




 本文探讨了在低信噪比环境下,利用噪声先验知识进行语音增强的方法。通过门控卷积生成对抗网络(GSEGAN)模型,学习噪声的先验知识以辅助纯净语音的预测。实验在VoiceBankCorpus上进行,对比了传统方法和基于噪声预测的深度神经网络模型在语音增强效果上的差异,表明了噪声预测对于改善低信噪比语音质量的重要性。
本文探讨了在低信噪比环境下,利用噪声先验知识进行语音增强的方法。通过门控卷积生成对抗网络(GSEGAN)模型,学习噪声的先验知识以辅助纯净语音的预测。实验在VoiceBankCorpus上进行,对比了传统方法和基于噪声预测的深度神经网络模型在语音增强效果上的差异,表明了噪声预测对于改善低信噪比语音质量的重要性。
文章目录
仅仅是学习一下思想,不需要重点关注,从实验结果来看,参考意义不大。
1. Noise prior knowledge learning for speech enhancement via gated convolutional generative adversarial network
1.1 摘要
当信噪比很低时,噪声占据主导地位,很难对纯净语音信号进行预测,本文提出了一种利用噪声先验知识的门控卷积神经网络SEGAN(Speech enhancement generative adversarial network),简写为GSEGAN。该模型不仅对纯净语音进行预测,而且学习噪声先验知识来辅助语音增强。门控CNN在捕获长期时序依赖方面具有比常规CNN更大的优势,本文在Voice Bank Corpus上对模型进行了评测。
