




大家好,我是爱酱。本篇将会系统梳理模型泛化(Model Generalization)与正则化(Regularization)的核心原理、主流方法、数学表达、工程实践与未来趋势,配合数学公式,帮助你全面理解这一AI建模的“生命线”机制。
注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、什么是模型泛化?
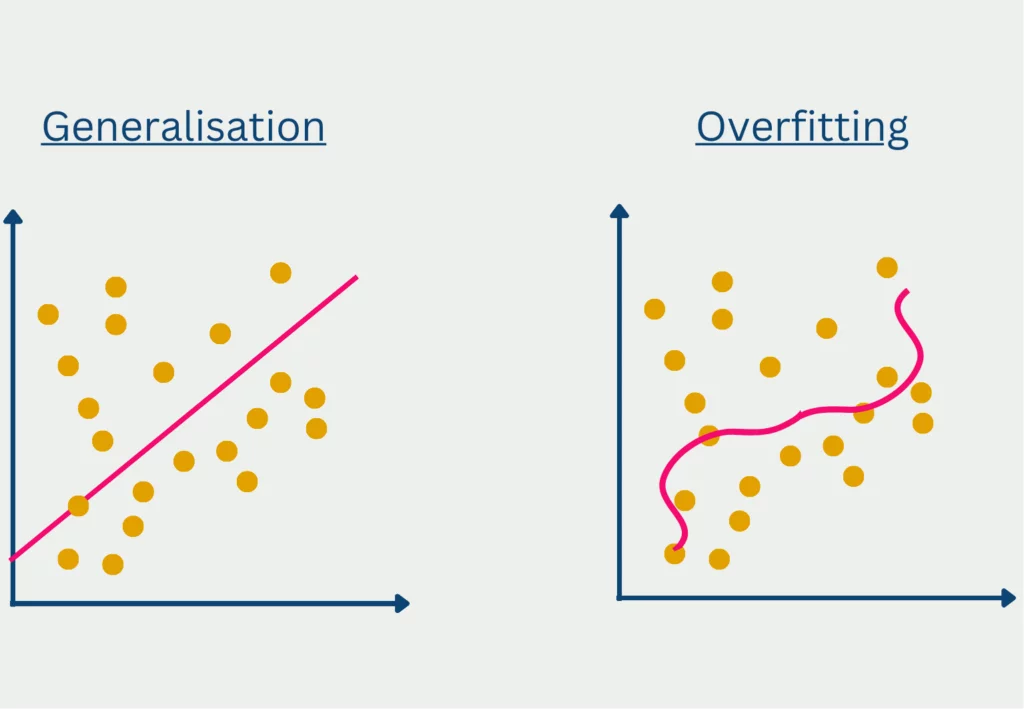
模型泛化(Model Generalization)指机器学习模型在未见过的新数据(unseen data)上依然能保持良好预测能力的能力。泛化能力强的模型不仅能拟合训练集,还能“举一反三”,适应真实世界的多样场景。
-
英文专有名词:Generalization, Generalization Ability
-
本质:模型学到的是“规律”而不是“记忆”,能应对数据分布的自然波动和新环境。
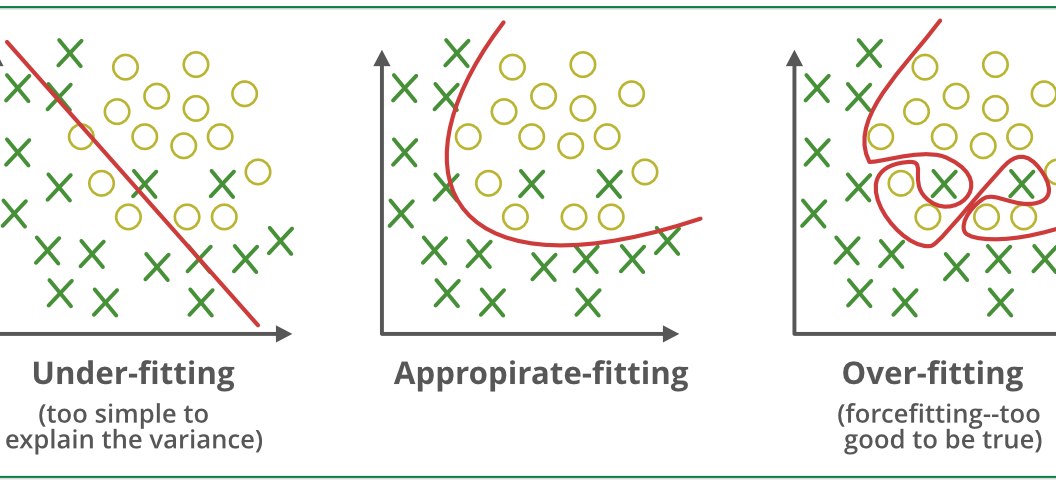
1.1 泛化与过拟合、欠拟合的关系
-
过拟合(Overfitting):模型对训练集“死记硬背”,对新数据表现差。
-
欠拟合(Underfitting):模型太简单,训练集和新数据都表现差。
-
理想状态:模型在训练集和测试集(或验证集)上都表现良好,达到“泛化最佳点”。
二、模型泛化的数学表达
假设模型参数为 ,
训练集损失(Training Loss)为 ,
测试集损失(Testing Loss)为 ,
泛化误差定义为:
泛化能力强的模型应使该误差最小化。
三、影响泛化能力的核心因素
-
模型复杂度(Model Complexity):参数越多、结构越复杂,越容易过拟合。
-
训练数据量与多样性:数据越丰富、越多样,模型越能学到本质规律。
-
特征工程与数据质量:高质量特征有助于泛化,噪声和异常值则会干扰。
-
正则化技术:通过约束模型复杂度,提升泛化能力,是工程落地的关键手段。
四、正则化技术原理与主流方法
正则化(Regularization)是一类通过在损失函数中添加惩罚项(penalty term),抑制模型复杂度、防止过拟合、提升泛化能力的技术。下面只是一个相对简短的介绍,有些概念爱酱有在其他独立文章介绍过,也会附上传送门,欢迎大家去了解更多!
泛化能力详解——传送门:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









