





IJCAI-20
0. Abstract
对于单通道语音增强,基于时域的方法和基于时频域的方法各有优劣,本文提出了一种跨域框架,TFT-Net,该模型以时频谱作为输入,以时域波形信号作为输出。该方法利用了我们所掌握的关于频谱的知识,避免了T-F域方法存在的缺点。在TFT-Net中,我们设计了一个双路注意力块(DAB),以充分利用沿时间和频率轴的相关性。本文进一步发现,独立于样本的DAB(SDAB)在提高与语音质量和复杂性之间实现了良好的权衡。消融实验的结果表明,跨域设计和SDAB块对模型性能的提升帮助很大。
1. Introduction
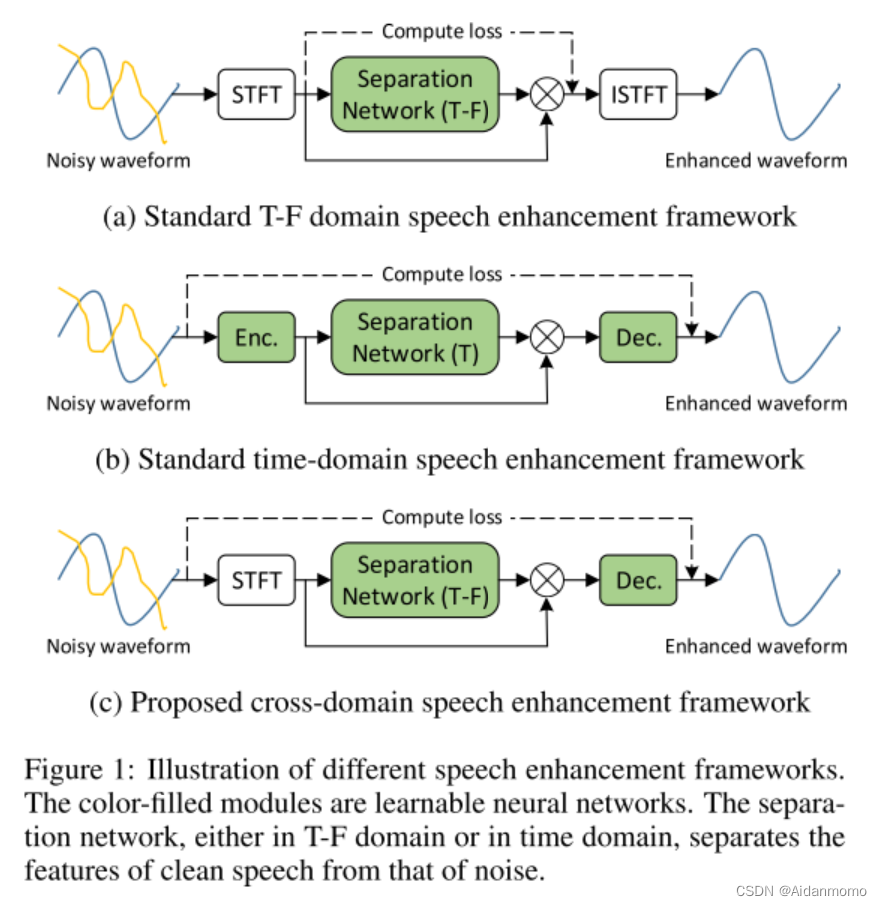
典型的时频域方法如图1(a)所示,网络的输入特征是经过STFT变换后的二维时频谱,网络模型经过训练,预测一个时频掩码,最后通过iSTFT将时频谱变换回时域信号。T-F分析的理论基础是听觉模式,如频率和时间上的接近度,谐波性,以及常见的幅度和频率调制,这些都会在T-F谱图上显示出来。此类方法的局限性:(1)相位的估计问题(2)度量不匹配问题:在有监督的深度学习方法中,计算T-F谱图的MSE损失可能不会令输出语音的SDR最大化。
时域方法的提出是为了解决上述两个问题,典型的模型框架如图1(b)所示。此类方法存在的问题是:时域方法的分离网络部分无法利用到T-F谱图上已知的听觉模式。
本文提出的跨域模型框架如图1(c)所示,在TFT-Net中,时域信号首先经过STFT变换,转换为时频谱,然后利用时频域分离网络学习谱图中的听觉模式,获得谱图掩码后,通过可学习解码器恢复谱图。设计网络模型的过程中,我们发现T-F频谱的长期依赖关系对于提升降噪性能至关重要,为了解决高复杂度的问题,我们提出了双路径注意力快(DAB),并行利用沿时间和频率维度的相关性。