1.2 语音增强生成对抗网络SEGAN
生成器G从一些已知的先验分布
p
z
(
z
)
p_z(z)
pz(z)中映射噪声向量z,生成伪样本G(z)。判别器用于对真实数据和伪样本记性分辨。生成器的损失函数为:
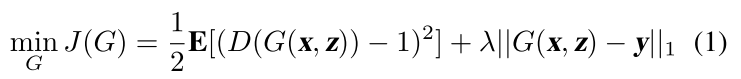
其中z表示服从正态分布N(0,1)的噪声样本,x表示带噪输入语音,y表示目标纯净语音。
1.3 本文提出的方法
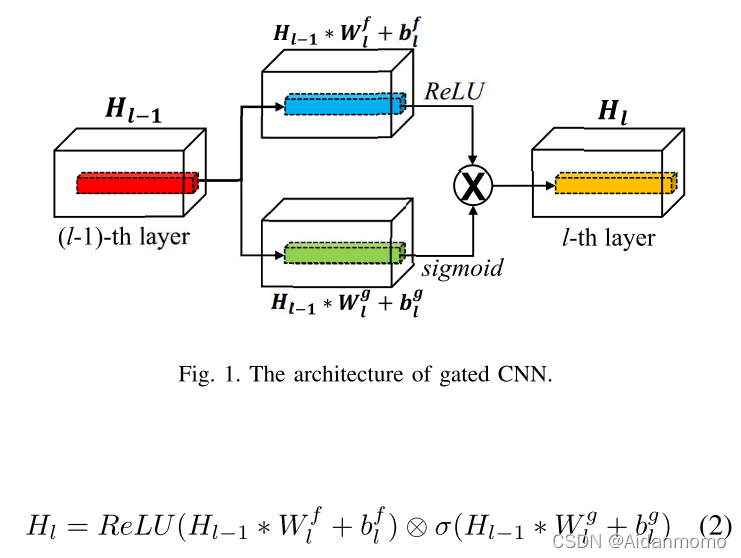
图1所示为门控卷积网络的示意图。
H
l
H_l
Hl表示第l层的输出。W和b表示核函数和偏置,
σ
\sigma
σ表示sigmoid激活,*表示卷积操作,
⊗
\otimes
⊗表示对应元素相乘。
网络模型如图2所示:
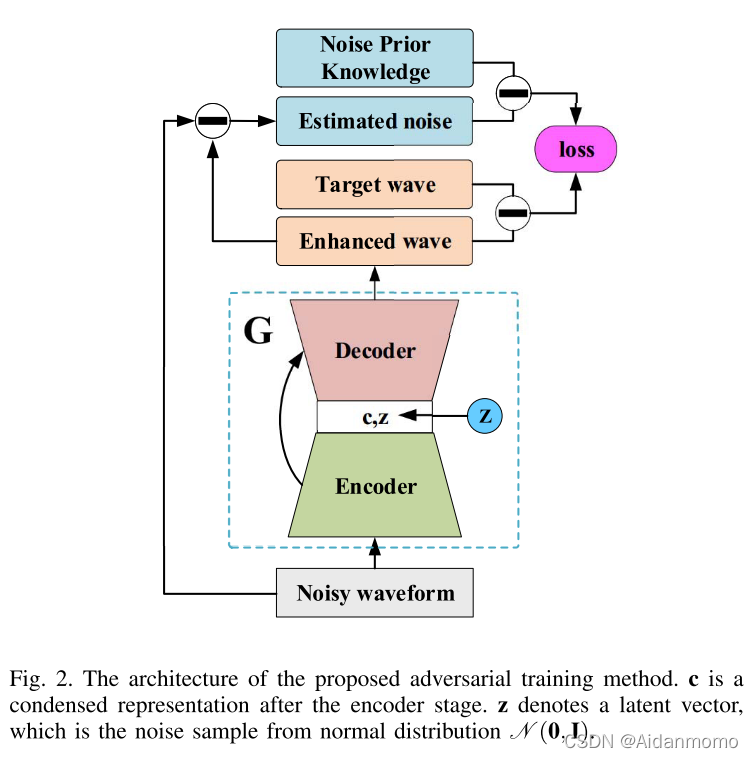
生成器网络为encoder-decoder架构,encoder部分的输入为

y表示纯净信号,n表示噪声信号,encoder的输出表示为:

在decoder阶段,引入新的噪声分量z,模型输出表示为:

z表示潜在向量,是服从正态分布N(0,1)的噪声样本。
先验噪声学习:

因此公式1对应的损失函数可以改写为:
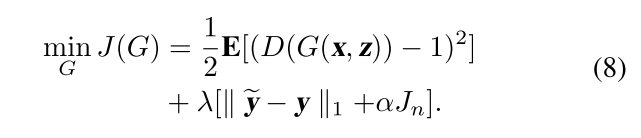
1.4 实验分析
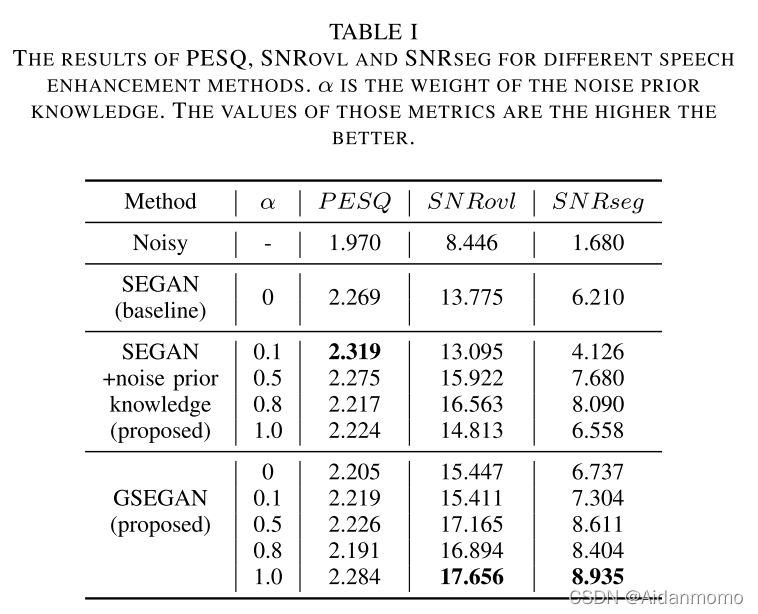
