




使用 Agentic RAG 攻克大语言模型 “幻觉” 难题。
微信搜索关注《AI科技论谈》

大语言模型(LLMs)的 “幻觉” 现象,想必很多开发人员都知道。简单来说,就是大语言模型生成的内容存在事实性错误,甚至完全是编造的。这些回答乍一看似乎有理有据,但实际上与现实情况大相径庭,严重影响其应用效果。
为了解决这个难题,我们可以使用“智能体检索增强生成(Agentic RAG)”技术。
一、智能体检索增强生成(Agentic RAG)概述
Agentic RAG 全称是 Agentic Retrieval-Augmented Generation。从名字就能看出专业性,它是一种先进的基于智能体的策略。主要作用是在多个文档间协同工作,实现高效的问答功能。
Agentic RAG 的厉害之处在于,能够协调多个智能体来管理更复杂、更全面的问答任务,从而提升问答的能力和准确性。
主流框架对比
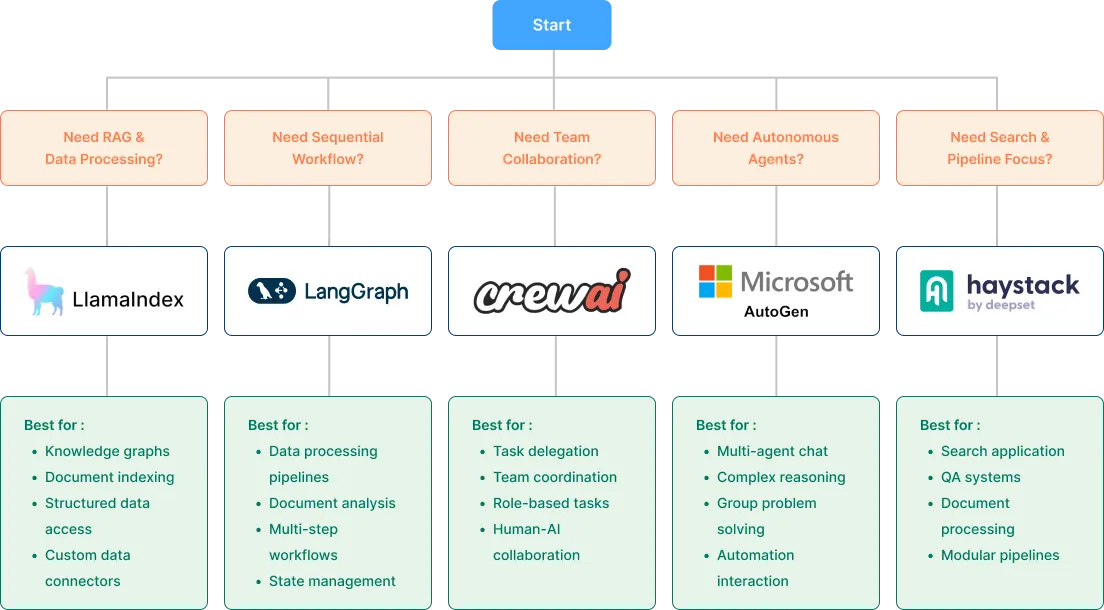
在AI应用开发中,RAG 框架的选择举足轻重,直接关乎应用的性能和开发效率。
不同的 RAG 框架各有千秋,深入了解其优势,是打造高效应用程序的关键所在。
上面的工作流程图展示了如何根据具体项目需求在主流框架之间进行选择。
为了测试Agentic框架的实力,我们用CrewAI和LangGraph框架构建一个药房智能聊天机器人。该机器人能够分析药物数据、提供个性化的用药剂量建议,并帮助用户追踪他们的处方历史。
这个例子旨在展示智能体在医疗保健领域落地实用 AI 应用的潜力,同时也有力证明了Agentic RAG在管理复杂的、多文档问答任务方面的有效性。
二、技术实现
1.使用Neo4j搭建图数据库
构建知识图谱:构建一个强大的知识图谱需要用节点(例如药物、症状)和关系(例如“治疗”、“导致”)来组织数据。
# 设置环境变量
import os
from py2neo import Graph
os.environ['NEO4J_URI'] = '你的Neo4j地址'
os.environ['NEO4J_USERNAME'] = '你的用户名'
os.environ['NEO4J_PASSWORD'] = '你的密码'
graph = Graph(os.environ['NEO4J_URI'], auth=(os.environ['NEO4J_USERNAME'],
os.environ['NEO4J_PASSWORD']))
创建图模式:定义节点和关系,以表示药物、症状、副作用及其相互作用。
QUERY = """
CREATE (a:Medication {name: 'Aspirin', dosage: '500mg'})
CREATE (b:Symptom {name: 'Headache'})
CREATE (c:SideEffect {name: 'Nausea'})
CREATE (a)-[:TREATS]->(b)
CREATE (a)-[:CAUSES]->(c)
"""
graph.run(QUERY)
用例集成:当用户询问阿司匹林如何缓解头痛时,聊天机器人会遍历这个图,根据“治疗”关系提供精确准确的回答。
2.将内存集成到LangChain中
保持上下文对话:LangChain的缓冲区窗口内存会在指定的窗口内跟踪对话历史,使聊天机器人能够参考之前的交互内容。
from langchain.memory import ConversationBufferWindowMemory
from langchain.chains import LLMChain, ConversationalRetrievalChain
from langchain.llms import OpenAI
# 初始化大语言模型
llm = OpenAI(api_key='你的OpenAI API密钥', model='gpt-4')
# 初始化对话缓冲区内存
memory = ConversationBufferWindowMemory(
memory_key="chat_history",
return_messages=True,
k=3
)
解决的问题:保持上下文能够确保聊天机器人有效地处理多轮对话,使交互更加自然,减少误解。
3.在Crew AI框架中使用智能体
专业智能体提升性能:Crew AI允许集成专业智能体,每个智能体专注于特定领域,如药物信息或副作用。
# 定义药物专家智能体
from crewai import Crew, Agent, Task
medication_agent = Agent(
role="药物专家",
goal="仅回答有关药物的查询。",
backstory="你是所有与药物相关事务的专家,包括剂量、副作用、相互作用等。你只应回答与药物具体相关的查询。",
tools=["药物查询工具"], # 定义你的工具
verbose=True
)
# 定义任务
task = Task(
description='处理查询:{query}',
agent=medication_agent,
expected_output='对用户查询的响应'
)
# 初始化Crew
crew = Crew(
agents=[medication_agent],
tasks=[task],
verbose=True
)
# 启动Crew
result = crew.kickoff()
用例示例:当用户询问某种特定药物的副作用时,副作用专家智能体会提供详细准确的回答,确保高质量的信息输出。
4.使用LangGraph实现Agentic RAG
用LangGraph优化工作流程:LangGraph有助于使用智能体构建基于图的工作流程,支持复杂查询处理和迭代改进。
from langgraph.graph import StateGraph
from typing import Sequence
from typing_extensions import TypedDict, Annotated
from langchain_core.messages import BaseMessage
# 定义智能体状态
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], "add_messages"]
# 定义工作流程步骤
def improve_query(state: AgentState):
# 示例:改进用户查询以获得更好的检索效果
user_message = state["messages"][-1][1]
improved_query = llm.predict(f"改进这个查询:{user_message}")
state["messages"].append(("system", improved_query))
return state
def retrieve_documents(state: AgentState):
# 使用改进后的查询检索文档
improved_query = state["messages"][-1][1]
documents = graph.run(f"MATCH (m:Medication)-[:TREATS]->(s:Symptom)
WHERE m.name CONTAINS '{improved_query}' RETURN s.name").data()
state["documents"] = documents
return state
def generate_response(state: AgentState):
# 根据检索到的文档生成响应
documents = state.get("documents", [])
response = llm.predict(f"基于这些文档:{documents},回答用户的查询。")
state["messages"].append(("system", response))
return state
# 构建图
builder = StateGraph(AgentState)
builder.add_node("improve_query", improve_query)
builder.add_node("retrieve_documents", retrieve_documents)
builder.add_node("generate_response", generate_response)
builder.add_edge("START", "improve_query")
builder.add_edge("improve_query", "retrieve_documents")
builder.add_edge("retrieve_documents", "generate_response")
builder.add_edge("generate_response", "END")
# 编译并调用图
compiled_graph = builder.compile()
result = compiled_graph.invoke({
"messages": [
("user", "布洛芬有哪些副作用?")
]
})
print(result)
解决的问题:LangGraph的工作流程管理使聊天机器人能够通过改进用户输入、检索相关文档并生成准确响应来处理复杂查询,同时保持结构化和容错的流程。
三、以用户为中心的优势和影响
前文讲了用Agentic框架构建药房聊天机器人,下面看看这样给各方带来的好处。

