




文章目录

0. 摘要
DCCRN深度复数卷积循环网络在CRN的基础上进行了复数结构的扩展,其在Interspeech DNS2020挑战赛中取得了较好的成绩。本文在DCCRN的基础上进一步改进。
- 对模型进行子带处理扩展,使用可学习的神经网络滤波器代替FIR滤波器进行频带的分割、合并,从而以端到端的方式训练更快的噪声抑制器。
- 使用复数TF-LSTM代替原来的LSTM,更好的对时间和频率维度时序依赖进行建模。
- encoder与decoder之间的skip connection不再是简单的直接合并,而是先经过卷积块对重要信息进行提取,再传递到decoder。
- 增加一个额外的先验SNR估计模块来规范decoder,从而在去除噪声的同时保持语音质量。
- 使用后处理模块对不自然的残留噪声进行处理。
新模型命名为DCCRN+,其在Interspeech2021 DNS challenge中获得了最佳性能。
1. Introduction
最近的一些研究,包括新的 DNS 挑战倡议 [2],指出许多神经噪声抑制器非常擅长抑制噪声,但并没有提高语音质量,甚至引入了明显的语音失真。
Mapping和Masking策略是两种常用的基于深度学习的语音增强方法。mask-based方法逐渐成为主流方法,因为其限制了动态范围,往往能够快速收敛。常见的mask包括IBM【4】, IRM【5】和SMM【4】,上述方法忽略了相位信息。因此,最近的研究开始关注对相位信息进行建模的PSM(phase-sensitive mask)【7】和CRM(complex ratio mask)【8】方法。
本文在DCCRN的基础上,进一步提出DCCRN+模型,目的是在降低噪声干扰的同时,提升语音质量。
1)通过可学习的神经网络滤波器,使模型具备了子带处理能力,这一改进比FIR滤波器在PESQ分数方面提升了0.17,同时保持了与DCCRN相同的PESQ分数。
2)改进skip connection,使用复数TF-LSTM建模时序依赖,额外提升了0.05的PESQ得分。
3)为了提升语音质量,本文使用先验SNR估计模块formulate解码器,进一步提升了0.03的PESQ得分。
4)使用MMSE-LSA后处理的DCCRN+模型在性能上超过了几个最先进的模型,在interspeech DNS2021上获得了最佳性能
2. DCCRN+
2.1 The new design
网络模型如下图所示:
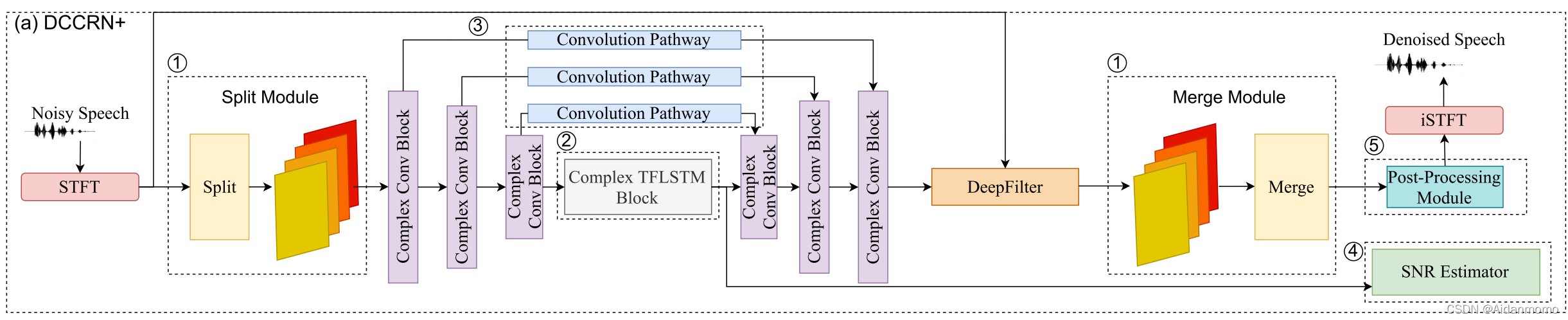
模型的主体结构与DCCRN类似。主要包含以下改动:
- 在encoder之前和decoder之后,分别加入了子带处理分割模块和子带处理合并模块
- 复数TF-LSTM对频率和时间尺度时序依赖进行建模
- skip connection要先经过卷积操作提取重要特征,对应图中的Convolution Pathway
- 加入SNR估计模块
- 后处理模块
2.2 Subband Processing
子带处理是语音处理的常用方法【16-18】,可减少模型大小,节约计算成本。每个频率子带中的音频可以按照因子K(频带数量)进行下采样,从而降低总计算成本。论文 [19] 提到,频谱图中的局部模式在每个频段中通常是不同的:较低频段往往包含高能量、高音调以及长持续时间的声音,而较高频段可能具有较低的能量成分、噪音和快速衰减的声音。子带分割通常使用有限冲击响应滤波器(FIR)实现【20】,很难为不同的应用设计完美的滤波器。论文【21】提出了可学习的神经网络前端,并取得了较好的结果,该方法可以避免对滤波器进行手工设计。
频带分割模块的输入为经过STFT变换后得到的TF频谱,表示为 Y ∈ R T × F Y \in R^{T \times F} Y∈RT×F,其中T表示时间帧数,F表示频点数。本文设计了基于神经网络的分析滤波器 A k ( f k ) A_k(f_k) Ak(fk),用于频带分割,其中 k ∈ 1 , . . . , K k \in 1, ..., K k∈1,...,K表示子带数量。其中 f k ∈ ( F / K ) ⋅ ( k − 1 ) , . . . , ( F / K ) ⋅ k f_k \in (F/K) \cdot (k-1),..., (F/K) \cdot k fk∈(F/K)⋅
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











