




 本文介绍了中国传媒大学和微软亚洲研究院合作的研究成果,提出了一种交互式语音和噪声分离模型,用于提高语音增强效果。通过同时建模语音和噪声并促进两者之间的信息交流,该模型解决了传统方法中语音受损或噪声消除不彻底的问题。实验表明,该模型在语音增强和分离任务上表现出色。
本文介绍了中国传媒大学和微软亚洲研究院合作的研究成果,提出了一种交互式语音和噪声分离模型,用于提高语音增强效果。通过同时建模语音和噪声并促进两者之间的信息交流,该模型解决了传统方法中语音受损或噪声消除不彻底的问题。实验表明,该模型在语音增强和分离任务上表现出色。
声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Interactive Speech and Noise Modeling for Speech Enhancement
该篇文章是中国传媒大学和亚洲微软发表的文章,文章更新于2020.12.14,本文章主要提出了交互式语音和噪声分离模型,实现较好的语音增强效果,另外本文提出的模型也可以应用到语音分离等其他多信号处理的任务,还是非常的有趣,具体的文章链接https://arxiv.org/pdf/2012.09408.pdf
1 背景
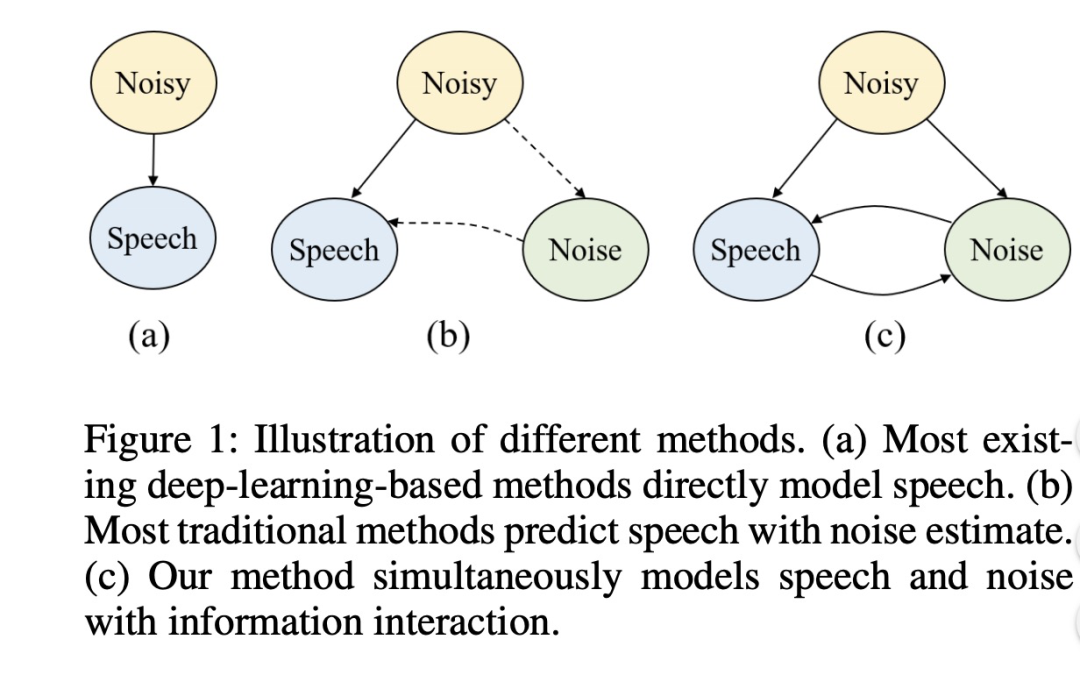
语音增强的工作是在混有噪声的音频中提取出干净的噪声。目前的主要方案如图一中的a和b所示,直接对音频进行建模来获取干净音频,或者对噪声进行建模,然后消除原始音频中的噪声。这两种方案处理的音频都存在一些问题,比如生成的音频部分受损或者噪声消除不干净等等。基于以前的工作,本文提出了同时对speech和noise建模,并且两种信号之间相互交流,使语音和噪声分离更彻底,具体如图一的c。
2 详细的设计
详细的系统如图2所示,speech 和noise的模型结构完全一样都是encoder-RA(residual-convolution-andattention)-decoder模型,只是输入和输出不同。其中为了使speech和noise的信息相互交流,添加了四个RA block和四次信息交换。另外encoder和decoder的网络结构如图3的a和b所示。最后,本文使用的RA结构和信息交
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4711
4711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