多方受益
-
药房老板和管理者:聊天机器人自动化日常咨询,降本增效,客户满意度也提高了。
-
医疗服务提供者:能给患者准确药物信息,还能和现有医疗系统融合,服务更连贯。
-
患者和客户:随时能获得帮助,方便又满意,还能得到个性化回复。
这些先进技术优化了药房与客户的交互。对开发者和药房所有者来说,Neo4j、LangChain、Crew AI和Agentic RAG框架组合,是打造智能药房聊天机器人的好选择。
四、结语
开发这类人工智能智能体,要设计清晰流程、处理边界情况、给用户有用反馈,还要保护用户隐私和安全,做好这些能让智能体更完善。
推荐书单
《LangChain大模型AI应用开发实践》
本书是一本深度探索LangChain框架及其在构建高效AI应用中所扮演角色的权威教程。本书以实战为导向,系统介绍了从LangChain基础到高级应用的全过程,旨在帮助开发者迅速掌握这一强大的工具,解锁人工智能开发的新维度。
本书内容围绕LangChain快速入门、Chain结构构建、大模型接入与优化、提示词工程、高级输出解析技术、数据检索增强(RAG)、知识库处理、智能体(agent)开发及其能力拓展等多个层面展开。通过详实的案例分析与步骤解说,读者可以学会整合如ChatGLM等顶尖大模型,运用ChromaDB进行高效的向量检索,以及设计与实现具有记忆功能和上下文感知能力的AI智能体。此外,书中还介绍了如何利用LangChain提升应用响应速度、修复模型输出错误、自定义输出解析器等实用技巧,为开发者提供了丰富的策略与工具。
本书主要面向AI开发者、数据科学家、机器学习工程师,以及对自然语言处理和人工智能应用感兴趣的中级和高级技术人员。
【5折促销中】购买链接:https://item.jd.com/14848506.html

精彩回顾
大模型应用开发平台Dify推出1.0版本,基于向量数据库Milvus实现RAG
从推理到编程,详细比较DeepSeek 32B、70B、R1实践性能
DeepSeek R1与Qwen大模型,构建Agentic RAG全攻略

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









