缩写。
(
∗
)
(*)
(∗)表示逐像素相乘。
3.5 Merge Branch
通过Merge Branch模块对重建的语音分支和噪声分支的信号进行融合,融合过程在时域内完成。本文使用与STFT相同的窗口长度将两个解码器的输出并转换为时域上,用重叠帧的形式表示为
s
~
∈
R
T
×
K
,
n
~
∈
R
T
×
K
\tilde{s} \in \mathbb{R}^{T \times K}, \tilde{n} \in \mathbb{R}^{T \times K}
s~∈RT×K,n~∈RT×K,其中K表示帧大小。两个分支的输出与带噪语音x同时输入到merge branch模块。融合网络包含一个二维卷积层,一个时序自注意力模块(捕获全局时序依赖性),最后是两个卷积层学习逐元素掩码
m
∈
R
T
×
K
m \in \mathbb{R}^{T \times K}
m∈RT×K。三个卷积层的核大小为(3, 7),通道数为3,3,1。前两个卷积后会进行BN和PReLU操作,最后一个卷积层后使用Sigmoid激活层。最终获得增强后的语音:
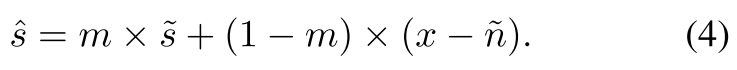
最后通过overlap and add从
s
^
\hat{s}
s^重建一维信号。
4. Experiments
4.1 Datasets
- DNS2020 Challenge数据集:包含2150个说话人的500个小时的干净语音,Audioset和Freesound的包含150个类别的60000条噪声片段。本文合成了500个小时的带噪语音用于训练,信噪比为-5,0,5,10,15dB。合成了150个小时的带噪语音用做验证集,不含混响,信噪比为0到20dB之间的随机数。
- Voice Bank + DEMAND:28个说话人的语音用做训练集,另外两个unseen说话人的语音用做测试集。10个类别的噪声数据用做训练集,五种额外的噪声用做测试集。训练集信噪比:{0,5,15,20},测试集信噪比:{2.5,7.5,12.5,17.5dB}
- TIMIT Corpus:该数据集用于验证语音分离实验。
4.2 Evaluation Metrics
SSNR, SDR, PESQ, CSIG, CBAK, COVL。
4.3 Implementation Details
- 输入:所有喜好重采样为16kHz,小段长度2s,使用复数STFT变换(汉宁窗,窗长20ms,hop_length为10ms,频率点数320)。
- 损失函数: L = L s p e c h + α L N o i s e + β L M e r g e L = L_{spech}+\alpha L_{Noise}+\beta L_{Merge} L=Lspech+αLNoise+βLMerge,分别表示三个分支的损失。所有项都使用幂律压缩(power-law compressed) STFT 频谱上的均方误差 (MSE) 损失【Ephrat et al.2018】。在计算损失之前,对语音和噪声分支进行逆STFT和前向STFT,以确保STFT的一致性【Wisdom et al. 2019】。
- 网络训练:adam 优化器,学习率0.0002,通过Xavier进行初始化。网络模型训练分为两个阶段,首先对两个分支进行训练,损失函数参数设置为 α = 1 , β = 0 \alpha=1, \beta=0 α=1,β=0。然后使用前两个固定的参数训练融合分支,仅仅使用 L M e r g e L_{Merge} LMerge损失函数。batch_size大小为32,DNS数据集训练了60个周期,Voice Bank + DEMAND数据集训练了400个周期。
Ephrat, A.; Mosseri, I.; Lang, O.; Dekel, T.; Wilson, K.; Hassidim, A.; Freeman, W. T.; and Rubinstein, M. 2018. Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation. arXiv preprint arXiv:1804.03619 .
Wisdom, S.; Hershey, J. R.; Wilson, K.; Thorpe, J.; Chinen, M.; Patton, B.; and Saurous, R. A. 2019. Differentiable consistency constraints for improved deep speech enhancement. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 900– 904. IEEE.
4.4 Ablation Study
4.4.1 Objective Quality

首先通过DNS数据集评估网络不通部分的有效性,结果如上图所示。将不含SSA模块的网络模型作为baseline。将SSA模块加入到单分支网络后,模型在SDR和PESQ得分方面都有提升。然后评估了是否使用信息交互模块(interaction)对网络的影响,增加interaction模块对网络模型的性能提升有很大的帮助。
4.4.2 Visualization of information flow