2. A noise prediction and time-domain subtraction approach to deep neural network based speech enhancement
2.1 简介
低信噪比情况下表现较差,本文提出了一种基于噪声预测的深度神经网络语音增强方法。基于噪声预测,提出了三种增强模型,并与传统的谱映射模型在seen和unseen 噪声上进行评测。
本文基于两点分析:
- 低信噪比情况下(信噪比低于0dB),噪声信号的能量占据主导地位,这时,对噪声的估计要比对纯净语音信号的估计更加容易。
- 使用带噪信号相位进行信号重建的问题,低信噪比情况下,带噪语音信号的相位主要受噪声信号影响,
2.2 system overview
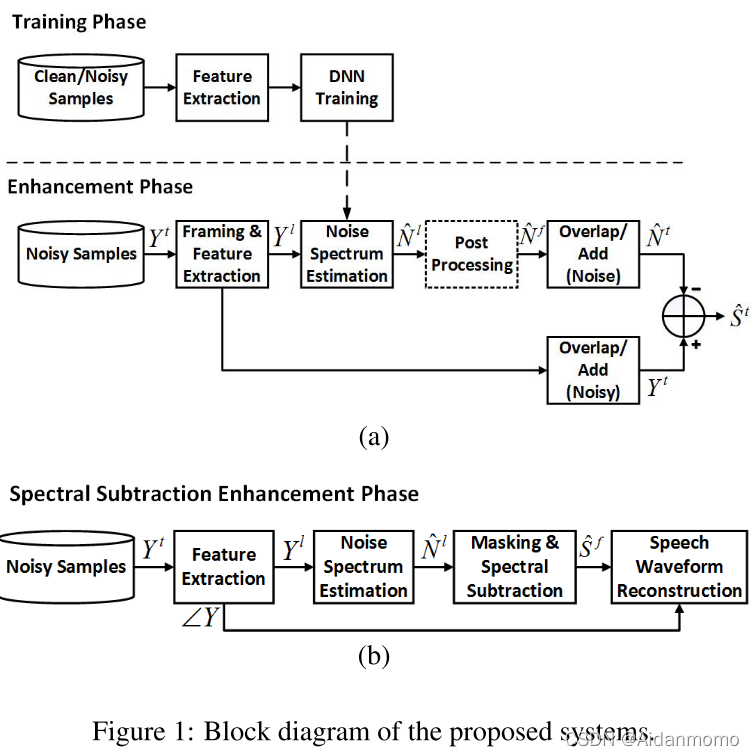
图1所示为本文提出的语音增强方法的框图。展示了噪声预测模型的三种变体,基线模型是时域噪声谱减系统(time domain noise subtraction, TDS),如图1(a)所示。训练阶段,TDS网络的输入为带噪语音信号的对数幅度谱特征,网络学习从带噪信号特征到噪声信号的谱特征之间的映射关系。
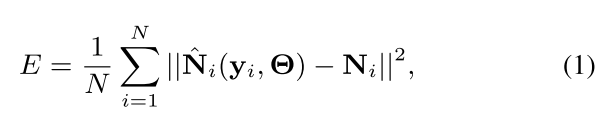
增强阶段,输入数据为带噪语音的对数谱特征,网络预测每帧中添加的噪声的对数谱特征,预测的特征与带噪信号的相位一起重建噪声的时域信号。然后通过带噪信号减去噪声估计,获得语音信号。