We further discover that the attention maps for different samples resemble each other, indicating sample-independent correlation is sufficient. 因此,我们在网络模型中采用了sample-independent DABs(SDABs)来平衡性能和计算成本。
2. Related Work
-
时频域方法:T-F域方法的成功得益于T-F谱图中丰富的听觉模式。作者认为沿着时间轴和频率轴同时学习长距离依赖是有必要的,因为语音中存在谐波,有效的区分噪声需要进行长期的统计。此外,并行的学习两种依赖关系可以更好的融合学习到的特征。
-
时域方法:时域方法的提出是为了解决T-F域方法中存在的问题。虽然诸如Conv-TasNet等网络模型在语音分离任务中取得了较好的结果,但当我们用此类方法解决语音增强问题时,往往无法取得超过T-F域方法的性能。造成这种现象的可能原因是语音和噪声模式在T-F域表示上很容易区分,而基于时域的方法无法利用这种先验知识。
3. The Proposed Scheme
本文设计的网络模型主要瞄准两个目标:
- 充分利用T-F谱的先验知识,因此模型以时频谱特征作为输入,此外通过双路注意力块分别沿时间和频率轴捕获长期依赖关系。
- 模型要克服T-F域方法的缺点,因此模型使用跨域框架,直接利用时域指标监督网络模型训练。
3.1 The TFT-Net Framework
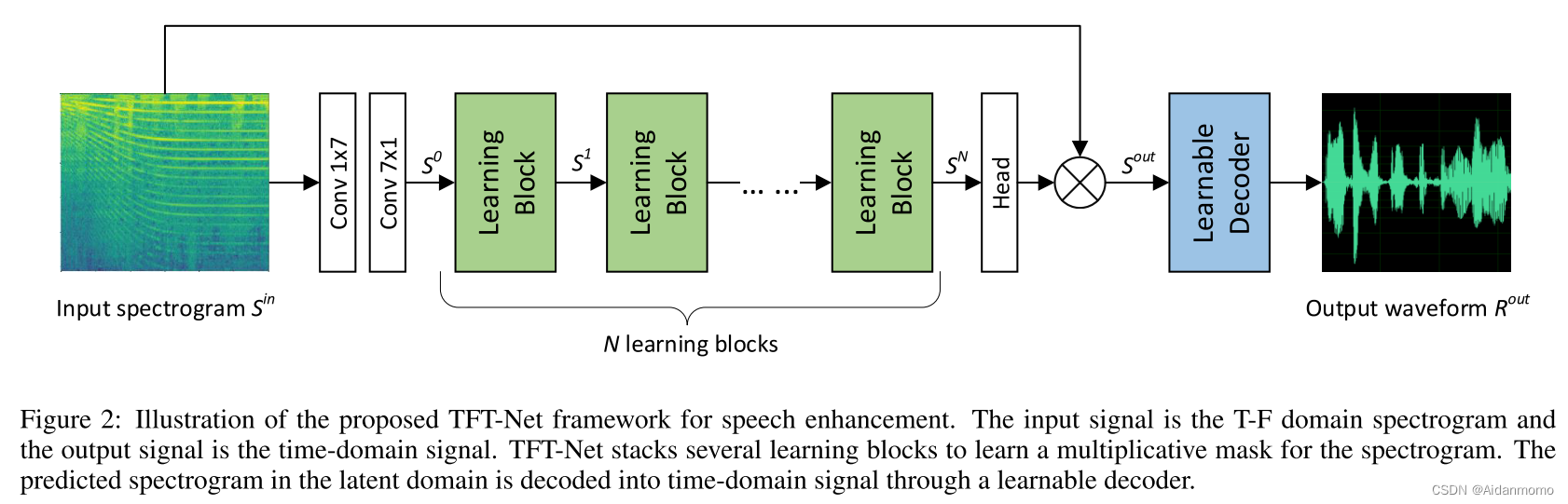
输入特征 S i n ∈ R T × F × 2 S^{in}\in \mathbb{R}^{T \times F \times 2} Sin∈RT×F
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1192
1192




 到【灌水乐园】发言
到【灌水乐园】发言