对比a和c能够看出,经过信息交互后,语音区域能够很好的从噪声中分离出来。对于噪声分支,从f中可以看出,语音部分已经从噪声中去除。
4.4.3 Visualization of separable self-attention
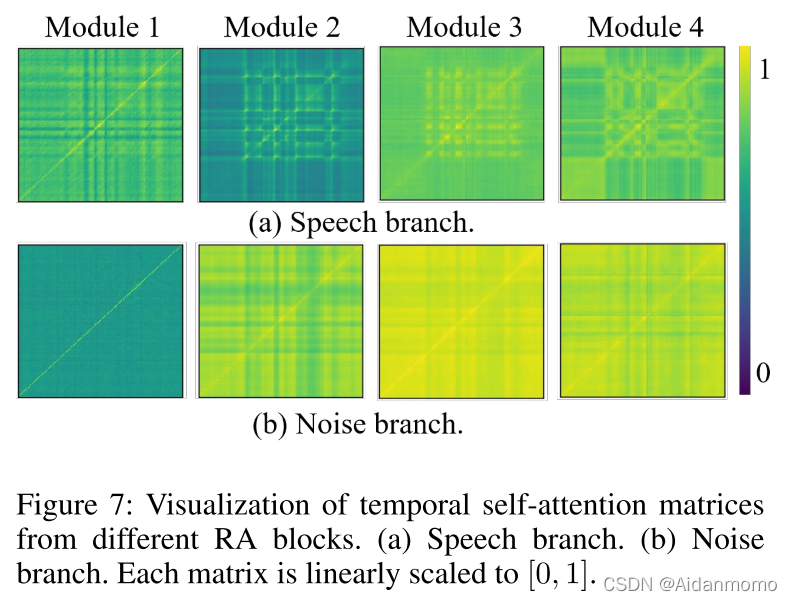
从图7中可以看到,除了对角线之外,每一帧都表现出对其他帧的强烈关注,并且每个RA模块的语音和噪声分支表现不同。对于噪声分支,随着网络的深入,注意力从局部转移到全局。噪声分支比语音分支表现出更广泛的注意力,因为白噪声在所有帧中传播,而语音信号仅在某个时间出现。
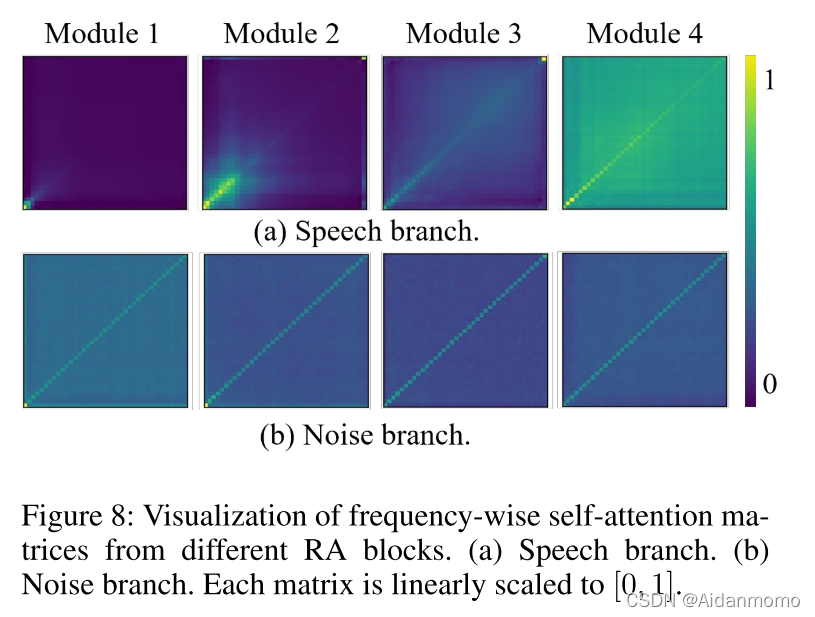
图8给出了频率维度自注意力机制的可视化矩阵图。对于语音分支,注意力从低频部分的局部逐渐扩展到全局频率,表明随着网络的深入,频率方向的自注意力倾向于沿着频率维度捕获全局依赖性。
4.5 Comparison with the state-of-the-art
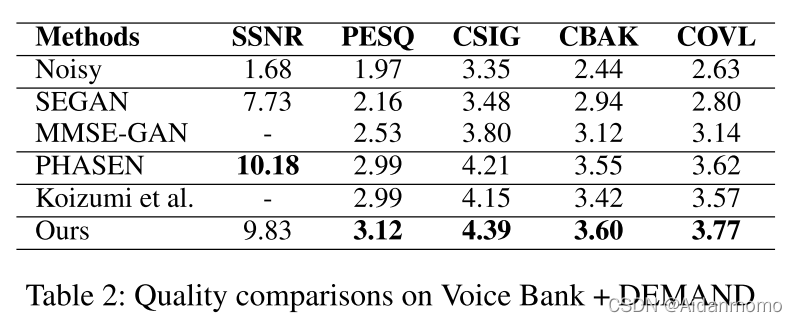
在Voice Bank + DEMAND数据集进行了模型对比验证,实验结果表2所示。

表3比较了不同的模型在DNS2020数据集上的表现。


















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