第一种变体包含一个mask-based后处理模块,基于掩码处理的系统(MBP)和TDS系统在训练阶段是相同的,但是在增强阶段不同。MBP阶段,噪声谱估计用于计算T-F掩码:
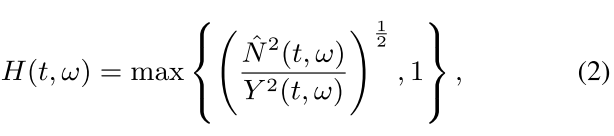
N和Y分别对应噪声和带噪信号的功率谱密度。噪声谱后处理可表示为:
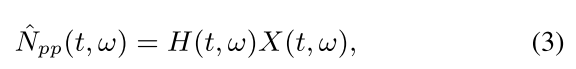
X表示带噪信号的复数谱。通过用带噪信号功率对估计的噪声信号功率进行归一化并强制统一的上限来计算掩码。
第二种变体是如图1(b)所示的谱减系统(SS),SS系统的训练阶段与TDS网络相同,增强阶段使用基于掩码的方法获得噪声谱,然后通过谱减法估计得到无噪的语音谱,最后使用带噪信号的相位和估计得到的语音信号谱恢复得到时域信号。
2.3 实验
传统方法使用的数据的信噪比从20dB到-5dB,间隔5dB。
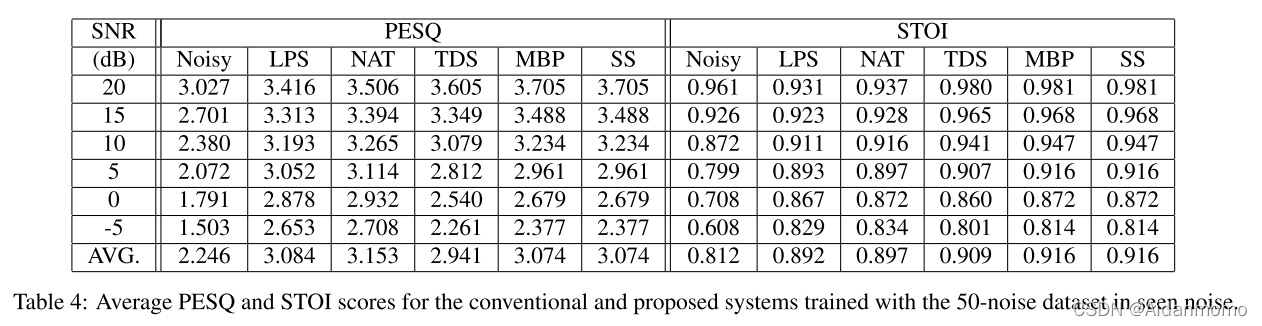
本文方法使用的数据的信噪比从20dB到-10dB,间隔5dB。
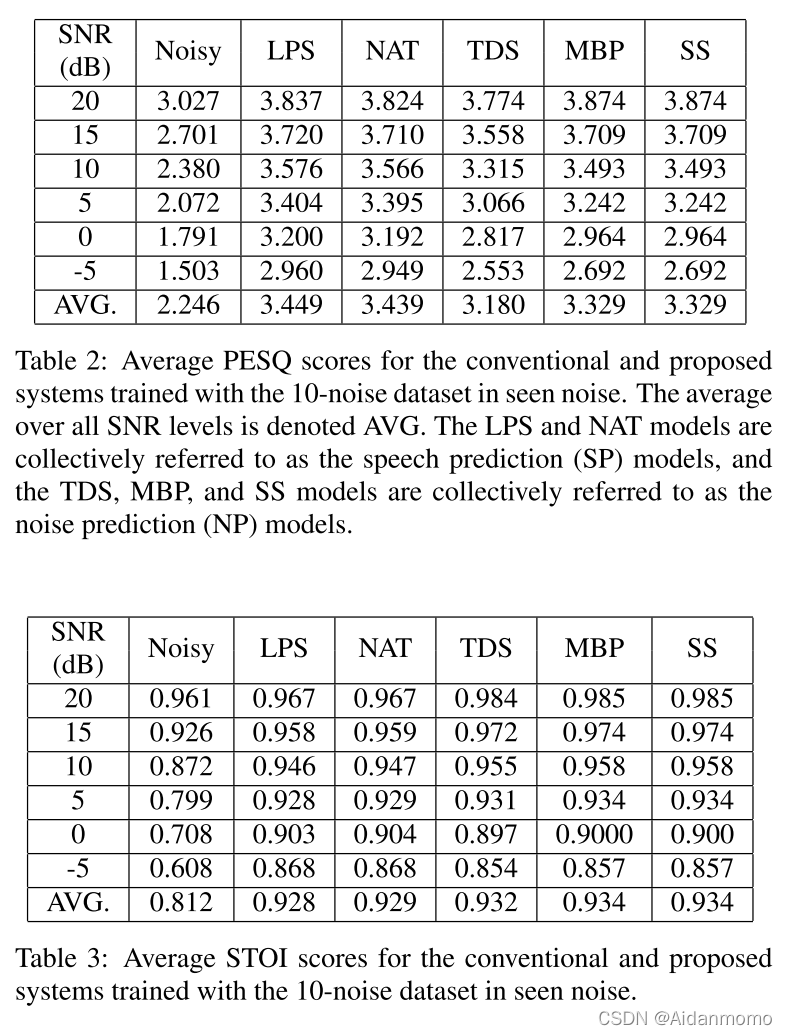
LPS:log-power spectral 传统方法
NAT: noise-aware trained model


















 2313
2313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











